[CL]《Decoupled DiLoCo for Resilient Distributed Pre-training》A Douillard, K Rush, Y Donchev, Z Charles… [Google DeepMind] (2026)
在大规模语言模型预训练中,传统的单程序多数据(SPMD)范式要求所有加速器严格同步。这种紧耦合导致任何单点硬件故障或掉队者都会拖垮整个集群,在百万级芯片规模下,罕见故障变成常态事件,造成大量计算浪费。
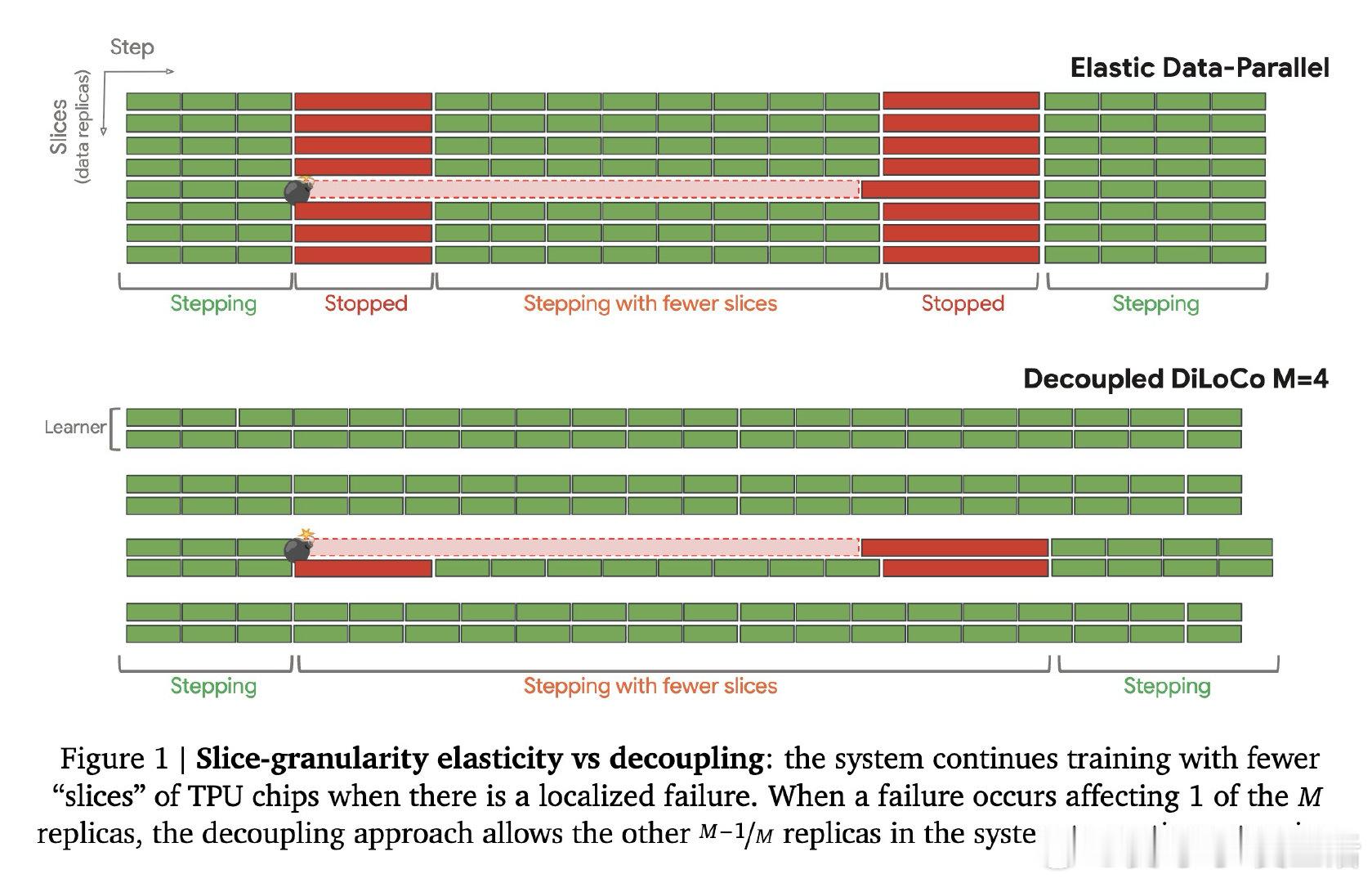
