[LG]《Scaling Multi-Node Mixture-of-Experts Inference Using Expert Activation Patterns》A Bambhaniya, G Jeong, J Park, J Yu… [Meta & Georgia Institute of Technology] (2026)
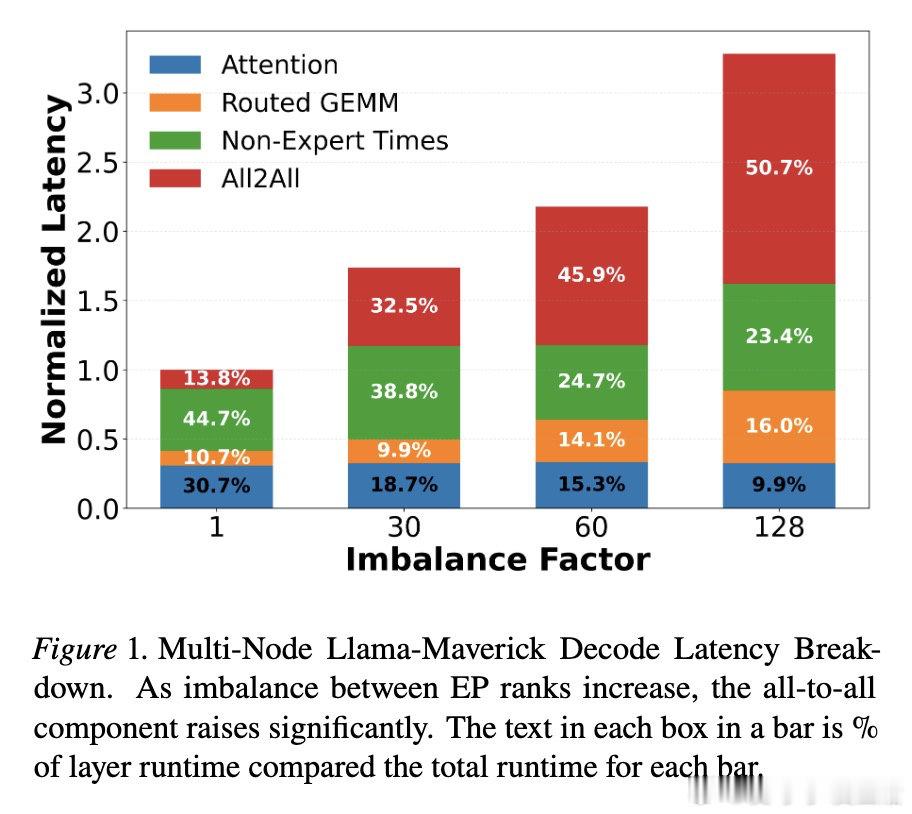
在多节点MoE推理中,token需跨节点找专家,通信开销反成主瓶颈。过去方法受困于忽视“专家激活模式”,本质原因是路由动态性与硬件拓扑错位。
