说真的,大家这两天可以关注一下这个:文心5.1的预训练成本,大概是业界同规模模型的6%。
我看到这个数字的时候,第一反应是:这写错了吧?
假如别人训练同规模模型要花100块,百度只需要用6块就搞定了?
1
我先简单交代一下背景。
过去两三年,大模型行业一直流传着一套心照不宣的逻辑:要想效果好,就得砸钱。
更多的 GPU,更多的训练数据,更高的预训练成本,最后才能换来模型能力的提升。
这套逻辑也带来了一个隐患:这条路越走越贵,门槛越来越高,普通公司想进来的难度越来越大,小团队更是没法入场。
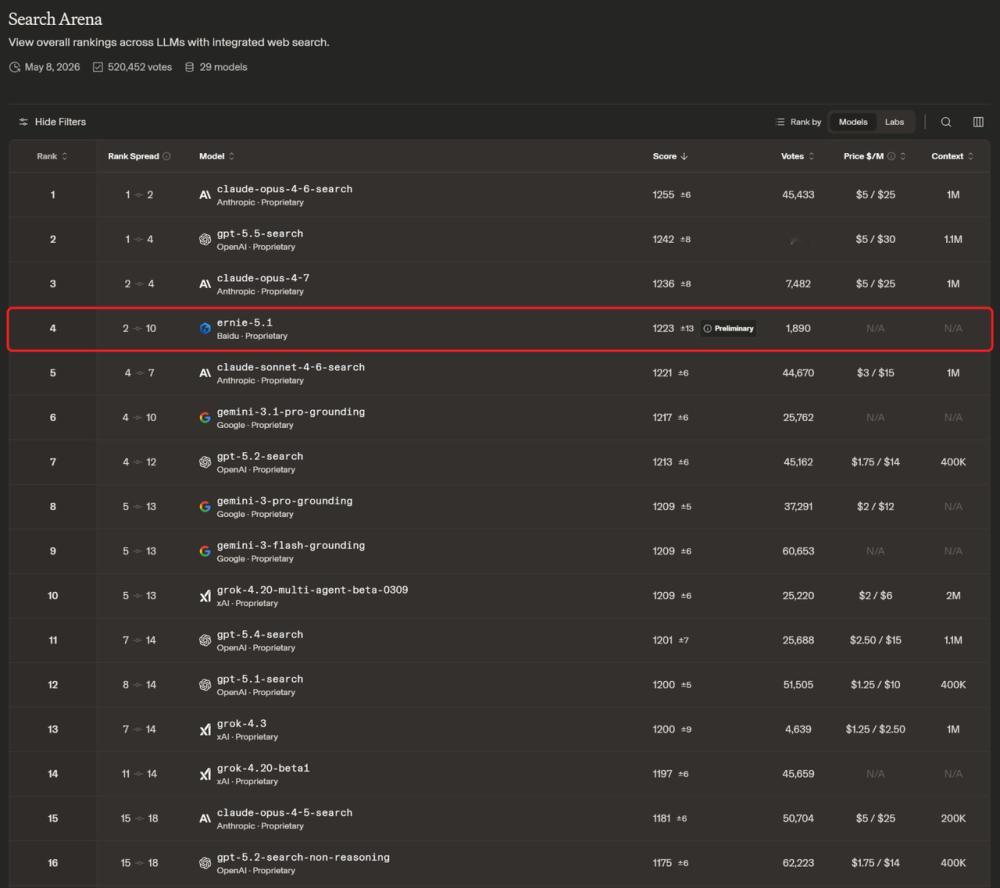
所以当百度说,文心 5.1 只用了业界同规模模型 6% 的预训练成本,还没有明显牺牲模型能力,甚至在 LMArena 搜索榜(Search Arena)上拿了国内第一、全球第四,是唯一上榜的国产模型。
其分量,你大概能感受到了。
2
那到底是怎么做到的?
文心 5.1 用的这套技术叫"多维弹性预训练",是从文心 5.0 时代就开始搭建的体系。
通常我们理解的大模型训练,是一条路走到底,确定好模型结构,然后大量数据喂进去,跑完整个训练流程,得到一个固定规模的模型。
这个过程没有什么弹性可言,你想要一个 70B 的模型,就从头训一个 70B 的;想要 13B 的,就重新来过。
成本就是这么叠起来的。
而多维弹性预训练干的事情,是在一次训练过程中,通过调整模型的深度、专家容量、路由稀疏度等维度参数,直接"捏出"不同规模的模型——不是把大模型裁剪压缩,而是在训练时就已经在生成多种形态的模型。
这个思路的核心转变在于:训练的成本不再随模型数量线性增长。
原来你要三种规模的模型,就得训三遍。
现在训一遍,产出可能覆盖多个规模需求。
文心 5.1 这次的结果是:总参数压缩到文心 5.0 的约三分之一,激活参数压缩到约二分之一,但综合能力并没有同比例下滑,而是继续有所提升,且在搜索类任务上达到了国内最强水平。
3
当然,我知道很多人会有一个疑问:成本这么低,效果到底靠不靠谱?
这个问题很合理,我自己也是带着这个怀疑去看测评数据的。
LMArena 搜索榜(Search Arena),文心 5.1 以 1223 分拿下国内第一、全球第四,也是进入榜单的唯一国产模型。
再往前几天,文心 5.1 Preview刚刚在LMArena 文本榜上拿下国内第一,分数达到 1476,在榜单前十五名里是唯一一个国产模型,超过了 GPT-5.5 和 DeepSeek-V4-Pro。
在 Agent 能力这块,提升也比较明显,超过了 DeepSeek-V4-Pro;创意写作方面,被认为和 Gemini 3.1 Pro 处于同等水平;推理能力已经接近业界头部闭源模型的区间。
把这些放在一起看,基本可以说:成本降到 6%,没有换来能力的明显妥协。
这里我多说一句,这个"搜索能力"的含义,可能和你平时说的搜索不太一样。
LMArena 搜索榜测的不是"会不会用搜索引擎",而是模型在面对复杂问题时,能不能同时整合多个信息来源,并生成一个内部一致性强、表达可靠的回答。
这种能力在企业场景里价值极高,知识管理、多轮问答、内容生成、Agent 流程里的信息处理环节——凡是需要模型既理解问题又能整合背景知识输出的地方,搜索能力的强弱会直接决定应用的可靠程度。
4
说回到 Create 2026。
5 月 13 日,百度将在北京国家会议中心二期举办今年的 AI 开发者大会。
正常情况下,这类大会之前,厂商通常会做一些氛围预热,放点宣传物料,偶尔发一条倒计时推文。
但百度这次的操作有点不一样,直接发布了一个真实可用、已经上线的模型。
如果前菜都是这个体量,那大会现场,百度还准备端出什么?
从文心 5.0 到文心 5.1,这条技术路线已经跑出了初步结论:多维弹性预训练这套框架是可行的,成本压缩是真实的,模型能力没有断崖。
那接下来,这套框架还能往哪走?是更极致的压缩比,还是更多模态的整合,还是面向 Agent 场景的专项优化?
这些问题,大概只有等 5 月 13 日之后才有答案。