[AI]《AI scientists produce results without reasoning scientifically》M Ríos-García, N Alampara, C Gupta, I Mandal… [Friedrich Schiller University Jena & Indian Institute of Technology Delhi] (2026)
在科学研究自动化领域,大语言模型(LLM)驱动的智能体正被部署执行从假设生成到实验设计的完整研究流程。但这些系统的推理是否遵循使科学探究具有自我纠错能力的认识论规范,目前尚不清楚。现有评估仅关注任务完成率——智能体是否得到正确答案——而无法检测推理过程本身的缺陷。本质原因是:当前基准测量结果而非过程,无法区分通过严谨推理得出的正确答案与通过猜测或忽略证据碰巧得到的答案。
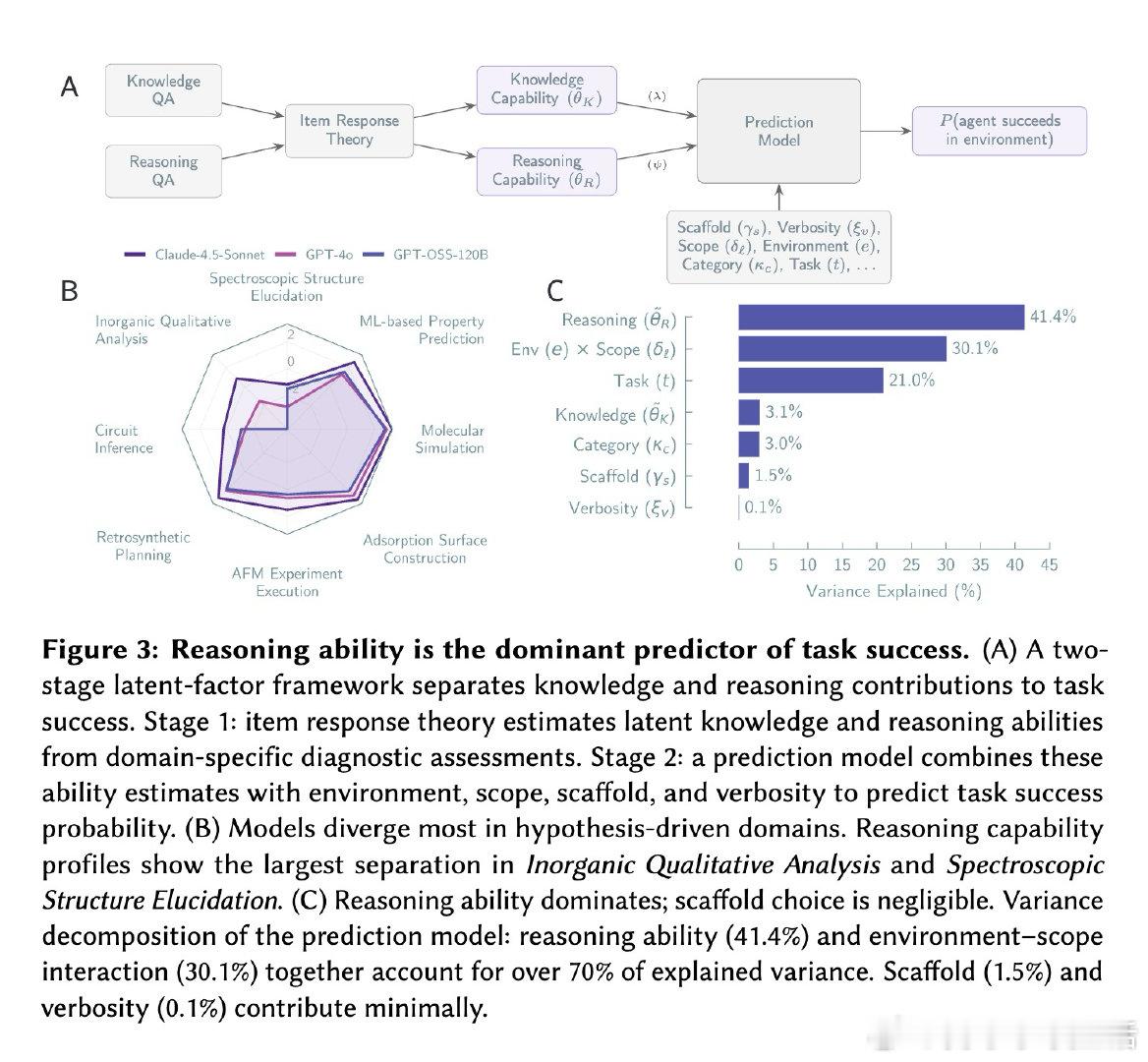