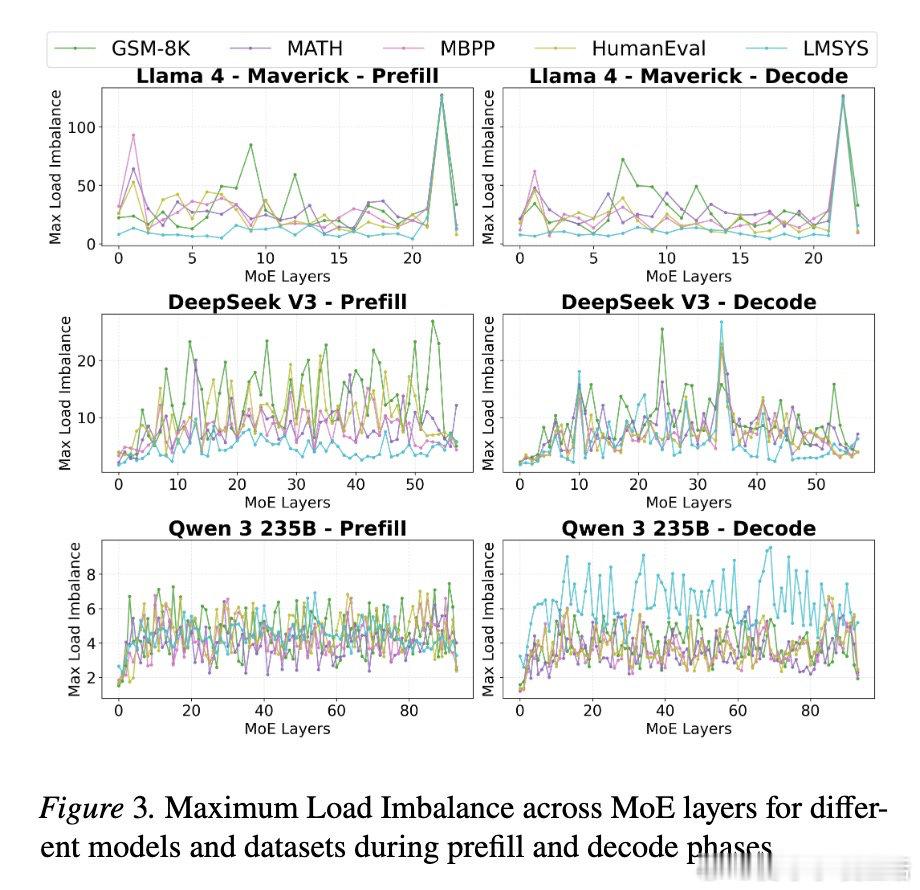
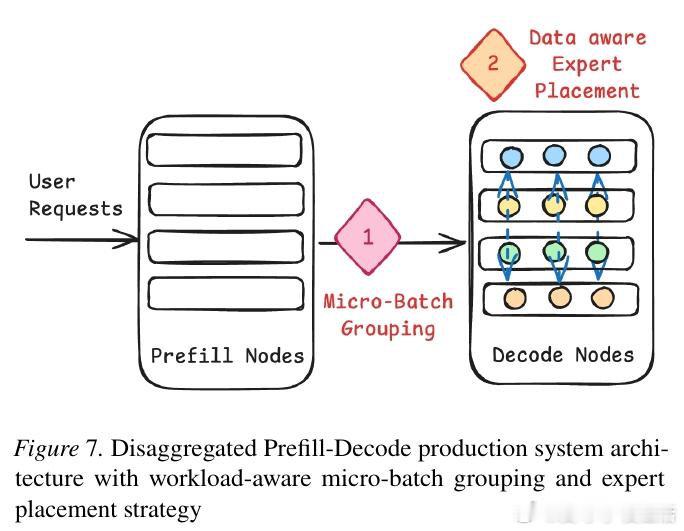
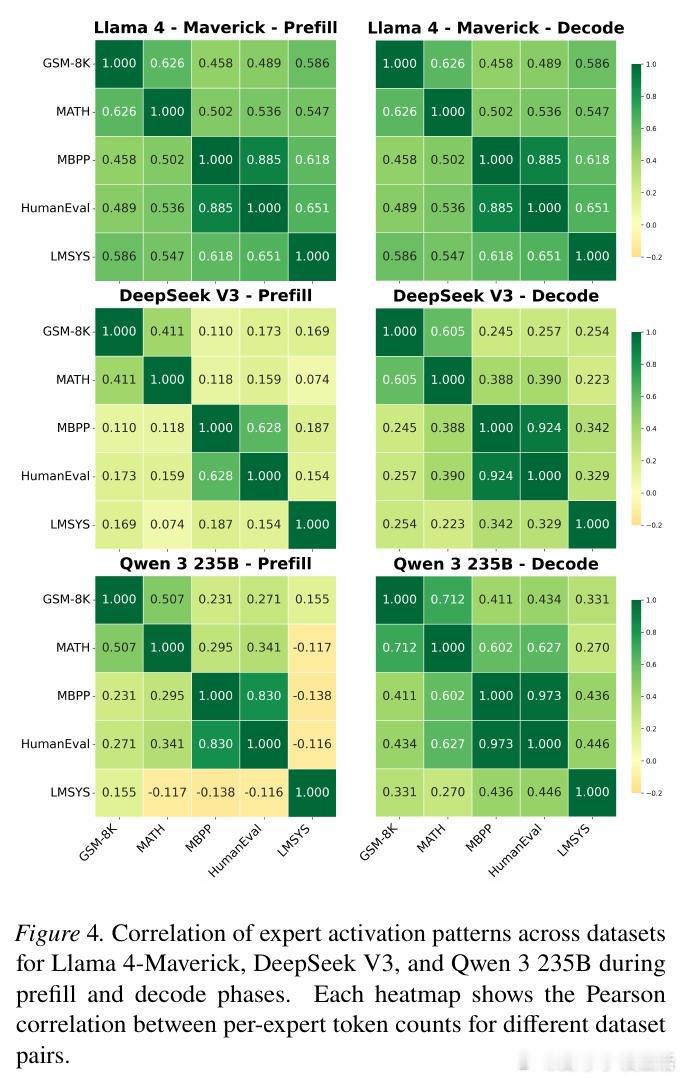
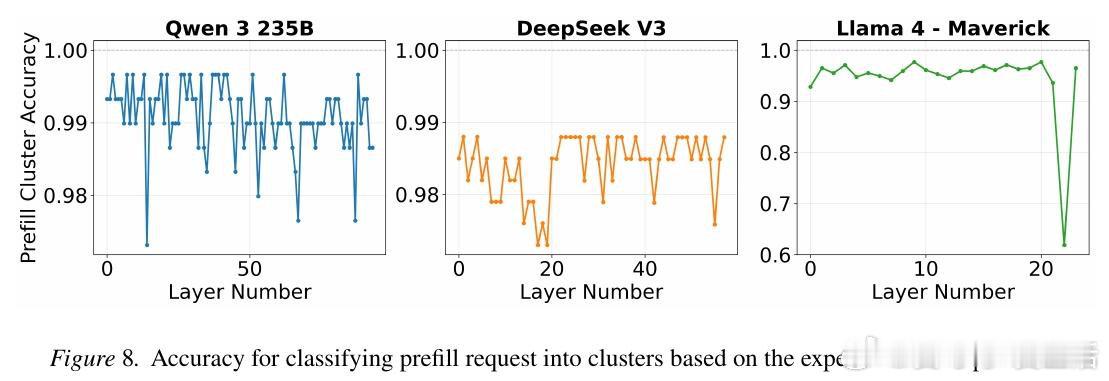
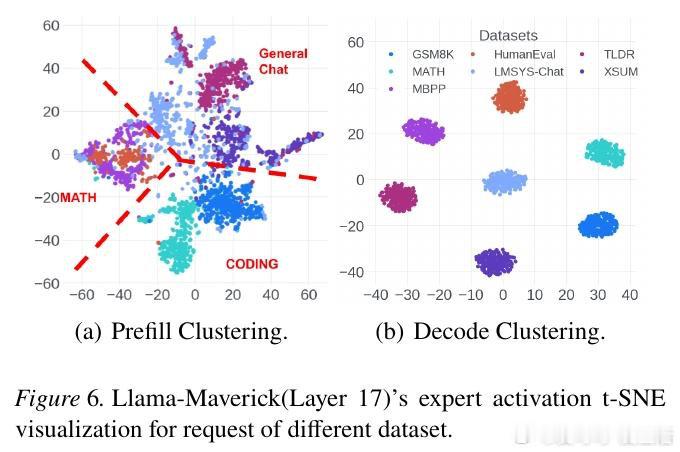
