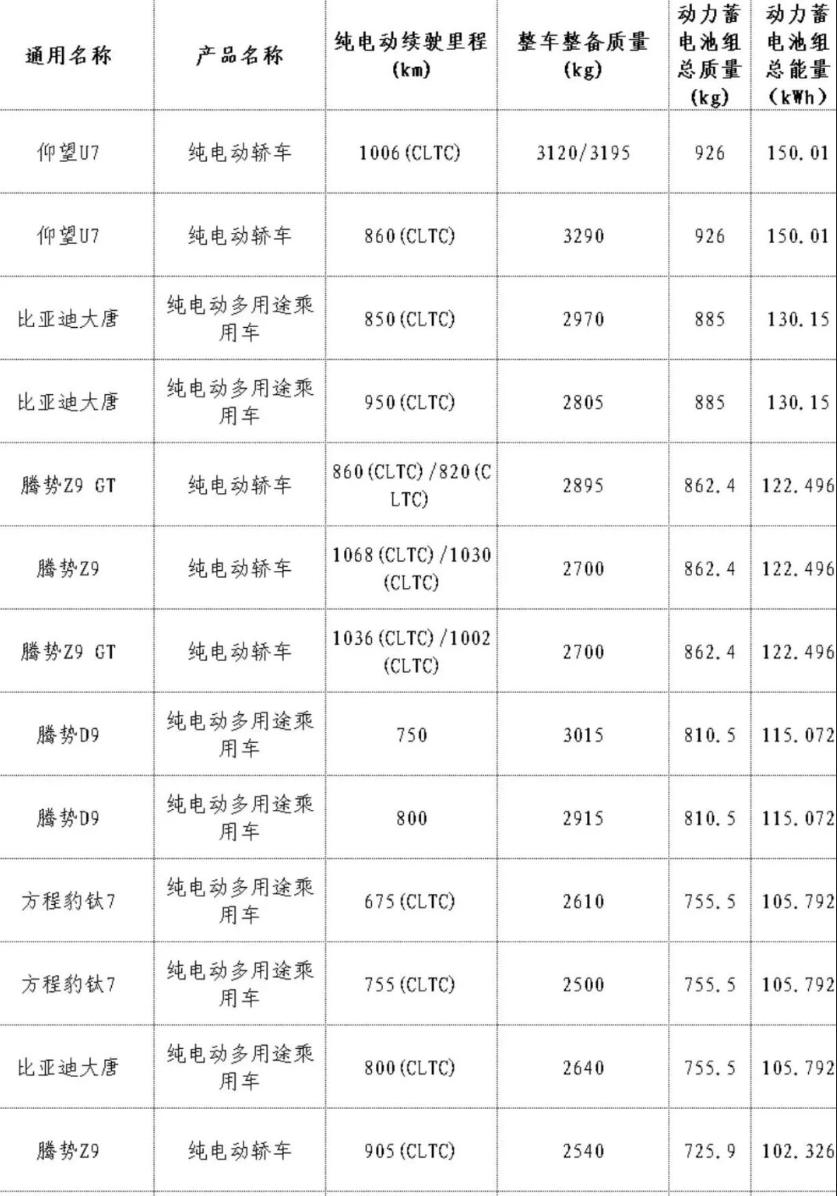
特斯拉手里有张牌经常拿出来秀:84亿英里真实道路数据。 这个数字确实吓人。Waymo靠几千辆测试车跑了十几年,数据量连特斯拉零头都不到。特斯拉的逻辑很清晰,几百万辆普通用户的车每天在路上跑,相当于几百万个免费数据采集员在帮它打工,数据喂给超算,训练出更好的自动驾驶模型,模型好了用户体验提升,车卖得更多,更多的车又采集更多数据,飞轮就这么转起来了。 这套逻辑在早期确实有效。前几十亿英里的数据积累,让FSD从"将将能用"进化到"真的好用",进步是肉眼可见的。高速公路变道、城市主干道跟车、红绿灯识别,这些场景的体验提升非常明显。 但现在这个飞轮的转速正在放缓,而且放缓得很明显。数据从50亿英里涨到84亿英里,用户体验的提升幅度却越来越难感知。道理很简单:好跑的场景早就跑透了。高速公路、城市主干道、晴天直线,这些数据多到溢出来,模型早就训练得差不多了,再喂同类数据,边际收益越来越低。 真正卡脖子的是那些"长尾场景"。暴雨里被积水遮住的路牙、逆光下突然冲出来的行人、没有标线的乡村岔路、凌晨施工现场临时改道的锥桶阵。这些场景在84亿英里里占比极低,但它们才是自动驾驶真正过不去的坎。数量再多的普通数据,也填不上这个质量上的缺口。 对中国用户来说,这个问题更直接。国内的路况复杂程度远超美国,电动车、外卖骑手、行人混行,加上各地道路标准不统一,特斯拉在美国积累的数据,在国内的适配效果打了相当大的折扣。更别说中国的数据安全法规明确限制数据出境,特斯拉在国内采集的数据不能直接传回美国超算,这意味着国内用户的驾驶数据无法完整融入全球训练体系,飞轮在中国市场转得更慢。 还有一个容易被忽略的问题:数据的价值不只看数量,还看标注质量。几百万辆用户车采集的是原始行驶数据,要转化成有效训练样本,需要大量人工标注和筛选。这部分的成本和效率,才是数据飞轮真正的瓶颈,而不是英里数本身。