
英文题目:Online Approach to Near Time-Optimal Task-Space Trajectory Planning
中文题目:面向近时间最优任务空间轨迹规划的在线方法
作者:Antun Skuric, Nicolas Torres Alberto, Lucas Joseph, Vincent Padois, David Daney
作者单位:AUCTUS Team, Inria, France
期刊:IEEE Transactions on Robotics
发表时间:2026年1月16日
引文格式:Skuric A., Torres Alberto N., Joseph L., Padois V., and Daney D., Online Approach to Near Time-Optimal Task-Space Trajectory Planning, IEEE Transactions on Robotics, vol. 42, pp. 637–652, 2026.
01 全文速览
协作机器人常被用于人机共融环境,因此安全标准往往限制了其速度、加速度和工作能力。但从实际应用看,协作机器人本身体型小、负载有限,如果运动能力不能被充分利用,很多工业任务就会变得效率不足。本文要解决的问题很直接:如何在动态环境中,让协作机器人不依赖大量离线预计算,也能尽可能接近时间最优地运动?
传统方法大致有两类。第一类是在关节空间做时间最优轨迹规划,例如TOPP-RA,能够充分利用机器人关节能力,但通常需要预先把任务空间路径转成关节空间路径,计算成本较高。第二类是在任务空间直接规划,速度快、便于在线更新,但常假设笛卡尔空间速度、加速度上限是固定的,容易低估或高估机器人真实能力。
本文提出一种折中但很实用的方案:在任务空间在线规划,同时实时计算机器人当前构型下的真实运动能力,并用TAP轨迹规划不断更新剩余路径。
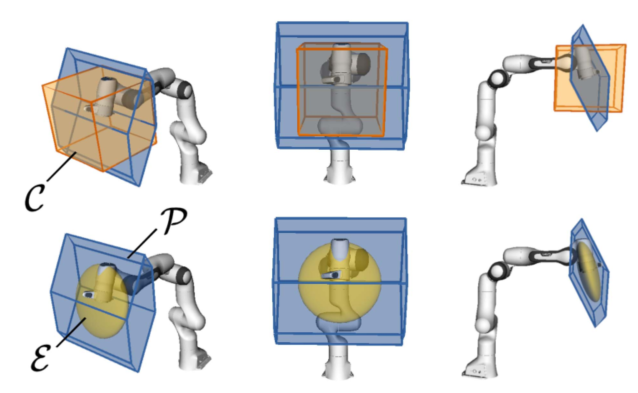
图1:固定笛卡尔速度限制、操纵性椭球和真实速度能力多面体的对比。
✅ 亮点1:在任务空间直接规划,无需提前完整求解关节空间路径。
✅ 亮点2:用多面体代数实时评估机器人在路径方向上的速度、加速度和jerk能力。
✅ 亮点3:每个控制周期基于剩余路径重新计算TAP,实现在线近时间最优。
✅ 亮点4:相比传统任务空间规划,可达到更高速度并保持4 mm以内跟踪误差。
02 研究内容
