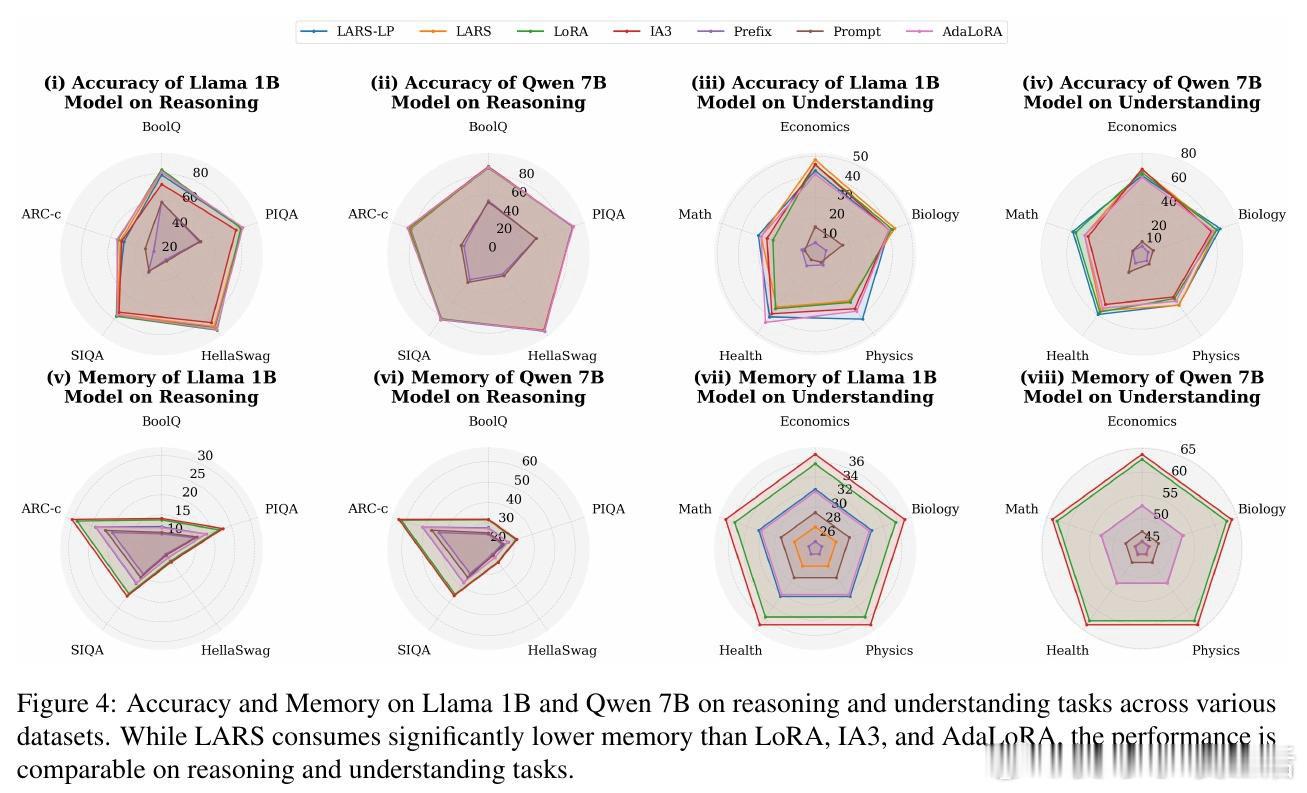
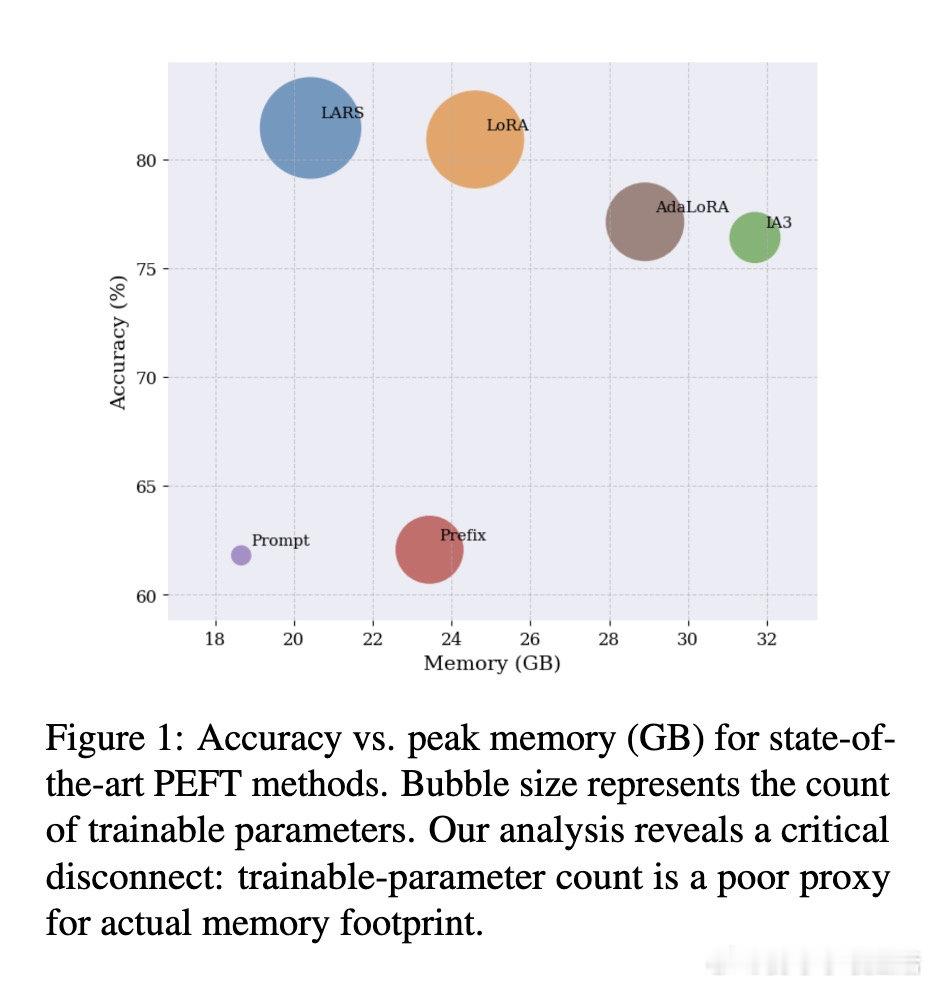
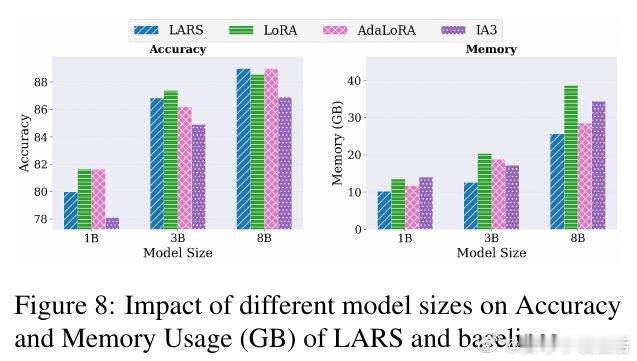
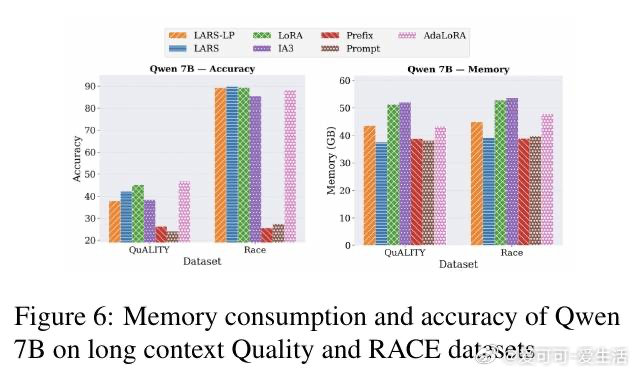