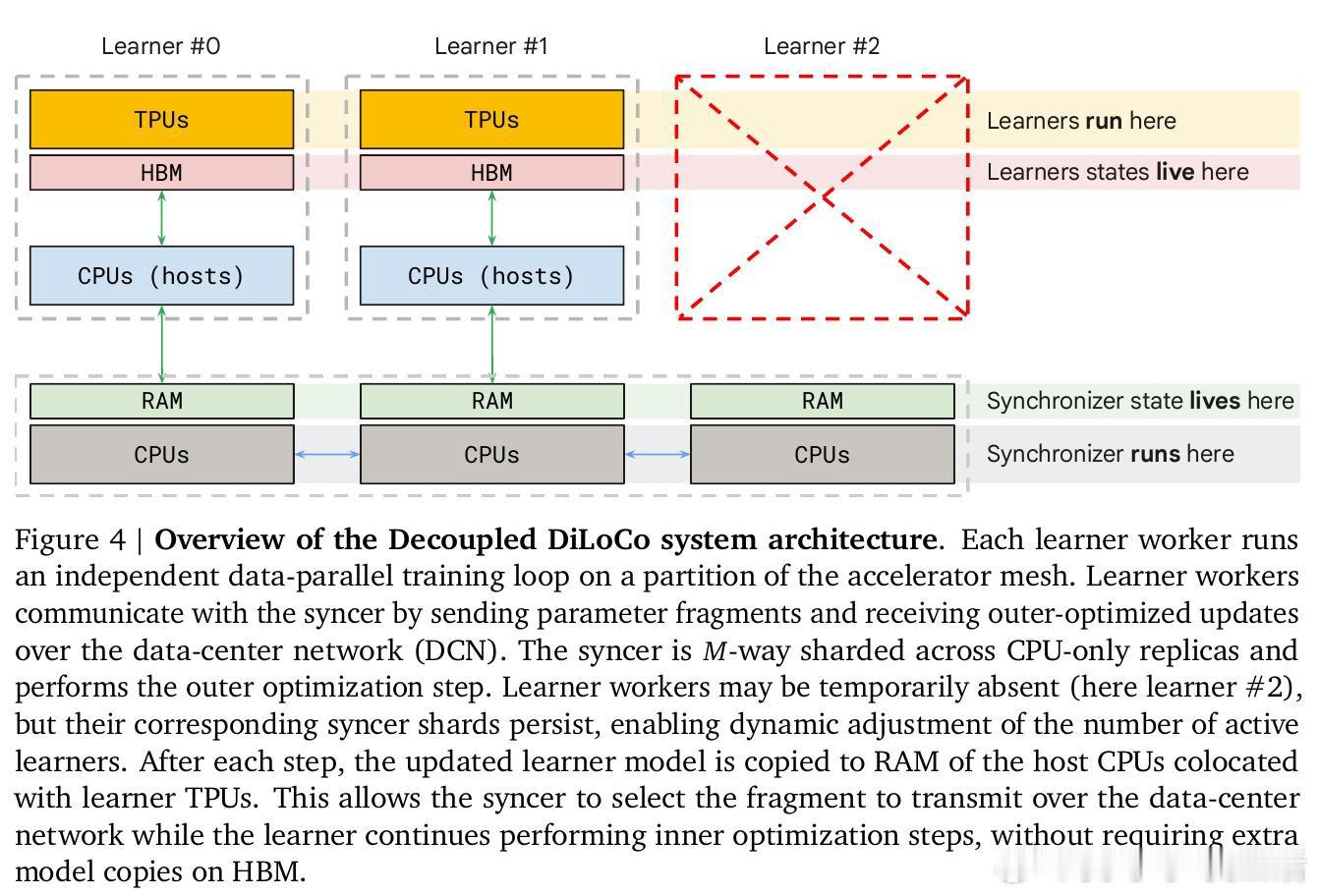
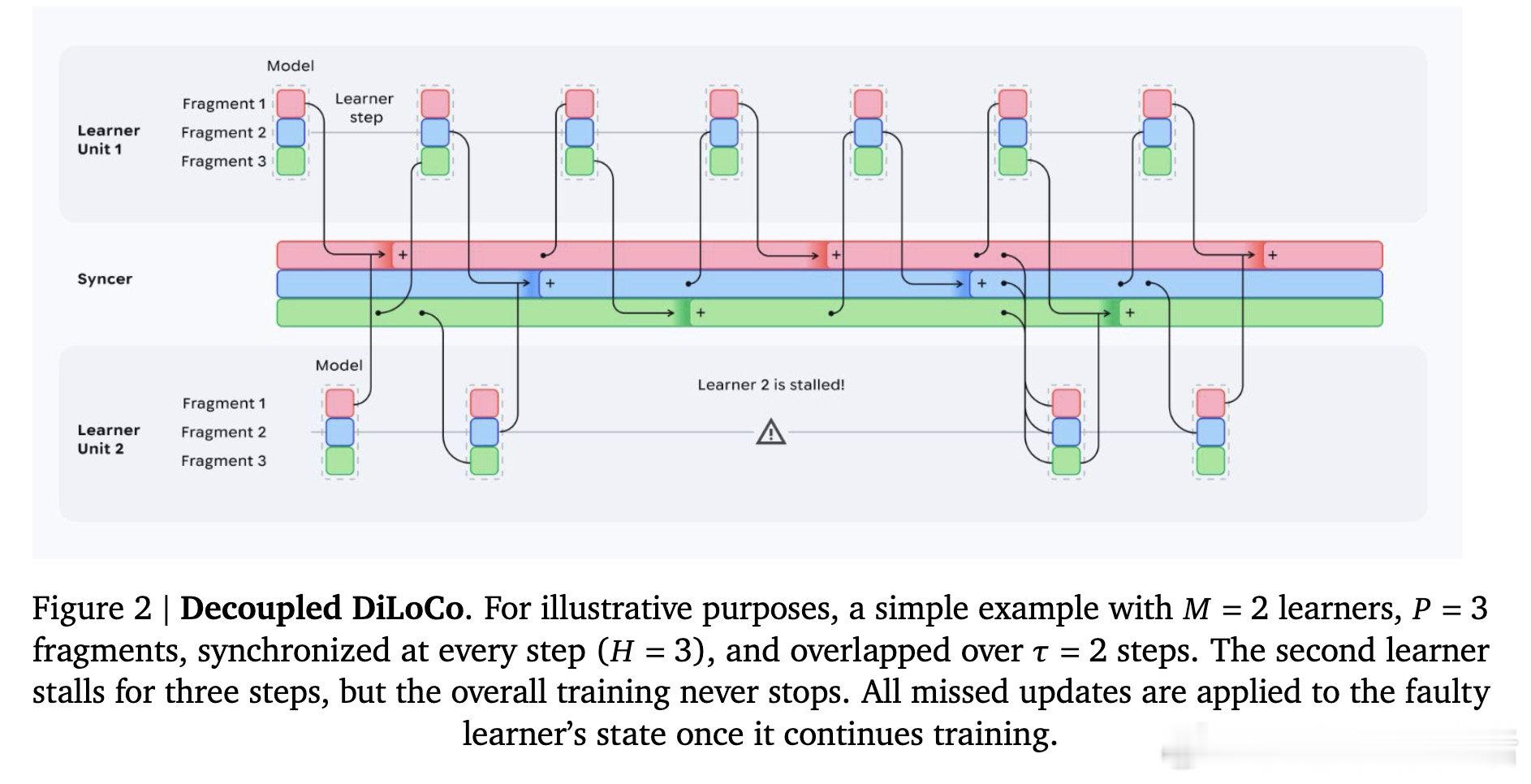
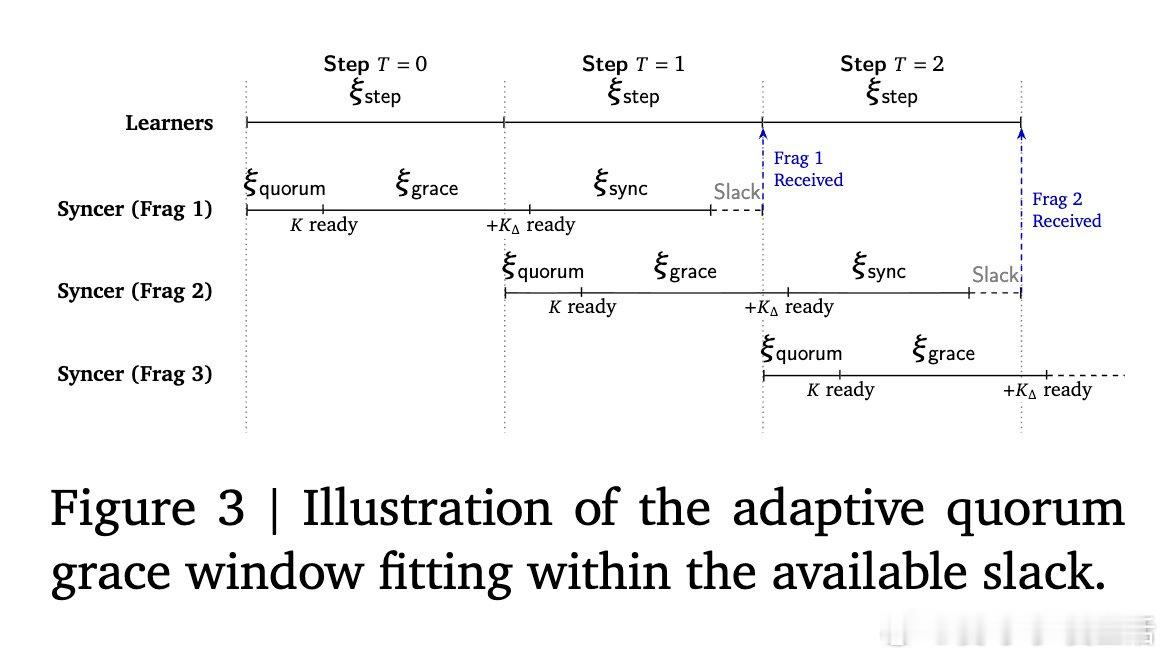