🎯 2.1 问题本质:机器人能力不是固定的
机器人关节空间的速度、加速度、jerk限制通常由厂家给定,可以认为相对固定。但一旦映射到任务空间,末端在不同方向上的运动能力会随构型变化。也就是说,机器人在某个姿态下向左移动可能很快,向上移动却可能接近能力边界。
传统任务空间规划常使用固定笛卡尔限幅,这会带来两个问题:
一是过于保守,机器人明明还能跑更快,却被人为限速;二是过于激进,规划出的轨迹超过机器人真实能力,导致跟踪误差增大。
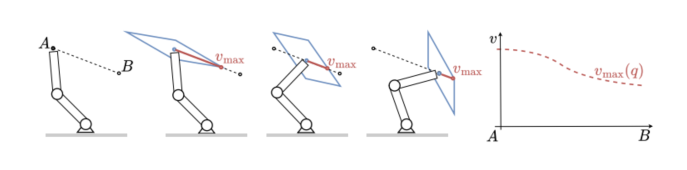
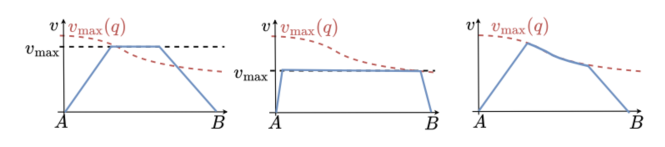
图2:上图展示沿直线路径运动时,机器人任务空间速度能力随构型变化;下图展示固定限幅可能导致能力高估或低估,而真正合理的策略应跟随能力变化进行规划。
🧠 2.2 核心思想:每一步都重新看一眼机器人还能跑多快
本文方法可以概括为一句话:
在每个轨迹执行时刻,先计算机器人当前沿路径方向的运动能力,再对剩余路径重新生成近时间最优TAP轨迹。
机器人关节速度、加速度、jerk到任务空间的映射为:
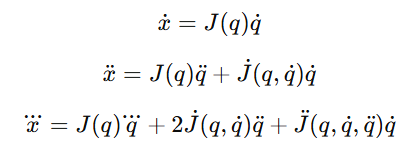
这些约束在任务空间中形成凸多面体。作者并不直接处理完整多面体,而是将其投影到当前路径方向,只求解沿这条路径最多能有多大速度、加速度和jerk。这样可以显著降低计算量。
⚙️ 2.3 多面体能力评估:把高维约束压到路径方向
设路径方向单位向量为 (c),任意任务空间运动变量 (y) 在路径方向上的投影为:
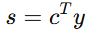
为了保证运动变量严格沿路径方向,还需要其正交分量为零:
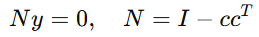
于是,路径方向上的最大能力可以通过线性规划求得:
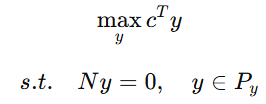
这里
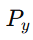
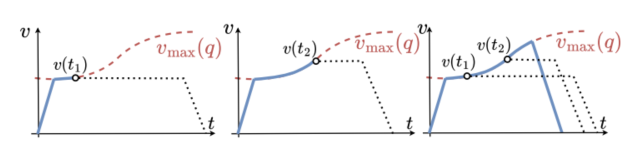

图3:图展示在线更新速度能力后,轨迹时间不断缩短的直观过程;Algorithm 1可改绘成状态测量—能力计算—剩余路径TAP—输出期望位姿/速度/加速度的流程图。
🚀 2.4 在线TAP规划:不是一次算完,而是边走边改