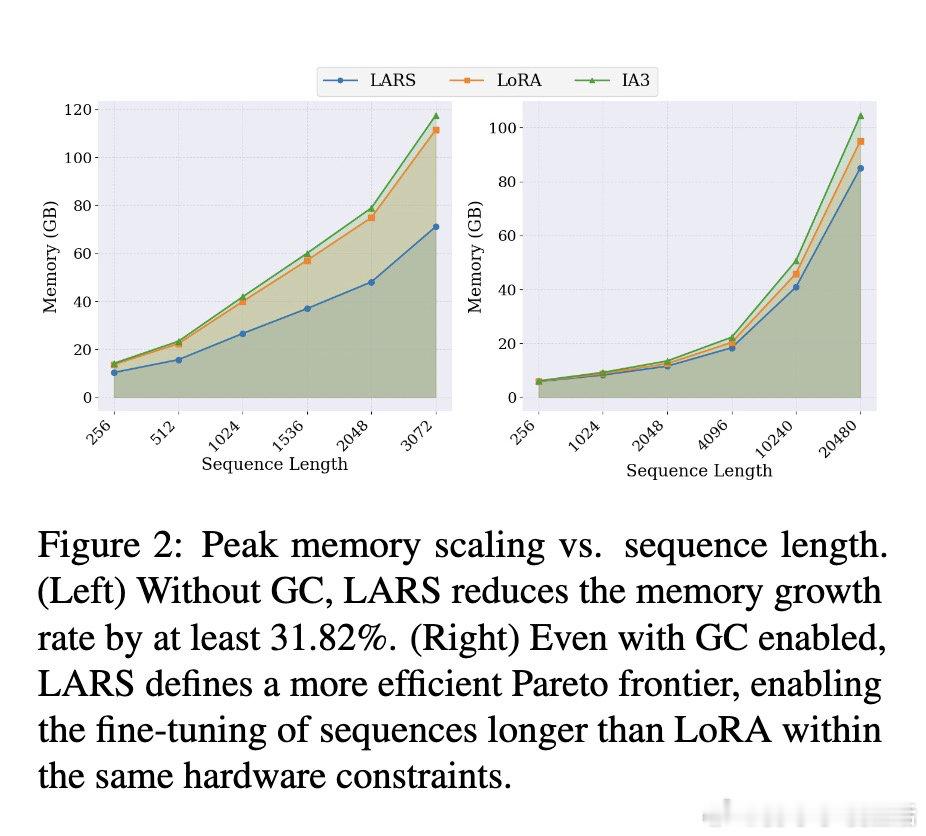
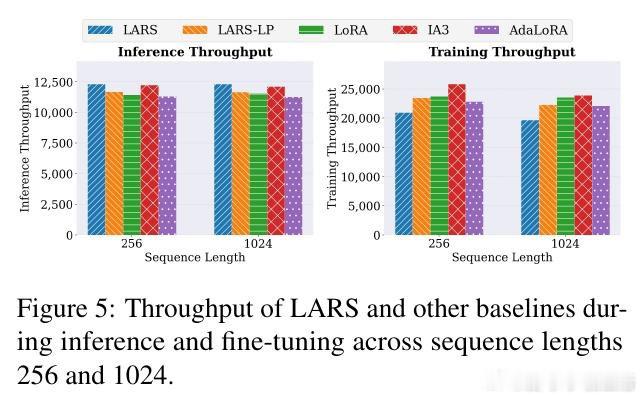
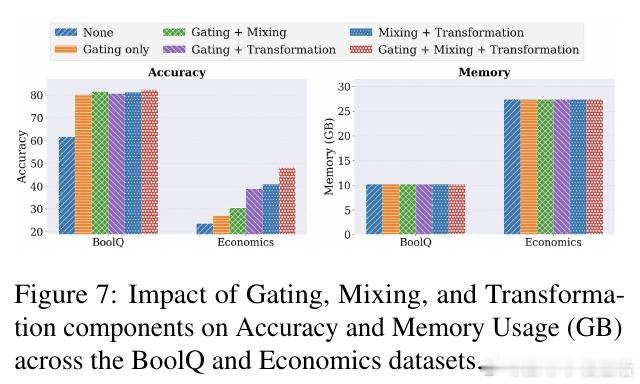
[LG]《Parameter Efficiency Is Not Memory Efficiency: Rethinking Fine-Tuning for