[LG]《Reward Models Are Secretly Value Functions: Temporally Coherent Reward Modeling》A Nikulkov [AI at Meta] (2026)
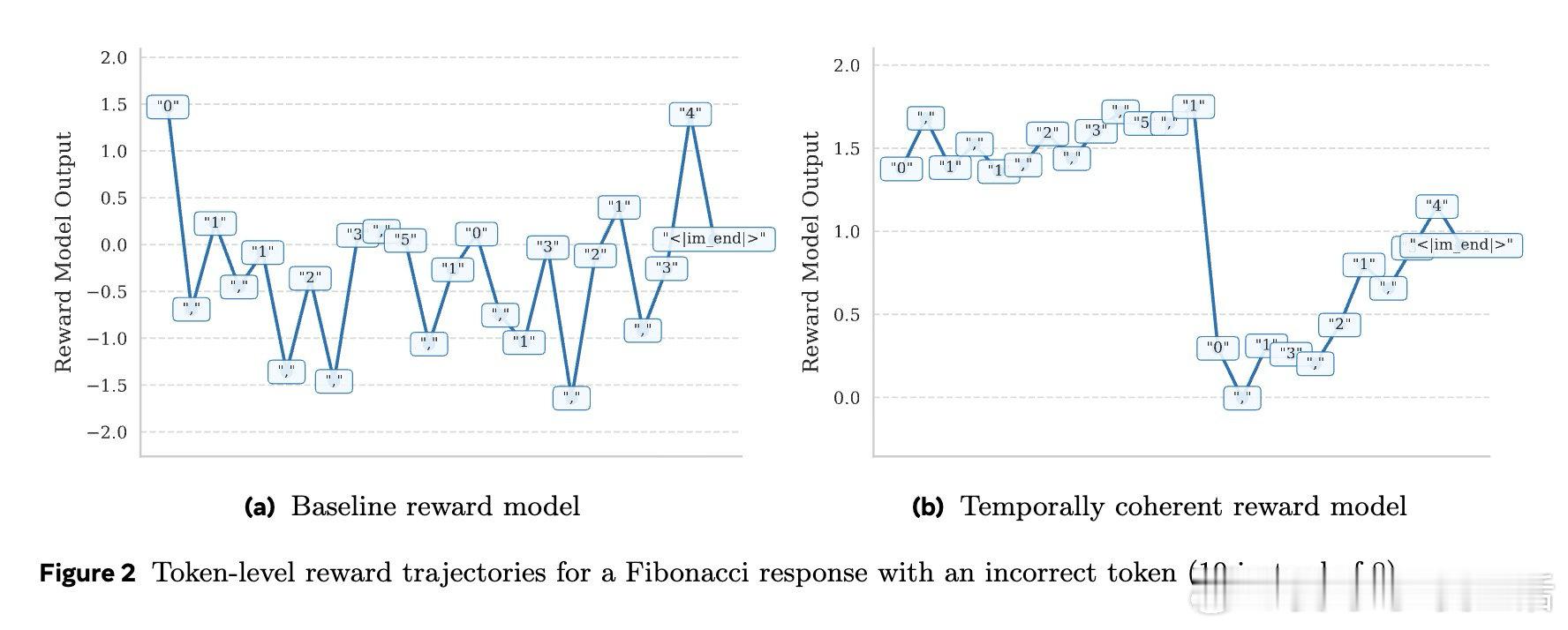
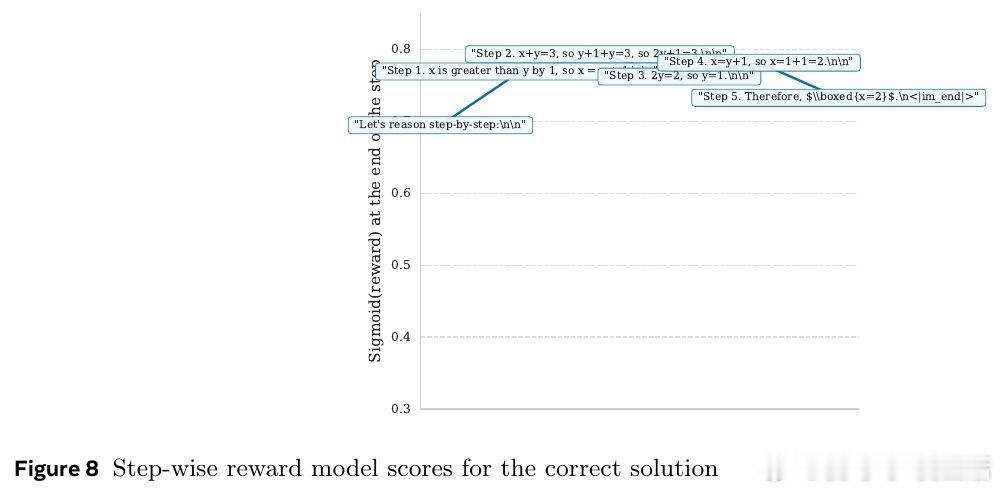
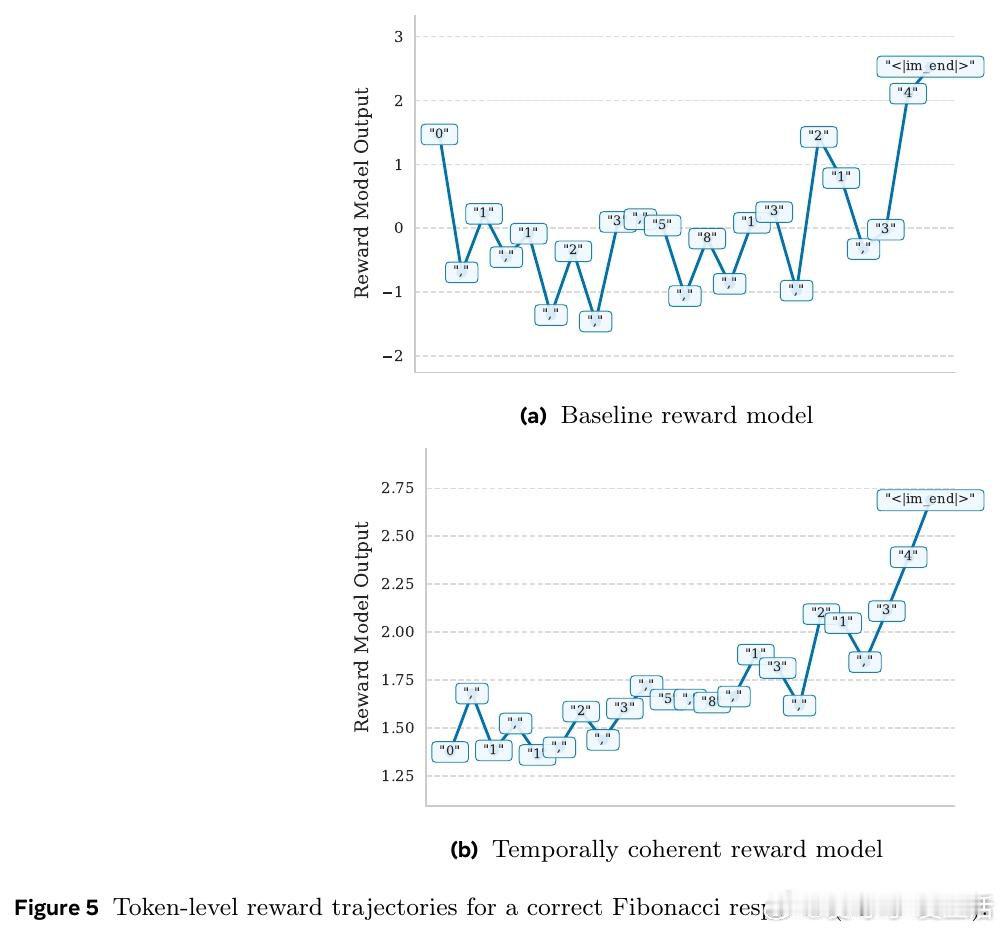