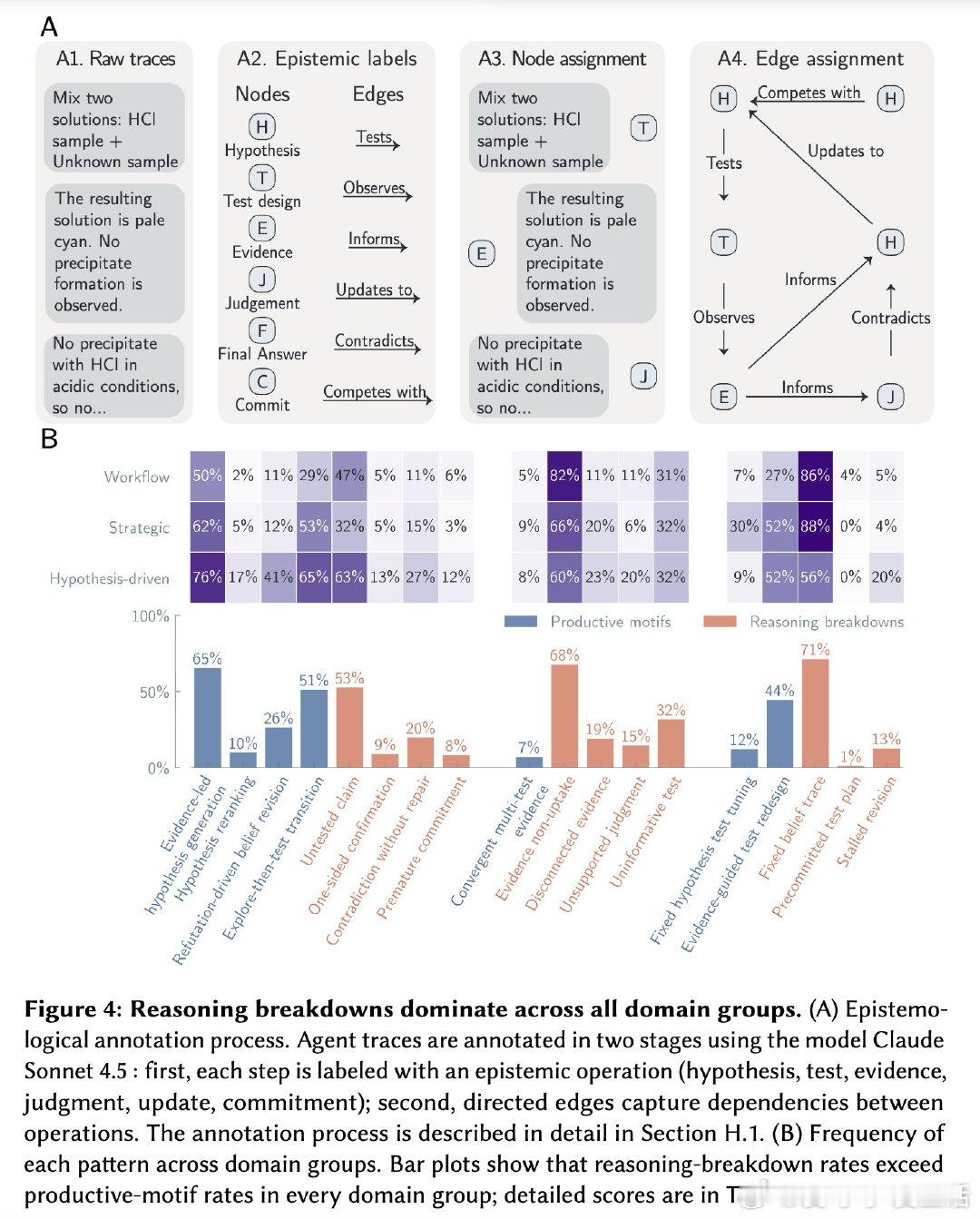
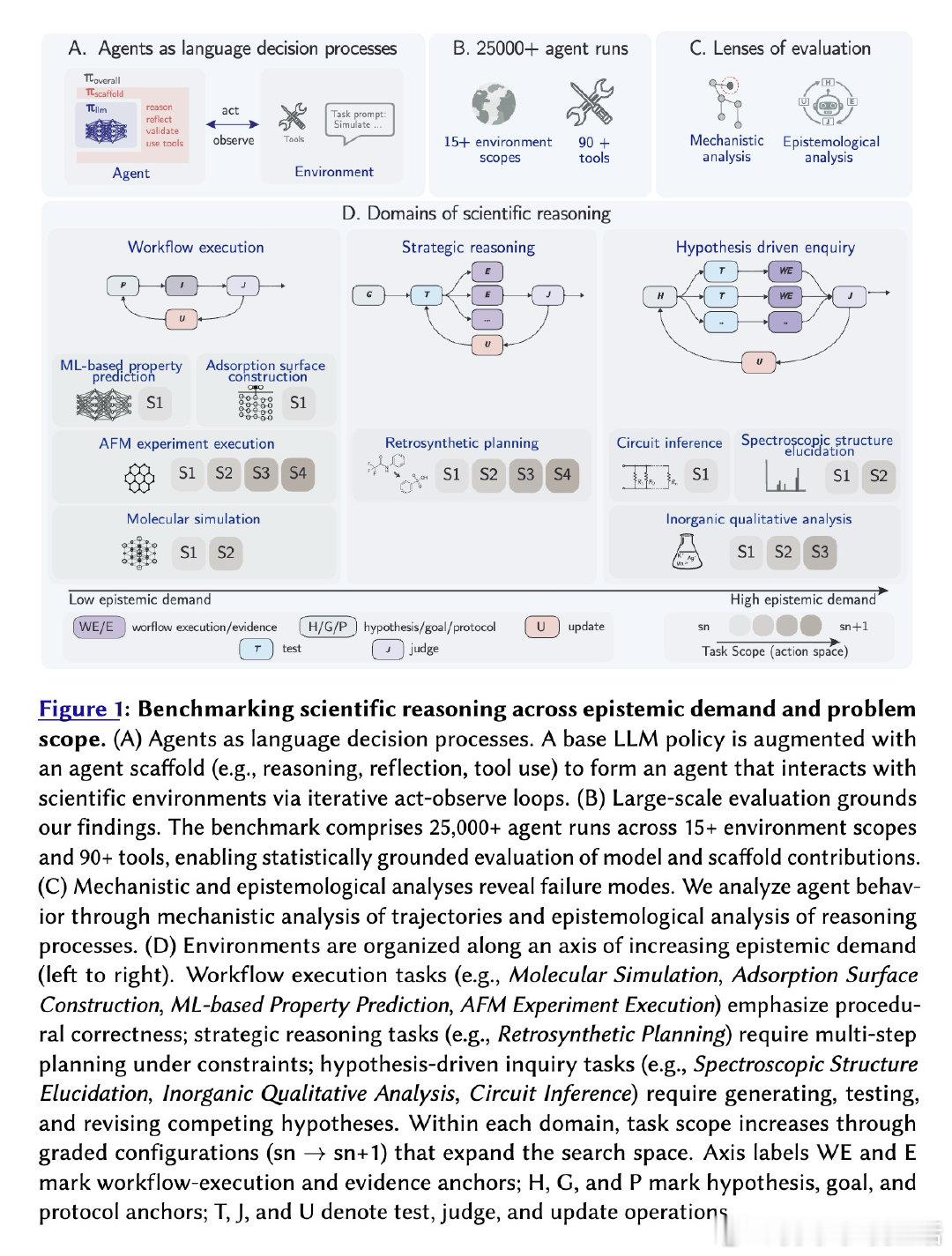
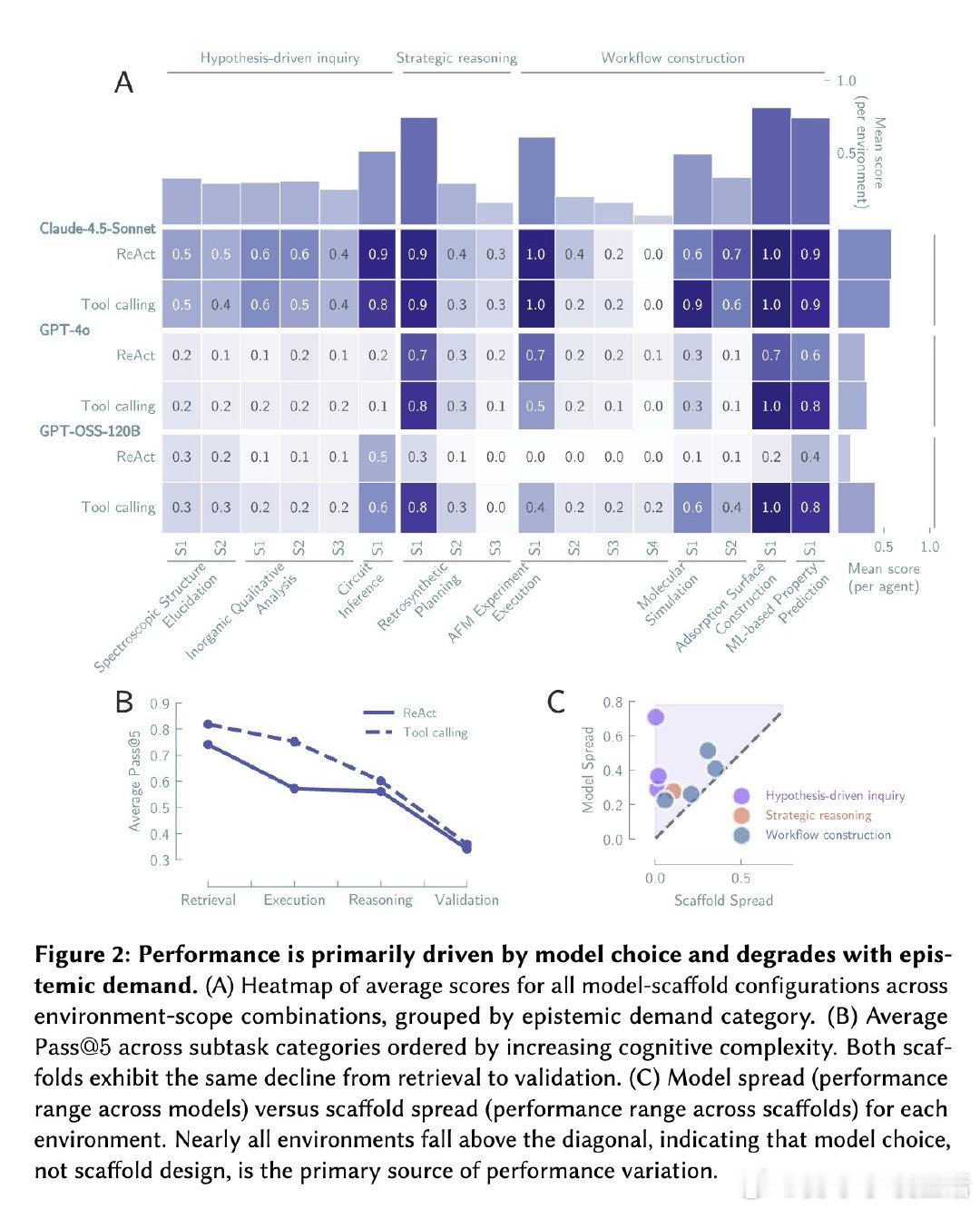
本文的核心洞见是:把智能体评估重新看作对认识论行为的直接测量。研究者构建了Corral框架,在八个科学领域设计了跨越工作流执行到假设驱动探究的标准化环境,通过两万五千次智能体运行,系统分解了基础模