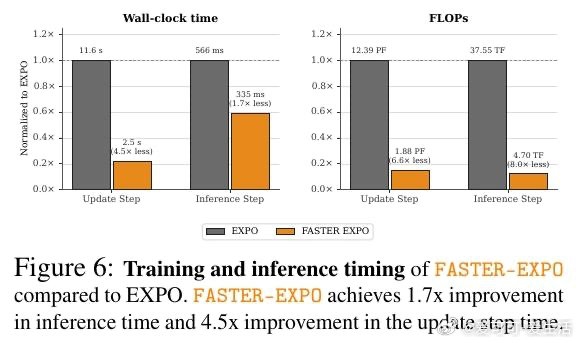
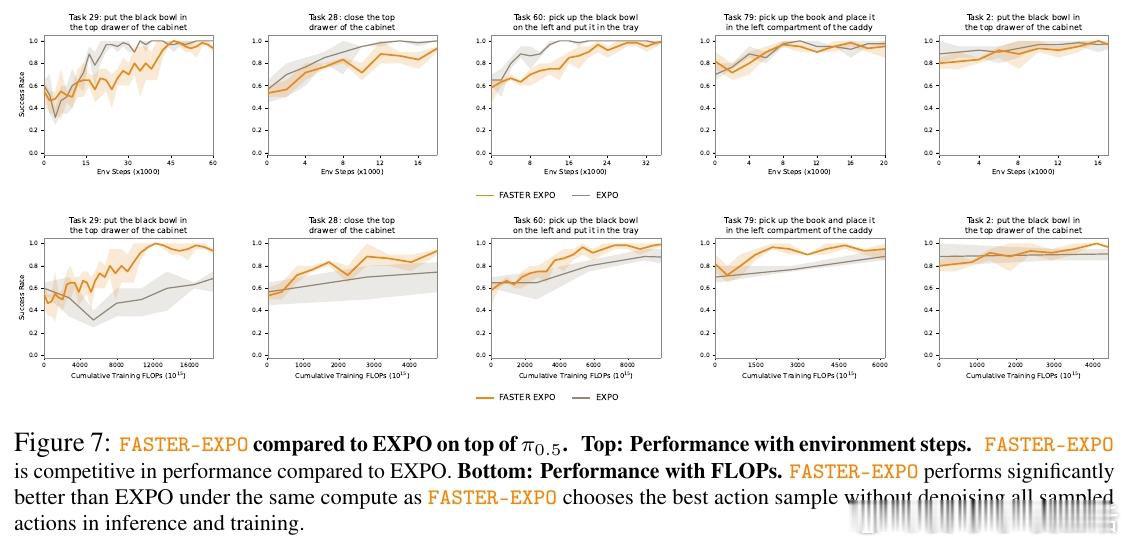
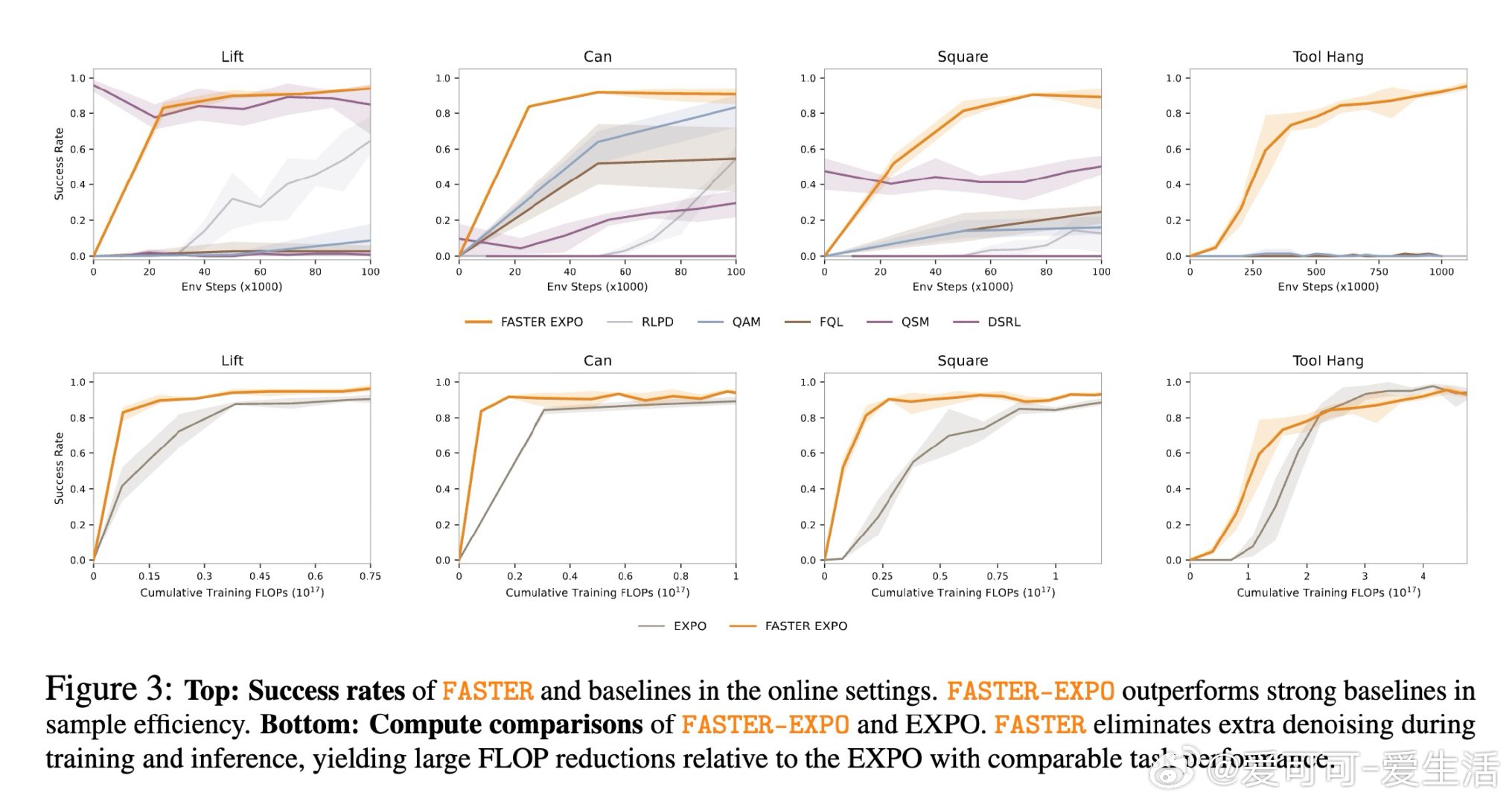
[LG]《FASTER: Value-Guided Sampling for Fast RL》P Dong, A Swerdlow, D Sadigh, C Finn [Stanford University] (2026)
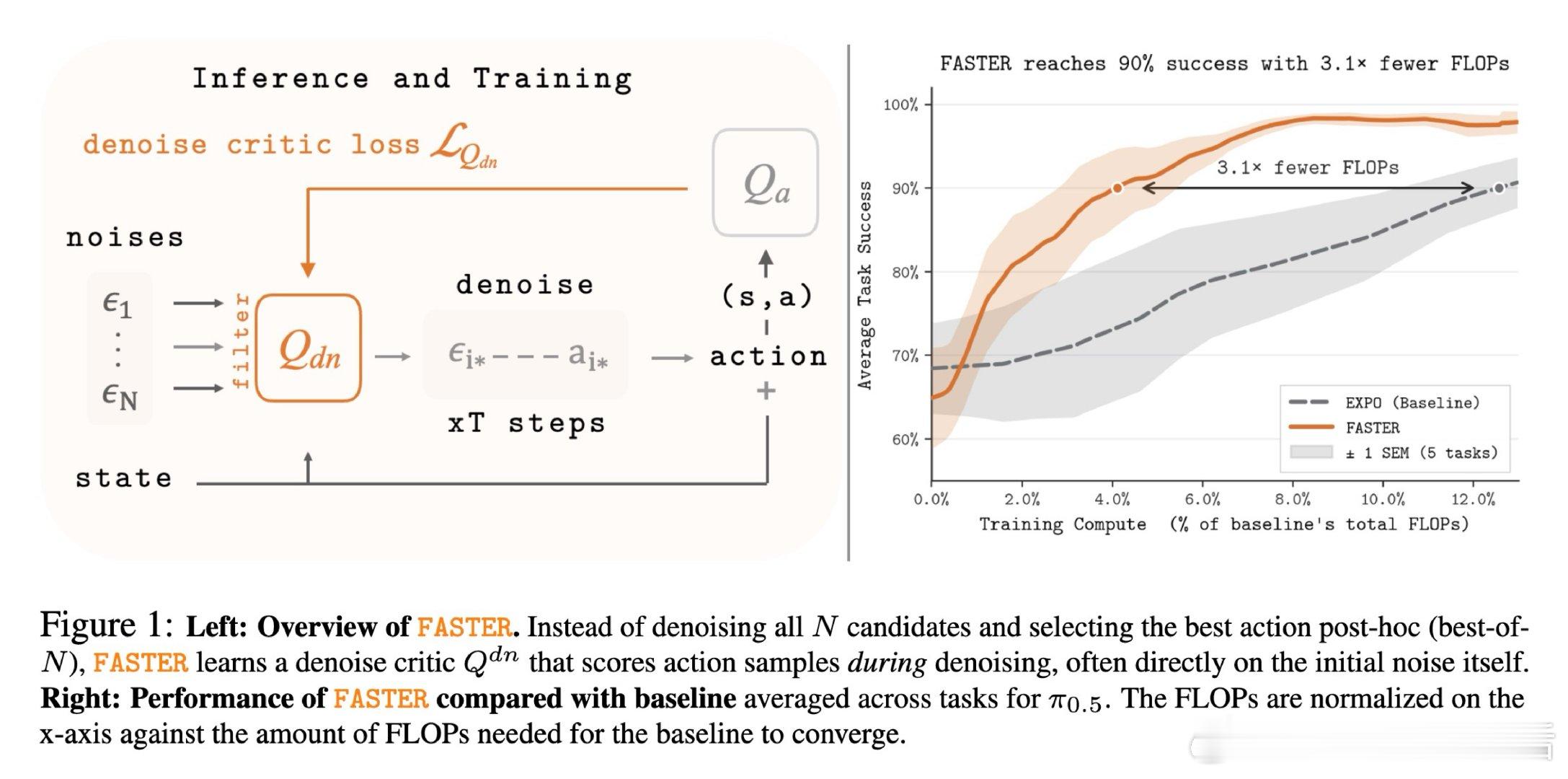
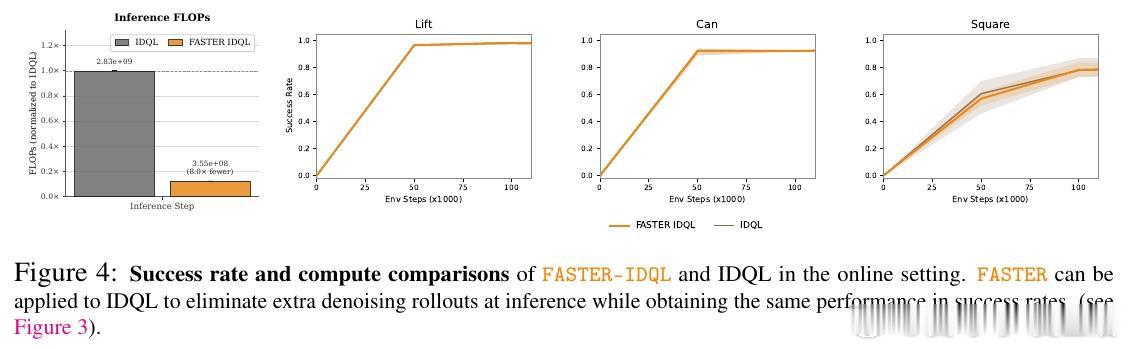
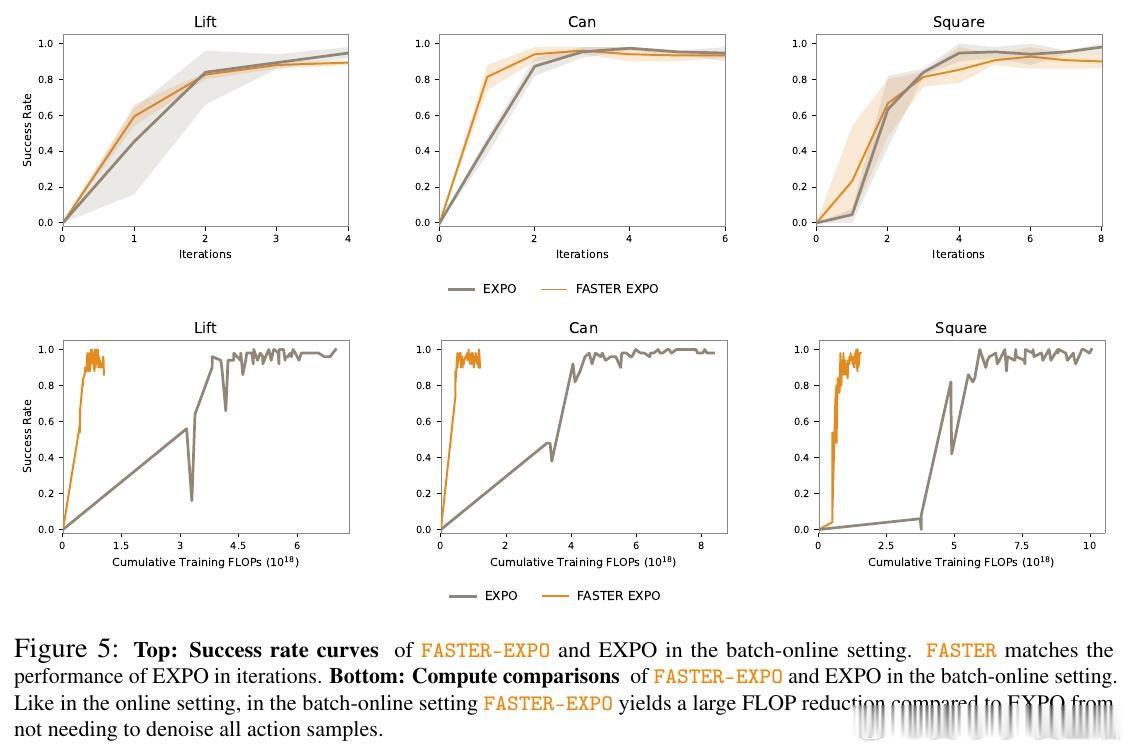
在强化学习中,基于扩散模型的策略虽然表现优异,但依赖采样多个动作候选并选择最优者的测试时缩放方法,导致计算成本高昂——每次推理需对所有候选完整去噪。