国家队领投DeepSeek首轮融资中国开源大模型击败美国大模型已经能看到机会了
DeepSeek V4这次更新,技术上似乎让美国松了口气,性能与美国头部闭源大模型还有差距。
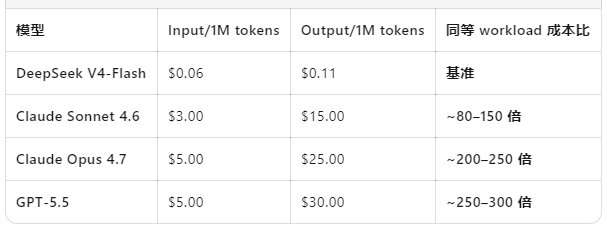
但是,行业人士知道厉害。V4的性能提升非常大,大约能到GPT 5.0的水平。而且用的是极为有限的训练资源,优化做得很好,API价格只有美国头部模型的百分之一甚至更低。
这给美国大模型立了一个“下限”,如果被DeepSsek、Kimi、GLM等中国开源模型赶上性能,那价值就归零了。这其实就是中国制造业击败西方世界的绝招,技术突破后将西方高成本技术的价值归零。
而大基金入股的意义在于,中国开源大模型技术路线得到了国家认可!在经济意义上也可以跑通了。
这不是说开源大模型能卖token赚到足够的钱来覆盖研发运营,不需要。只要随便做点营收,就可以上市。例如港股的智谱和Minimax,年化收入就是10-20亿人民币,市值4100亿、2500亿港元。DeepSeek无论是在港股还是A股上市,都会受到热烈追捧,技术实力和品牌价值就值好几百亿美元。这条估值路线已经跑通,认这个的资金很多,不需要太多营收。
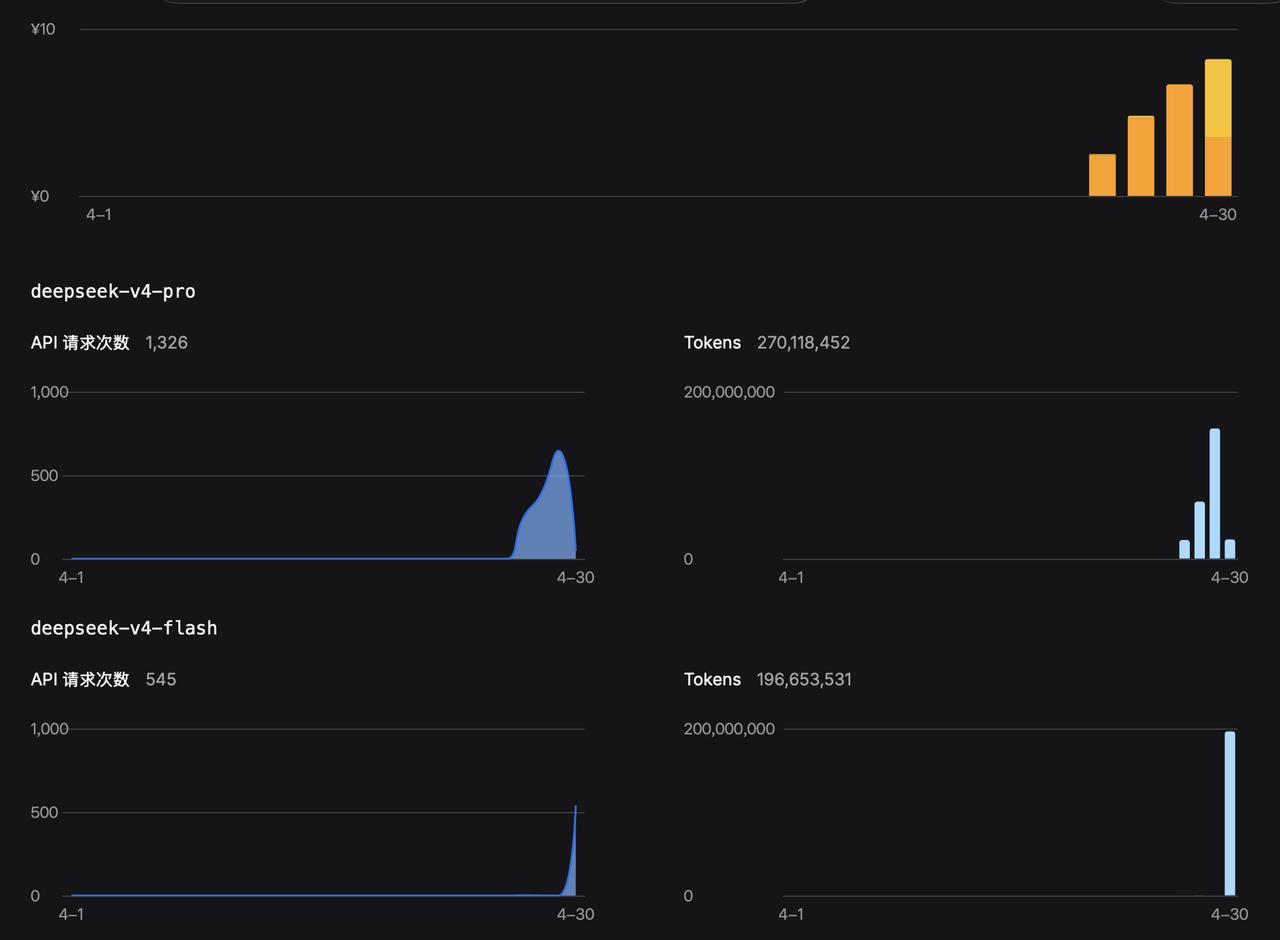
有资本市场支持,中国头部开源大模型研发已经摆脱了“缺钱”的麻烦。Kimi几个月就搞了四轮融资,融了376亿人民币,DeepSeek也会融到不少钱。有这些钱,就会去和美国闭源大模型死磕,将一个个美国大模型的价值归零。
Anthropic的创始人阿莫代伊刚说,中国大模型6-12个月会追上最先进的Claude Mythos。技术上,已经没有秘密,中国大模型就是需要不停迭代,获取足够使用经验,显然没有到发展瓶颈。
一旦美国大模型的性能领先不够大,或者中国大模型跨越了“好用”的技术门槛,美国卖token的生意模式就崩溃了。价格差异太大,这是经济规律。
可能的情况是,美国头部大模型开价极高,但是只占据5%之类使用场景,95%是中国开源大模型免费或者低价调用。中国算力不足,无法满足全球调用需求。但是中国大模型是开源的,美国有算力的公司会部署来赚钱。美国头部公司,被“中国开源大模型+美国算力”限制了营收,被击败了,token份额不高。最终,全球能够以较低的价格使用AI大模型,促进生产力发展。