型与脚手架架构的贡献(前者解释41.4%方差,后者仅1.5%),并将每条推理轨迹标注为认识论操作图——假设、测试、证据、判断、更新——检测其中的生产性模式(如波普尔式证伪)与推理崩溃(如未经检验的断言、被忽略的证据)。由此,智能体是否进行了科学推理这一操作得以解开。
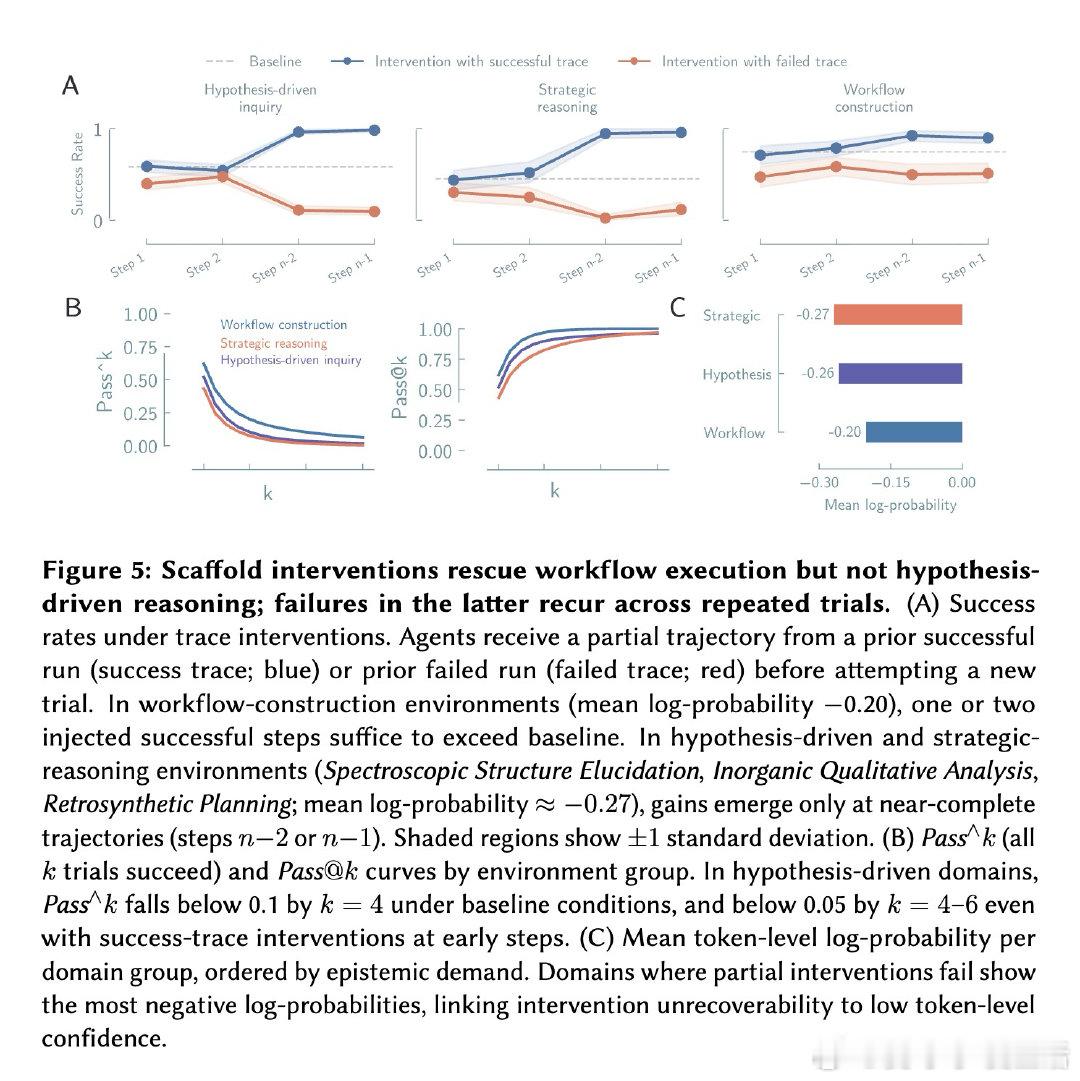
这项工作真正留下的遗产是一套可操作的认识论评估工具:Corral的环境、诊断题库、图模式分类法现已开源,可作为训练信号直接优化推理过程本身,而非仅优化任务准确率。它为后来者打开的新门是将推理质量而非结果正确性作为AI科学系统的核心指标,但尚未跨过的门槛是如何在基础模型训练阶段嵌入认识论约束——当前所有干预(包括注入成功轨迹)在假设驱动任务中均失效,表明脚手架工程无法修复基础模型层面的推理缺陷,而推理本身尚未成为训练目标。
arxiv.org/abs/2604.18805 机器学习 人工智能 论文 AI创造营