【LLM 教学最大误区:沉迷算法,忽略数据底层逻辑】
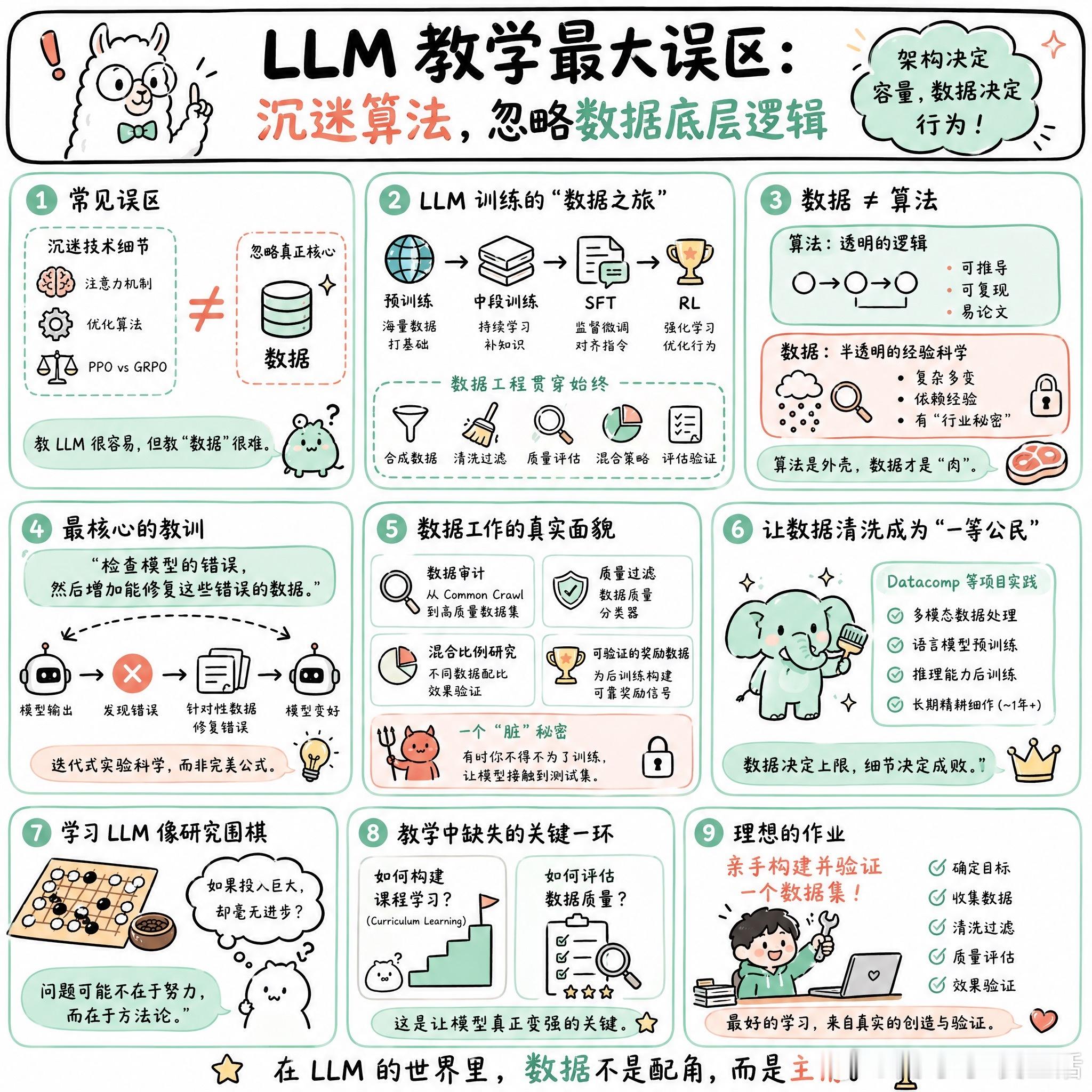
快速阅读:当前的 LLM 教学容易陷入技术细节的泥潭,如注意力机制或优化算法,但真正的核心在于数据。架构决定了模型的容量,而数据决定了模型的行为。
教 LLM 很容易,但教“数据”很难。
很多课程把大量时间花在效率技巧、Attention 变体或者 PPO 与 GRPO 的对比上。这些东西很像数学或算法,逻辑透明,容易写成论文,也容易讲清楚。但这些只是外壳。真正的“肉”在数据里:预训练、中段训练、SFT、RL,还有各种合成数据、清洗、评估和混合策略。
数据是半透明的,甚至带有某种“行业秘密”的色彩。它不像算法那样严谨,更像是一种经验科学。有观点认为,架构设定了容量,但数据决定了行为。如果你能理解这一点,就理解了现代 LLM 进步的本质。
要把数据讲透,不能只靠堆砌名词。有网友提到,最核心的教训其实很简单:检查模型的错误,然后增加能修复这些错误的数据。
这种逻辑更接近一种迭代式的实验科学。我们需要讨论的不是某种完美的公式,而是:我们尝试了什么,声称什么有效,以及如何证明它有效。这包括从 Common Crawl 到高质量数据集的审计、数据质量分类器、混合比例的研究,以及在后训练阶段如何构建可验证的奖励数据。
甚至有一个很“脏”的秘密:有时你不得不为了训练而让模型接触到测试集。
现在的研究正试图让数据清洗成为“一等公民”。比如 Datacomp 项目,从多模态数据到语言模型预训练,再到推理能力的后训练,每一步都需要长达一年的精耕细作。
如果学习 LLM 的过程像是在研究围棋,当你觉得投入了巨大努力但水平纹丝不动时,问题可能不在于努力程度,而在于你的方法论。
目前的教学还缺了一块:如何具体为特定的任务构建课程学习(Curriculum Learning)?如何评估这些数据的质量?
或许,最好的作业不是写代码,而是让学生亲手去构建并验证一个预训练或后训练的数据集。
x.com/yoavgo/status/2048781896499212518