如何让 AI 不仅写出「能跑」的代码,还能写出「跑得快」的代码?这个问题困扰了 AI 系统研究者很久。
近日,中科院计算所团队提出了一种名为 SparseRL 的新框架,首次将深度强化学习引入稀疏 CUDA 代码生成任务。简单来说,就是让 AI 学会根据稀疏矩阵的结构,自动生成最优的 CUDA 实现代码。
实验显示,在经典的 SpMV 任务上,这种方法能让编译成功率提升 20%,代码执行速度提升 30%。
目前,该项成果已入选 ICLR 2026 Oral。
 论文地址:https://openreview.net/pdf?id=VdLEaGPYWT
代码链接:https://github.com/QiWu-NCIC/SparseRL
论文地址:https://openreview.net/pdf?id=VdLEaGPYWT
代码链接:https://github.com/QiWu-NCIC/SparseRL 为什么稀疏代码这么难写?
要理解这项工作的价值,得先说说稀疏矩阵运算的特殊性。
稀疏矩阵在 LLM 推理、图神经网络、科学计算中无处不在。但和稠密矩阵不同,稀疏矩阵的非零元素分布是不规则的,这导致一个核心问题:最优的 CUDA 代码实现取决于矩阵的具体结构,而这个结构只有在运行时才能知道。
换句话说,没有一种「万能」的高性能实现能应对所有稀疏矩阵。工程师们不得不针对不同的稀疏模式手动调优,这个过程既耗时又依赖经验。
现有的 AI 代码生成方法也帮不上太大忙。原因有三:
第一,传统监督学习只关心代码「对不对」,不关心「快不快」。同一个稀疏矩阵可能有多种正确的 CUDA 实现,但执行速度可能相差数倍,监督学习无法区分这种差异。 第二,执行效率这个核心指标是「不可微」的,没法通过传统的反向传播来优化。 第三,稀疏矩阵的输入(行列索引序列)和 CUDA 代码之间存在巨大的语义鸿沟,模型很难理解矩阵结构和最优代码策略之间的关联。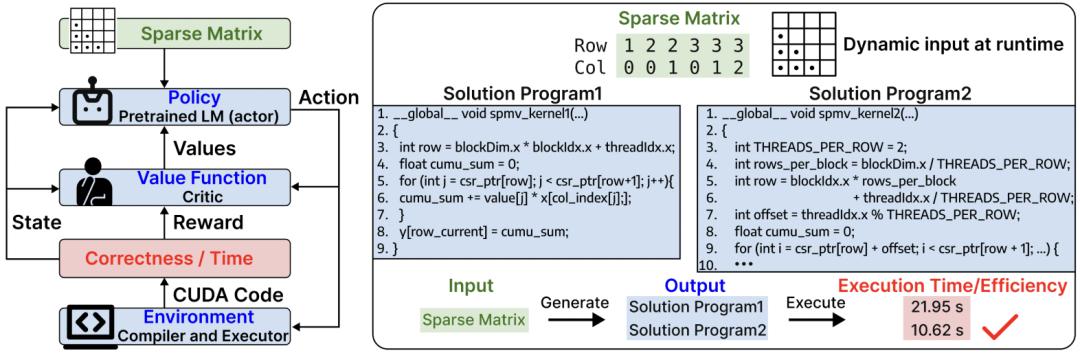
图片 1:展示不同稀疏矩阵需要不同 CUDA 实现策略的示例
SparseRL 怎么做到的?
研究团队的思路很巧妙:既然执行效率不可微,那就用强化学习来优化。
SparseRL 把预训练语言模型当作一个策略网络,每生成一个 token 就是一次动作,而代码的编译结果和执行时间就是奖励信号。
整个训练过程分为三个阶段:
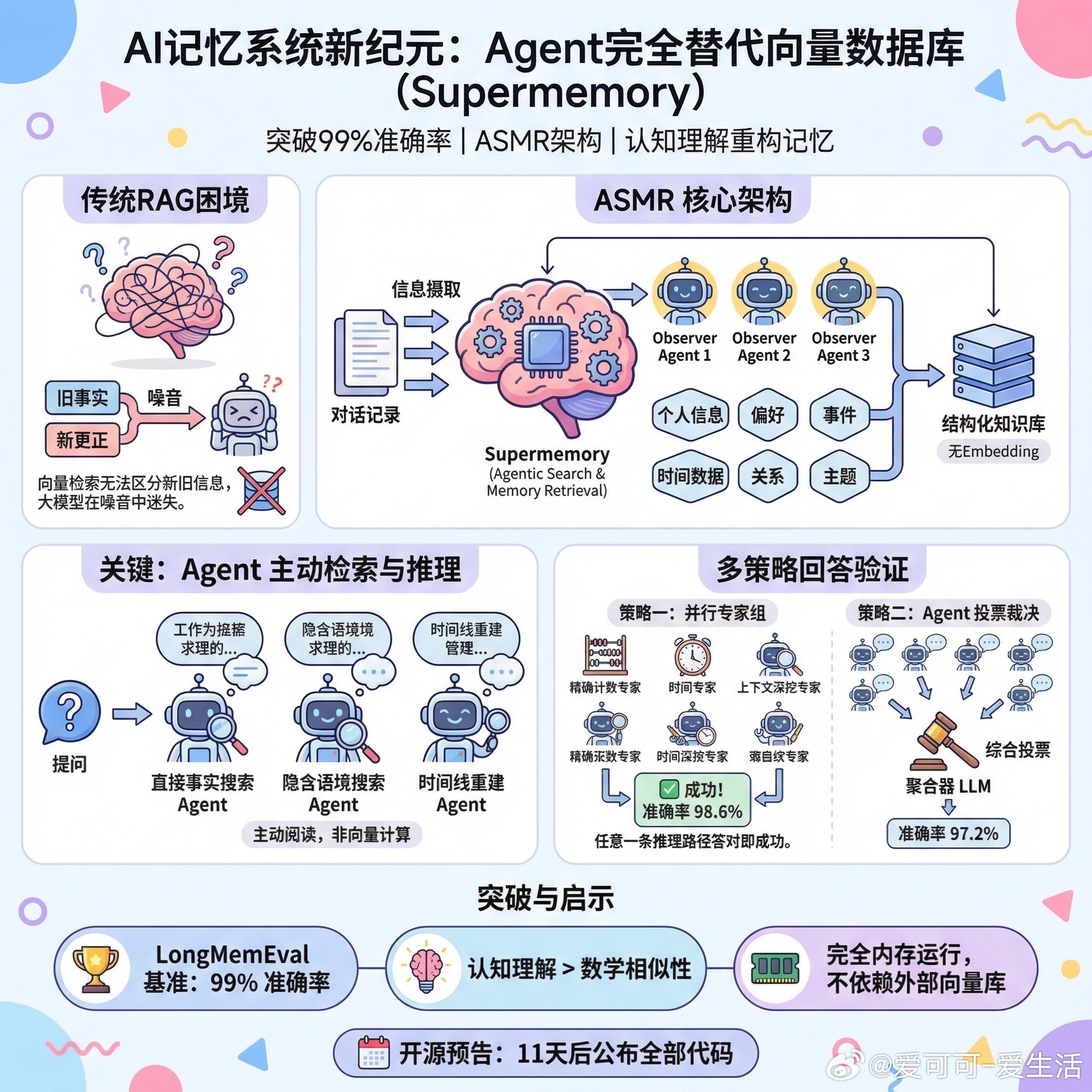
第一阶段是预训练:在大量 CUDA 代码语料上训练语言模型,让它建立对 GPU 编程的基础认知; 第二阶段是监督微调:用「稀疏矩阵 - 正确代码」的配对数据教模型生成语法正确、功能正确的代码; 第三阶段是强化学习优化:这一步是关键 —— 引入深度强化学习,以编译正确性和执行效率为奖励,让模型学会生成高性能代码。