On-Device LLM Adaptation》I Tenison, S Ahn, M Kim, E Alshehri… [MIT CSAIL] (2026)
在设备端微调LLM时,参数量虽小仍频繁爆内存。过去方法受困于只压缩权重,本质原因是激活张量随序列长度线性膨胀,成为真正瓶颈。
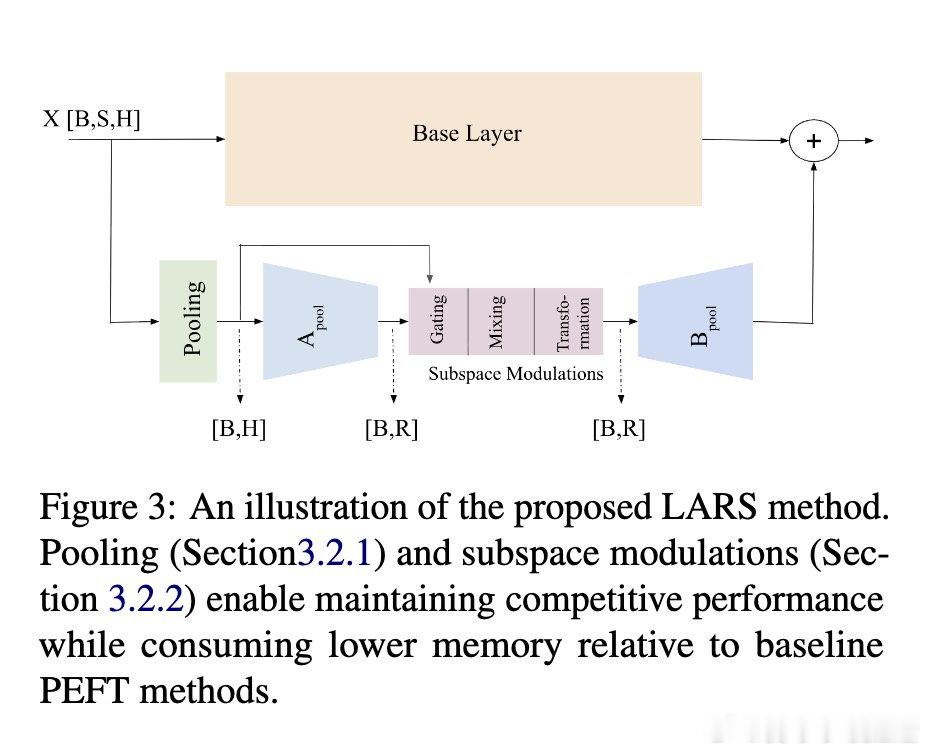
本文的核心洞见是:把适配过程从“参数空间”转移到“激活子空间”。由此,先压缩序列为全局向量,再在低秩空间更新,切断内存与序列长度的绑定。
这项工作真正留下的遗产是重定义“高效微调”的衡量标准。它为边缘设备训练打开新门,但尚未跨过的门槛是池化可能损失细粒度token信息与大模型验证不足。
arxiv.org/abs/2604.22783 机器学习 人工智能 论文 AI创造营