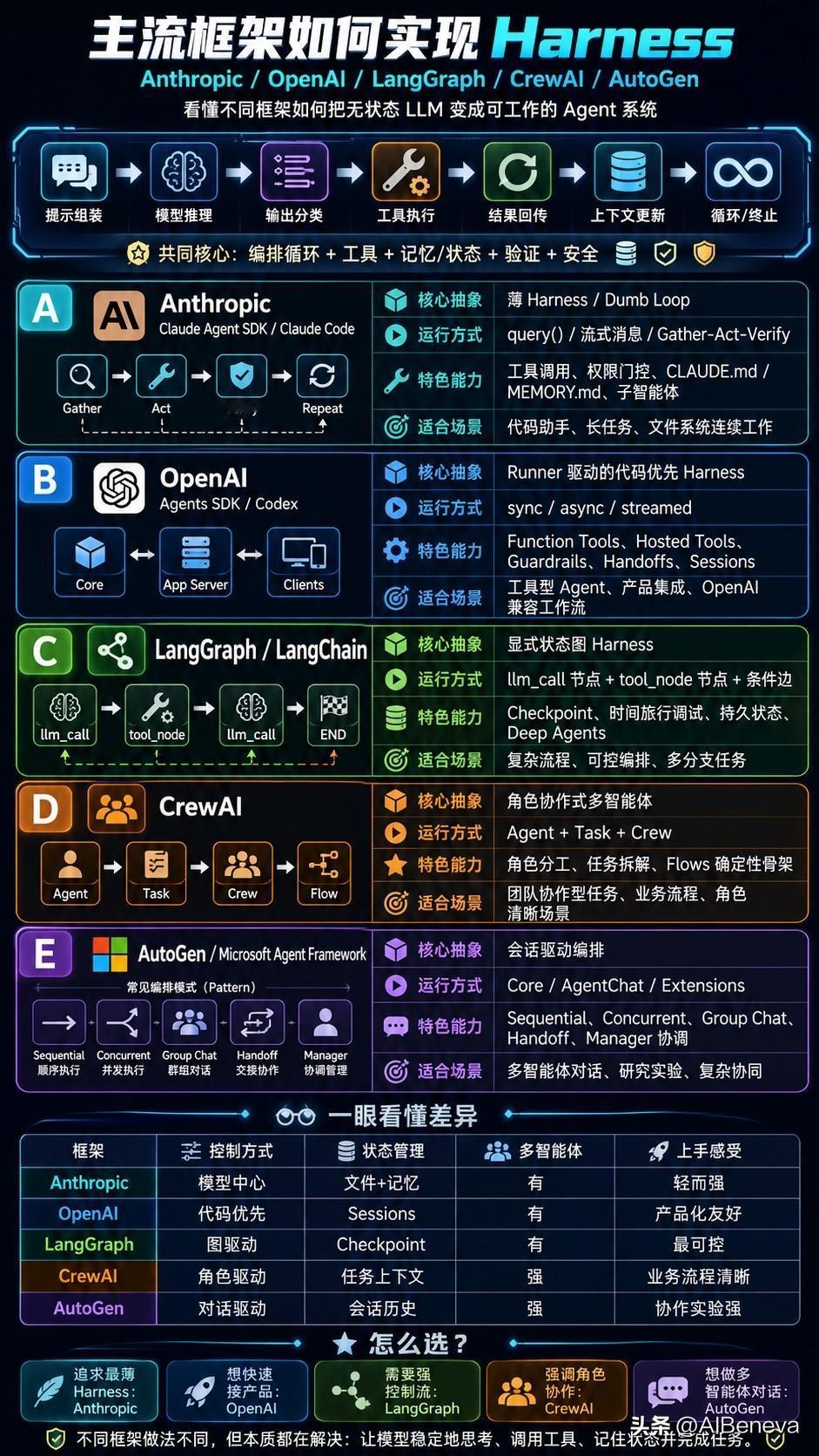
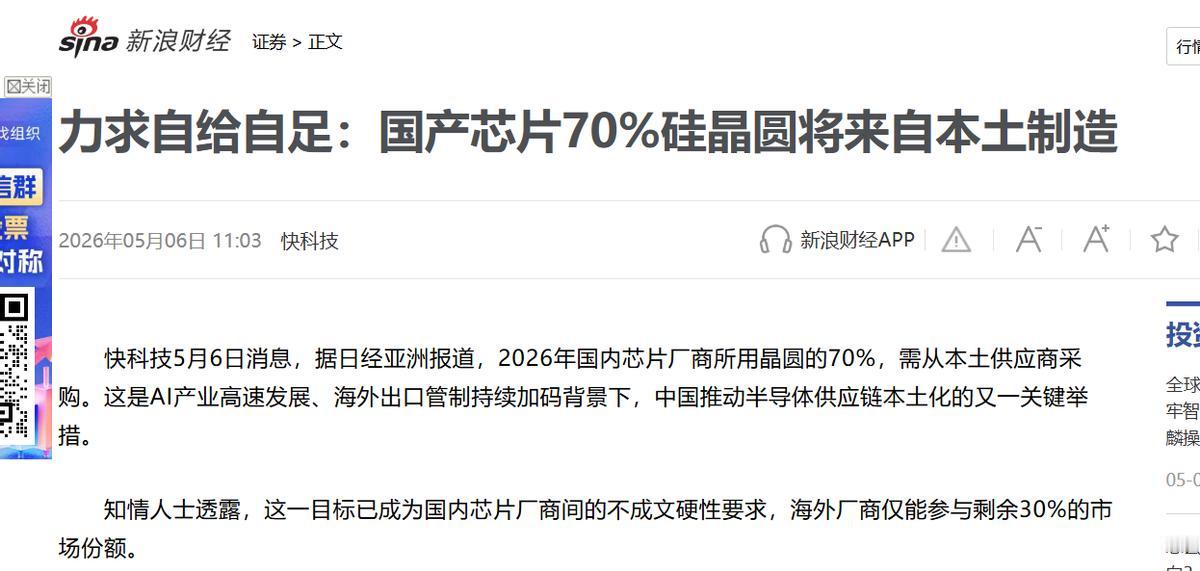
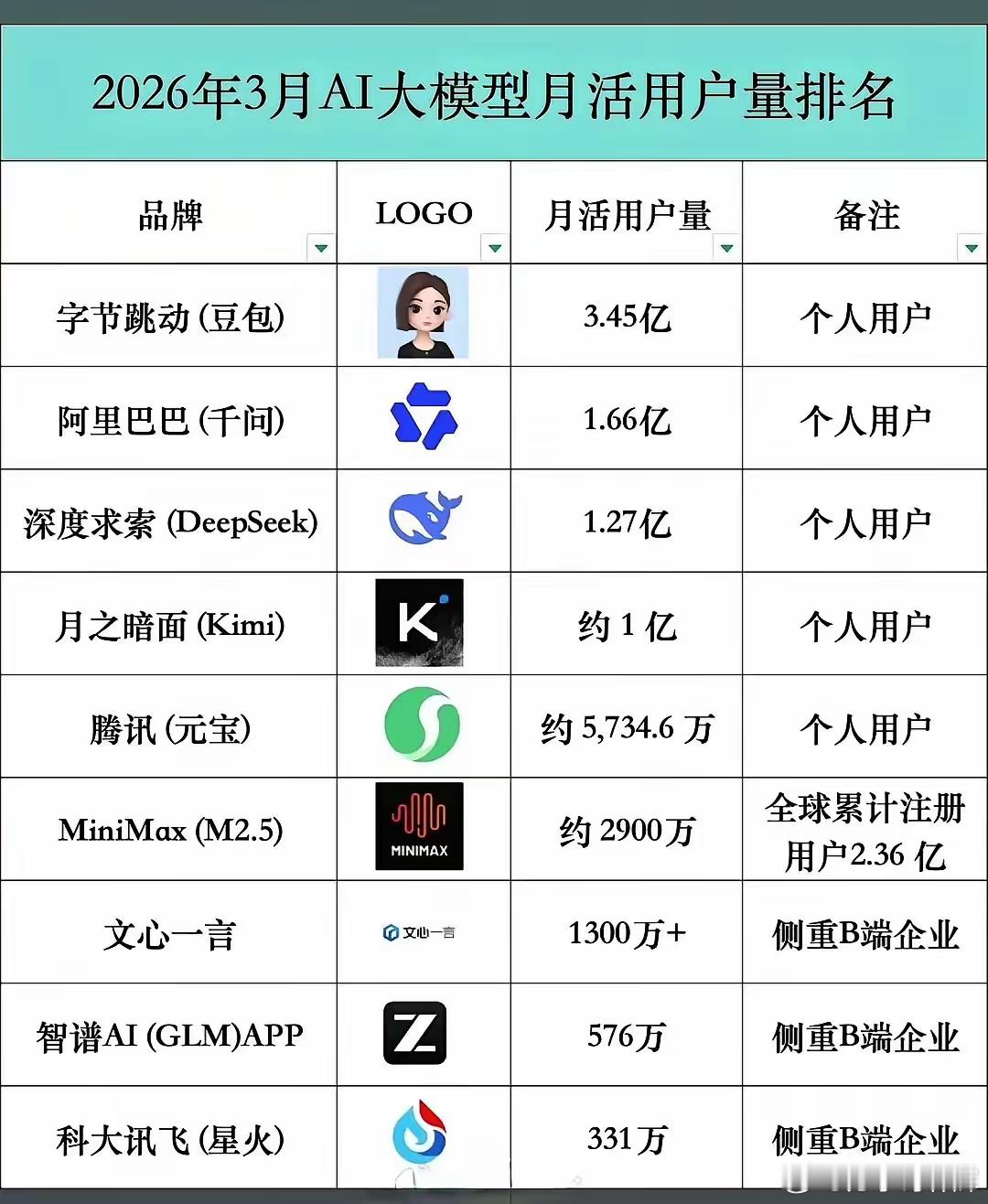
向量检索不是终点 让模型自己找路 才是下一阶段 RAG 的关键变化
RAG 这些年被讲得太顺了,顺到很多人默认一个结论,只要向量做得够好,召回做得够细,答案自然会更准。现实并不完全如此。很多系统的问题根本不在于有没有找到相似内容,而在于找到的内容不具备回答问题的结构性。相似度解决的是像不像,真正的问答往往要求的是有没有用,能不能串起来,能不能支撑推理链。