TAP,即Trapezoidal Acceleration Profile,常用于生成时间最优或近时间最优轨迹。本文将任务空间直线运动分为平移部分和旋转部分,分别对路径变量 (s_t) 和 (s_r) 做规划,再通过时间同步使机器人同时到达目标位置和目标姿态。
关键在于,本文并不假设速度、加速度、jerk限制在整条路径上固定,而是在每个时刻根据机器人当前状态重新估计这些限制,并对剩余路径重新规划。这种方式有点类似简化版MPC:每次都规划到终点,但实际只执行下一小步,随后再用最新状态更新规划。
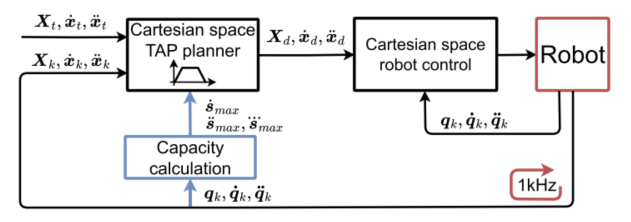
图4:方法嵌入实时机器人控制框架的结构图。蓝色部分是本文相对传统任务空间TAP规划增加的能力计算模块。
🛠️ 2.5 两个工程细节:超调与抖振
在线重规划也会带来副作用。第一是制动能力下降导致超调。如果机器人接近终点时突然制动能力变弱,而规划器之前假设制动能力不变,就可能刹不住,越过目标。作者用一种保守补偿策略估计当前与终点处较差的制动能力,使平均超调从约3 mm降至约0.1 mm。
第二是制动能力增加导致抖振。如果机器人后续制动能力逐渐变强,规划器可能反复在加速—减速之间切换,引起加速度和jerk抖动。作者采用降低TAP重规划频率的方法进行平滑,最终选择约10 ms的规划步长,在降低jerk波动和保持跟踪精度之间取得平衡。
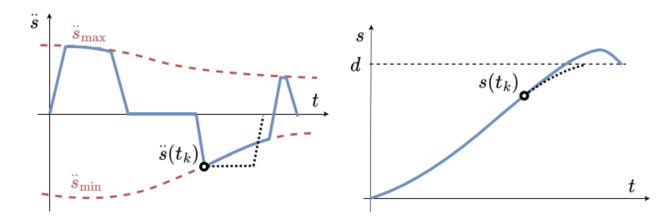
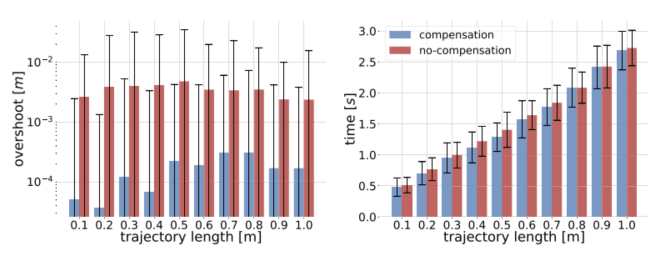
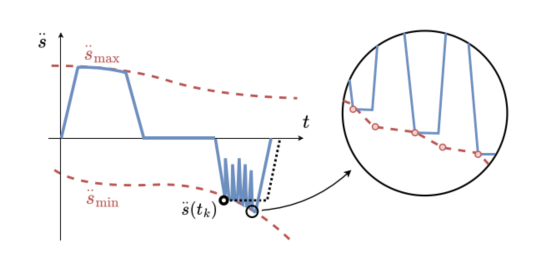
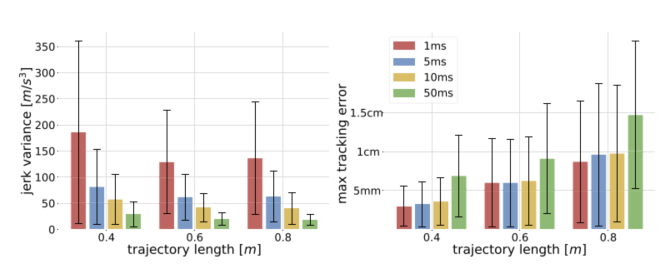
图5:这一组图适合集中放在工程补偿机制部分,展示超调补偿、抖振形成原因以及不同重规划步长的影响。
📊 2.6 实验结果:接近TOPP-RA,但更适合在线场景
实验在Franka Emika Panda机器人上完成。作者将本文方法与TOPP-RA进行比较。TOPP-RA是经典关节空间时间最优路径参数化方法,但它需要先将任务空间路径离散成路点,再求解对应关节空间路径,因此计算代价较高。
结果显示,本文方法生成的轨迹平均只比TOPP-RA慢约5%,在不同长度路径上大约慢2%到7%,表现出较好的近时间最优特性。与此同时,TOPP-RA的计算时间从短路径约50 ms增长到长路径超过0.5 s,而本文方法可以在线实时运行,不依赖完整路径预计算。