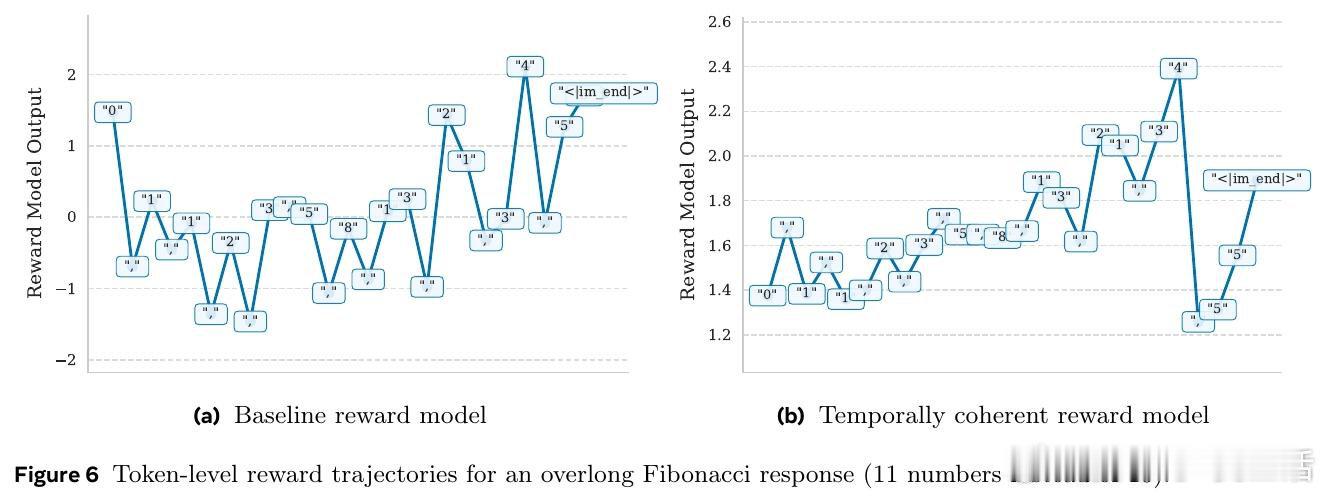
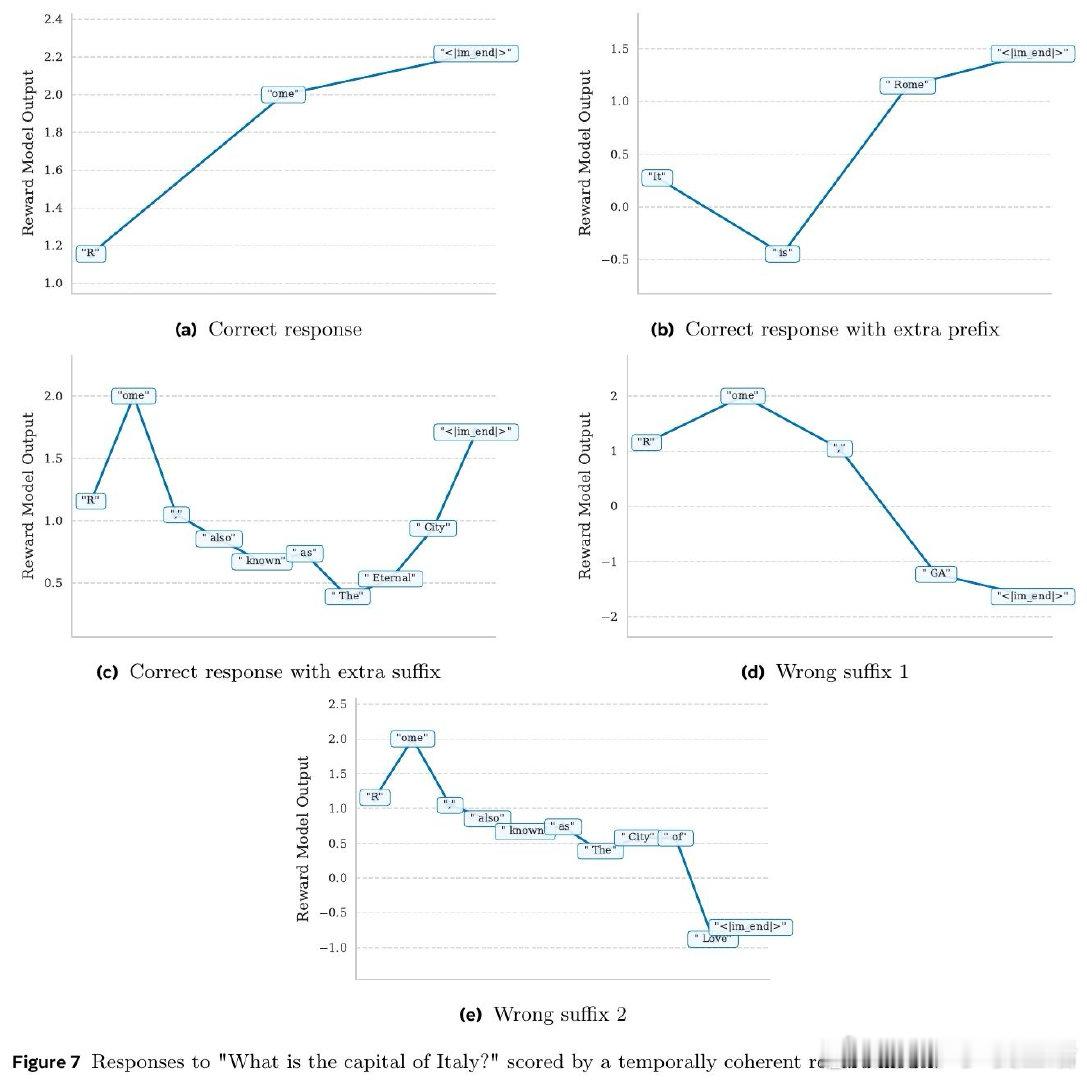
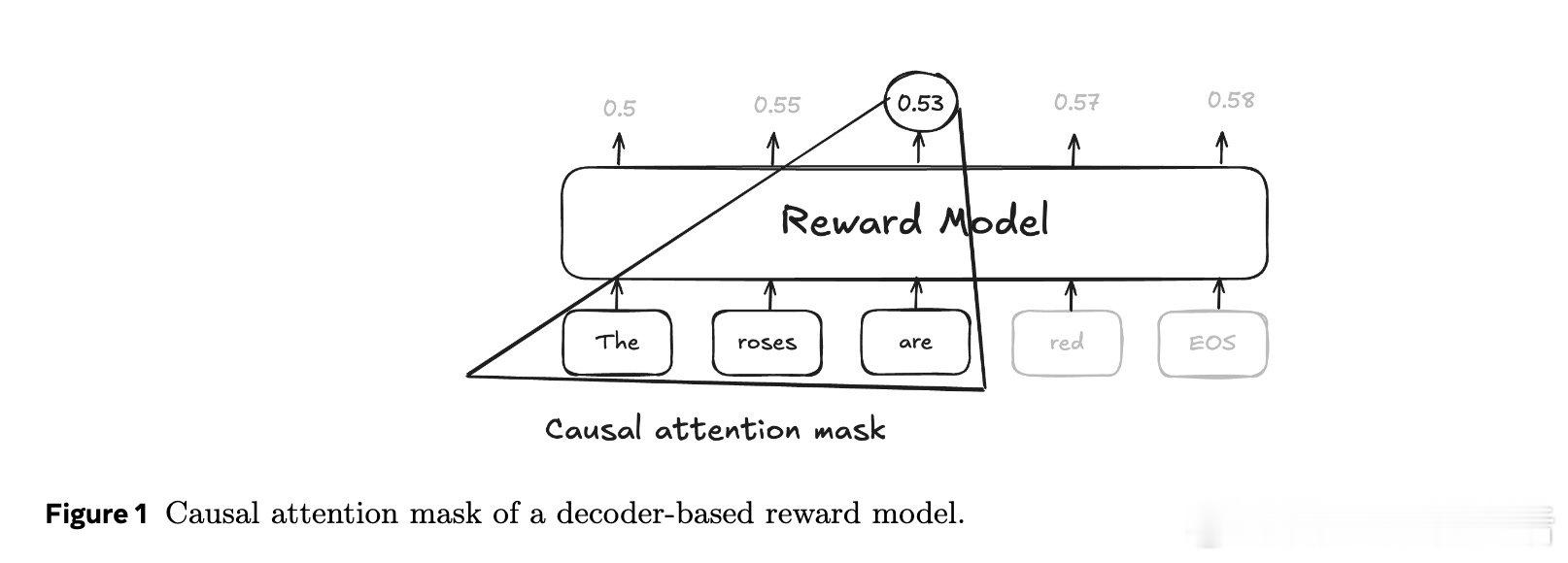