这一瓶颈在大规模视觉-语言-动作模型中尤为严重,使得方法在延迟敏感场景下难以实用。
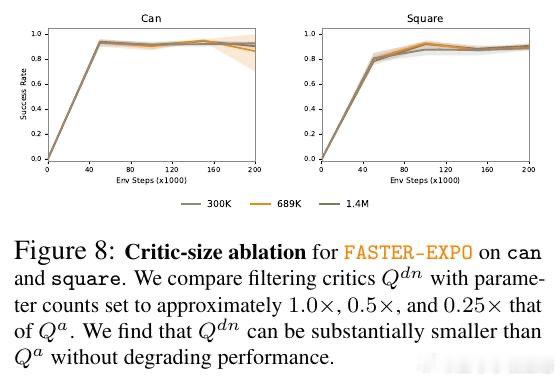
本文将多候选去噪与选择过程重构为马尔可夫决策过程:在去噪早期(甚至初始噪声阶段)就预测候选动作的下游价值,通过学习去噪空间的价值函数逐步过滤候选。关键操作是用动作级价值函数作为奖励信号,将结果信息反向传播至噪声空间,使模型无需完整去噪即可识别高质量样本。
这项工作的遗产是证明了采样方差主要由初始噪声决定,可在去噪前捕获。它为后续研究打开的门是:将测试时缩放的性能增益与计算开销解耦,使大规模生成式强化学习模型在保持性能的同时实现实用化部署。但尚未跨越的门槛是:该方法未改善样本效率,且仅适用于基于噪声种子的策略类别。
arxiv.org/abs/2604.19730 机器学习 人工智能 论文 AI创造营