vectorless RAG 的价值,就在于它把检索从找相似,改成找路径。系统先不把文档当成一堆碎片,而是先把它整理成树。标题是节点,章节是层级,摘要和页码是导航标记。用户提问后,模型先看这棵树,判断该先去哪个大章节,再决定要不要继续往下钻,直到找到最应该被读取的内容。最后才把这些部分交给模型回答。
这一变化听起来像是在绕路,实际上是在回归常识。人读一篇论文,不会把每一段拆开扔进篮子里再做相似匹配。真正有效的做法,是先看结构,再看哪一部分最值得精读。vectorless RAG 模拟的正是这种过程。它的优势非常明确。上下文不容易碎,章节关系不会丢,检索决策可见,日志也更容易调。系统为什么走进某一节,为什么停在某个节点,都能看清楚。
但这套方法绝不是免费午餐。它会增加时延,因为每一步导航都可能触发一次模型调用。它对文档结构也更挑剔,标题抽得差,层级切得乱,整个导航就会变笨。还有一个现实问题,它并不适合那种海量而杂乱的文本池。没有层级可走的时候,再聪明的导航也走不出好结果。
所以真正成熟的判断不是传统 RAG 过时了,而是大家终于开始承认,检索本身也需要推理。向量 RAG 依旧擅长大规模、高效率、低成本的召回。vectorless RAG 更适合结构清晰、需要跨节理解、强调可解释性的任务。前者像快速搜索,后者像带着地图入场。技术方向并没有突然翻盘,但检索这件事,确实已经从匹配问题,开始变成决策问题了。