在RLHF中奖励模型只看最后一个token,丢弃中间信息,导致逐token输出像噪声。过去方法受困于只用终点监督,本质原因是未把“生成过程”视作可预测的序列价值。
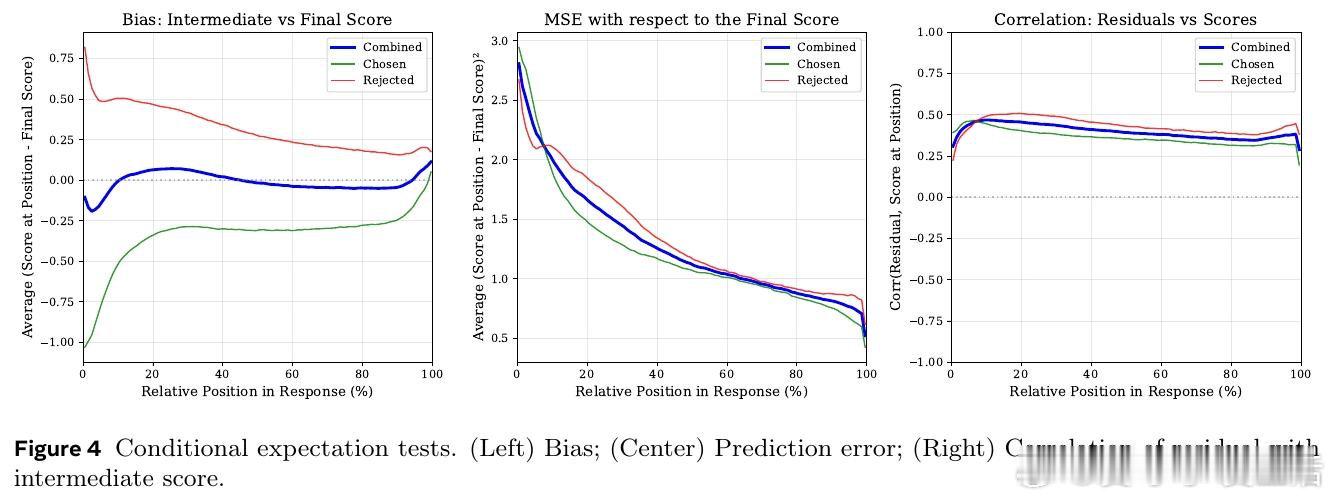
