中美主流AI大模型全方位对比解读(基于2024年5月评测数据)
这份评测从综合性能、模型规模、成本、能力特性四大维度,清晰呈现了中美大模型的真实实力与各自赛道优势。
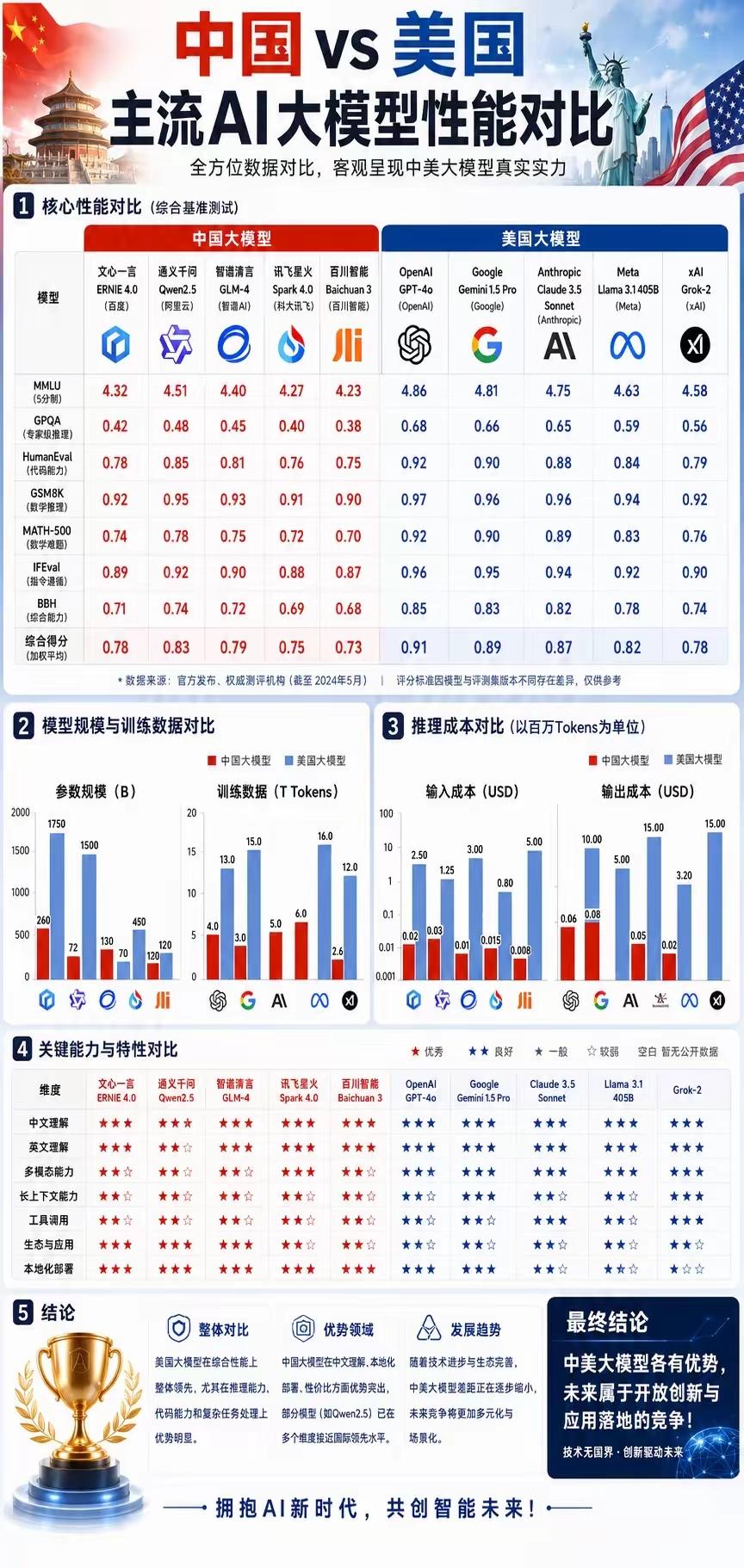
一、综合性能:美国整体领跑,国产头部快速追赶
美国梯队(综合得分0.82~0.91,全面领先)
1. GPT-4o(OpenAI):综合得分0.91,全维度断层第一,推理、代码、数学、指令遵循能力全面顶尖,是通用大模型标杆。
2. Gemini 1.5 Pro(Google):0.89分,多模态能力极强,长上下文表现突出。
3. Claude 3.5 Sonnet(Anthropic):0.87分,超长文本、复杂逻辑处理领域优势明显。
中国梯队(综合得分0.73~0.83,本土化优势显著)
1. 通义千问 Qwen2.5(阿里):0.83分,国产综合第一,部分维度已逼近国际头部。
2. 智谱清言 GLM-4:0.79分,学术、知识类场景表现稳定。
3. 文心一言 ERNIE 4.0:0.78分,百度生态适配度高,搜索+AI结合紧密。
4. 讯飞星火、百川智能:0.75/0.73分,垂直行业落地表现突出。
核心差距:美国模型在复杂推理、代码能力、数学难题上优势明显;国产模型在中文理解、本地化场景上更贴合国内用户。
二、模型规模与训练数据
- 参数规模:中国大模型整体参数体量更大(文心一言260B、通义千问130B),美国模型更偏向小而精的高效路线(GPT-4o未公开但整体轻量化优化)。
- 训练数据:美国模型训练数据量整体更大,GPT-4o、Gemini、Claude训练数据远超国产,这也是其通用能力更强的核心原因。
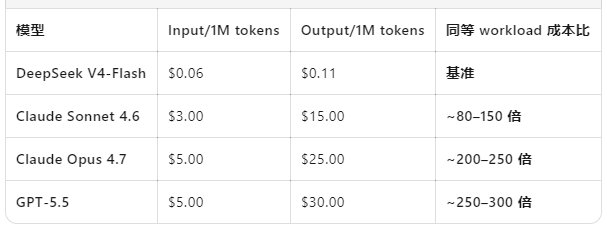
三、推理成本:国产模型性价比全面碾压
以百万Tokens为单位对比:
- 国产模型输入成本普遍0.01~0.08美元,输出成本0.05~0.08美元;
- 美国模型输入成本1.25~5美元,输出成本3.2~15美元;
国产大模型在商业化落地、规模化部署时,成本优势极大,更适合国内企业做私有化、大规模AI应用。
四、关键能力特性对比(核心差异)
美国模型核心优势
✅ 英文理解、多模态、工具调用、长上下文、通用生态全面领先,适合全球通用场景、复杂研发、多模态创作。
中国模型核心优势
✅ 中文理解、本地化部署、国内生态适配、成本可控优势突出,通义千问在多模态、长上下文上已追平国际水平,更适配国内政务、企业、互联网场景落地。
五、最终结论
1. 整体格局:美国大模型在通用综合能力上仍保持领先,国产头部模型已大幅缩小差距,部分维度实现对标。
2. 优势分化:美国强于通用推理、代码、全球生态;中国强于中文、本地化、性价比、私有化部署。
3. 发展趋势:随着国产技术迭代与生态完善,中美差距持续缩小,未来AI竞争将从技术参数比拼,转向场景落地、应用创新的竞争。
一句话总结:通用全能选美国头部,国内商业化落地、中文场景优先选国产大模型。
AI市场份额 AI优缺点 AI国产大模型 AI芯片自主率 ai大对比 AI测评体系 AI模型横评