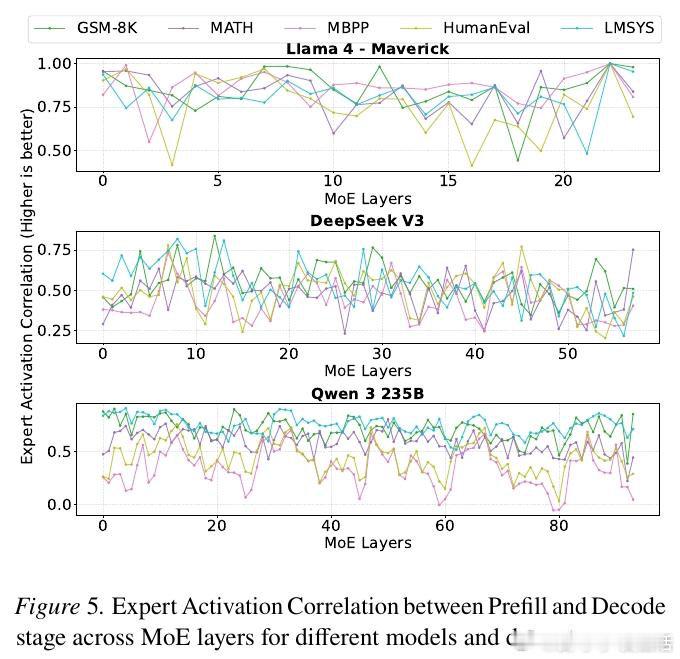
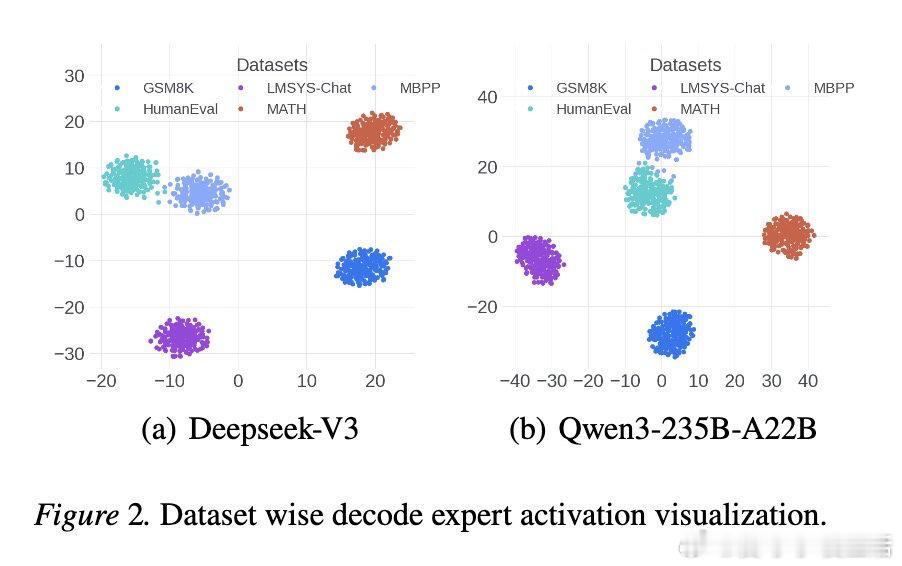
本文的核心洞见是:把请求重新看作“可被专家激活模式聚类的负载”。由此,按激活相似性分批并重排专家位置,使更多token在本地命中,减少跨节点通信。
这项工作真正留下的遗产是用数据驱动调度替代静态部署。它为MoE高效扩展打开新门,但尚未跨过的门槛是通信内核与极端负载不均仍限制收益。
arxiv.org/abs/2604.23150 机器学习 人工智能 论文 AI创造营