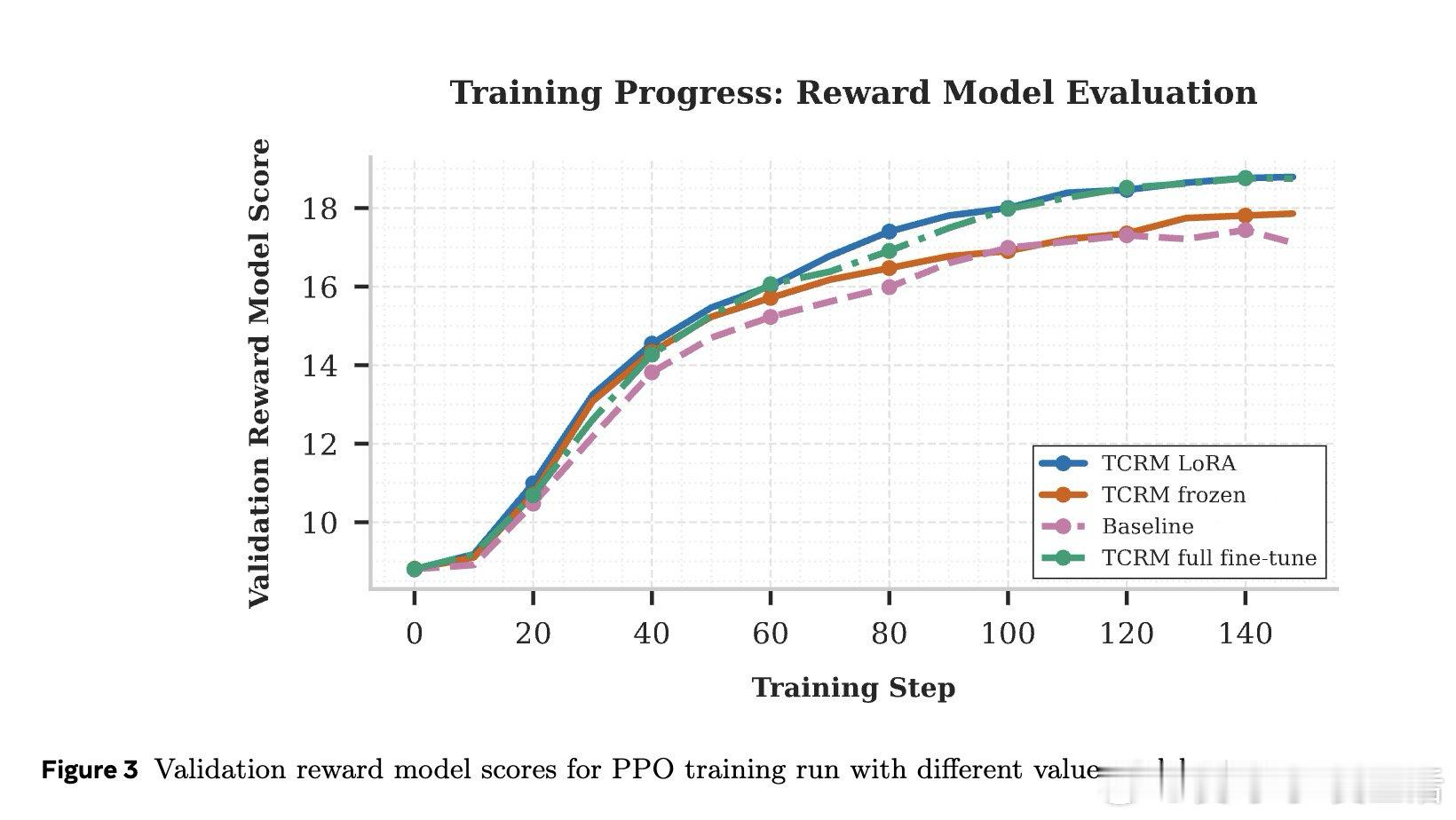
本文的核心洞见是:把每个中间token的分数重新看作“对最终奖励的条件期望”。由此,引入前视一致与相邻平滑两种约束,使每一步都对终局做出一致预测。
这项工作真正留下的遗产是把奖励模型与价值函数统一。它为无步骤标注的过程评估与更高效PPO打开新门,但尚未跨过的门槛是中间预测仍非严格条件期望。
arxiv.org/abs/2604.22981 机器学习 人工智能 论文 AI创造营