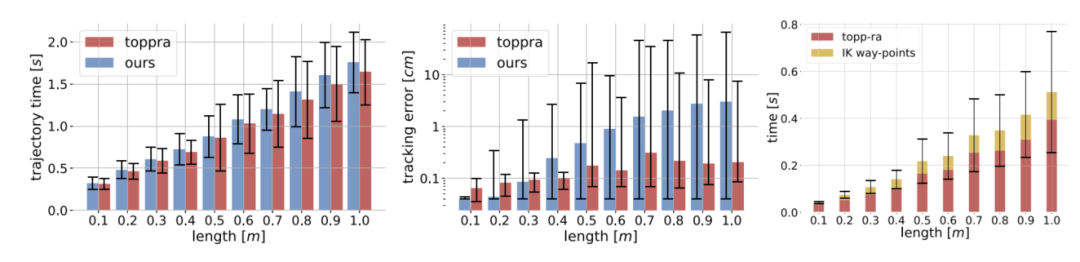
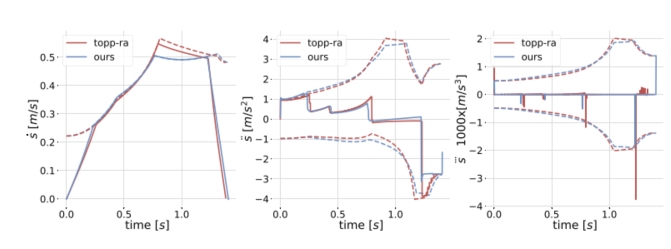
图6:上图展示本文方法与TOPP-RA在执行时间、跟踪误差和计算时间上的对比;下图展示速度、加速度和jerk曲线,能直观看出两者轨迹形态接近。
03 创新点
🔍 3.1 从固定笛卡尔限制转向构型相关能力感知
本文最重要的启发是:任务空间规划不能只看厂家给出的固定笛卡尔限制,而要考虑机器人在当前构型下沿目标方向的真实能力。
⚙️ 3.2 用线性规划高效求解路径方向能力
作者没有直接处理复杂高维多面体,而是将速度、加速度和jerk能力投影到路径方向,通过线性规划得到可用范围,兼顾了准确性和实时性。
🚀 3.3 在线重规划避免大量离线预计算
相比TOPP-RA等离线最优方法,本文不需要提前固定完整关节空间路径,更适合动态环境、目标更新和人机协作场景。
🤖 3.4 真实任务验证具有工程说服力
论文通过协作废物分类mock-up实验验证方法。机器人需要实时识别未知位置和姿态的物体与分类箱,并快速执行抓取、搬运和放置,说明该方法并非只停留在仿真轨迹层面。
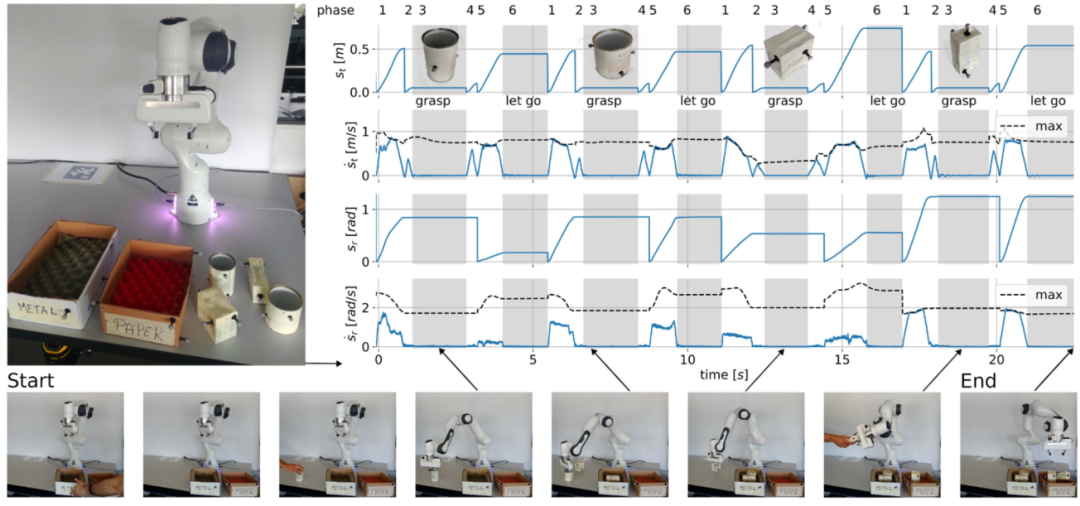
图7:协作废物分类实验平台。
04 总结与展望
这篇论文的价值不在于提出一个更复杂的优化器,而在于提出了一种很工程化的轨迹规划观念:既不要像传统任务空间规划那样粗略限幅,也不要完全依赖离线关节空间最优规划,而是在执行过程中实时感知机器人能力,并持续更新剩余轨迹。
当然,该方法仍有边界。它主要针对任务空间直线段轨迹,复杂路径需要分段近似;接近奇异位形时,机器人某些方向的运动能力可能急剧下降,仍需要底层控制器配合奇异规避;此外,TAP本身对约束变化的表达能力有限,未来可考虑与更灵活的动态滤波器、MPC或安全约束控制结合。
🔭 未来研究可关注:
1. 面向复杂曲线路径和多段路径的连续能力感知规划;
2. 与奇异规避、避障和冗余自由度优化更深层融合;
3. 将能力感知轨迹规划与人机协作安全标准结合;
4. 扩展到力控、接触操作和移动操作机器人;
5. 与MPC、控制屏障函数等方法结合,提升动态环境安全性。
协作机器人未来要真正进入高效工业现场,是更需要更强的硬件,还是更需要更懂自身能力的轨迹规划算法?
声明:本文仅供学术交流,版权归原作者所有。如有错误或侵权,请联系更正或删除,欢迎留言探讨。