图片 2:展示三阶段训练流程的整体框架图
为了让模型真正「看懂」稀疏矩阵的结构,研究团队设计了一个关键技术:正弦位置嵌入。
稀疏矩阵的输入是非零元素的行列索引序列,传统的 token 嵌入无法捕捉这种二维坐标之间的空间关系。SparseRL 对行列索引分别进行正弦 / 余弦编码,类似于 Transformer 的位置编码,但专门针对二维坐标做了定制。
用通俗的话说,这就像给模型装上了一副「坐标眼镜」,让它能看见非零元素在哪里、是怎么分布的。
另一个核心创新是层级奖励函数。这个奖励函数同时考虑两个层面:正确性奖励确保代码能编译、结果正确;效率奖励则优化执行速度。设计逻辑是先保证「对」,再追求「快」。
效果如何?
研究团队在 SpMV(稀疏矩阵 - 向量乘法)和 SpMM(稀疏矩阵 - 稠密矩阵乘法)两个任务上验证了方法的有效性。
在 SpMV 任务上,SparseRL 相比传统监督学习方法,编译成功率提升了 20%,平均执行速度提升了 30%。更重要的是,模型能根据不同的稀疏结构自动选择不同的代码策略,在对角型、带状型、随机稀疏型等多种矩阵上都有优势,部分场景下生成的代码甚至接近或超越了手工调优的水平。

图片 3:展示 SparseRL 与基线方法的差距
团队还做了消融实验来验证各个组件的必要性。
结果显示,去掉 RL 阶段后性能显著下降,说明强化学习确实是关键;去掉正弦嵌入后模型难以理解输入结构,编译率下降;只用正确性奖励而不用效率奖励,代码能跑但不够快。
当然,这个方法也有局限。论文提到,RL 训练需要大量的编译 - 执行反馈循环,计算成本较高;模型是针对特定 GPU 架构训练的,迁移到新硬件可能需要重新微调;生成的代码可能缺乏人类工程师的编码风格,可解释性不足。
意义与展望
SparseRL 的价值在于它代表了一个范式转变:代码生成的目标从「生成能运行的代码」转向「生成高性能代码」。
对于 HPC 工程师和 AI 基础设施开发者来说,这项工作展示了一种新可能 —— 让 AI 来处理那些繁琐的性能优化工作,而人类可以把精力放在更高层次的设计上。
研究团队表示,未来计划将方法扩展到多 GPU 分布式稀疏计算,探索与传统 AutoTuning 技术的结合,并支持更多类型的稀疏算子。同时,他们也在研究如何降低 RL 训练成本,让这种方法更实用。
作者介绍
王耀宇,中国科学院计算技术研究所博士生(共同一作),主要研究方向为深度学习编译优化与高性能计算。
谭光明,中国科学院计算技术研究所研究员、博士生导师,主要从事高性能计算、GPU 编译优化与深度学习系统研究,在多 GPU 分布式计算、稀疏矩阵计算、深度学习编译器等领域取得多项重要成果,发表多篇高性能计算与机器学习相关论文。