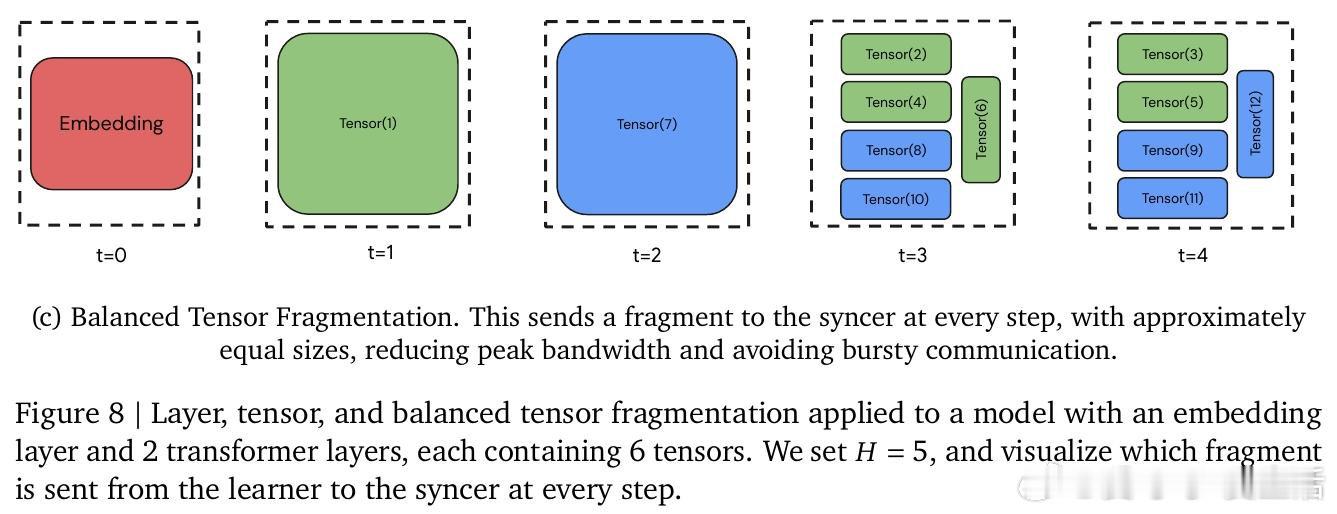
本文将预训练集群拆解为多个独立的"学习器",各自异步执行本地优化。核心机制是中央同步器采用最小法定人数聚合、自适应等待窗口和动态令牌加权合并,绕过故障或掉队节点,将参数碎片异步传递给学习器,打破了锁步同步的枷锁。
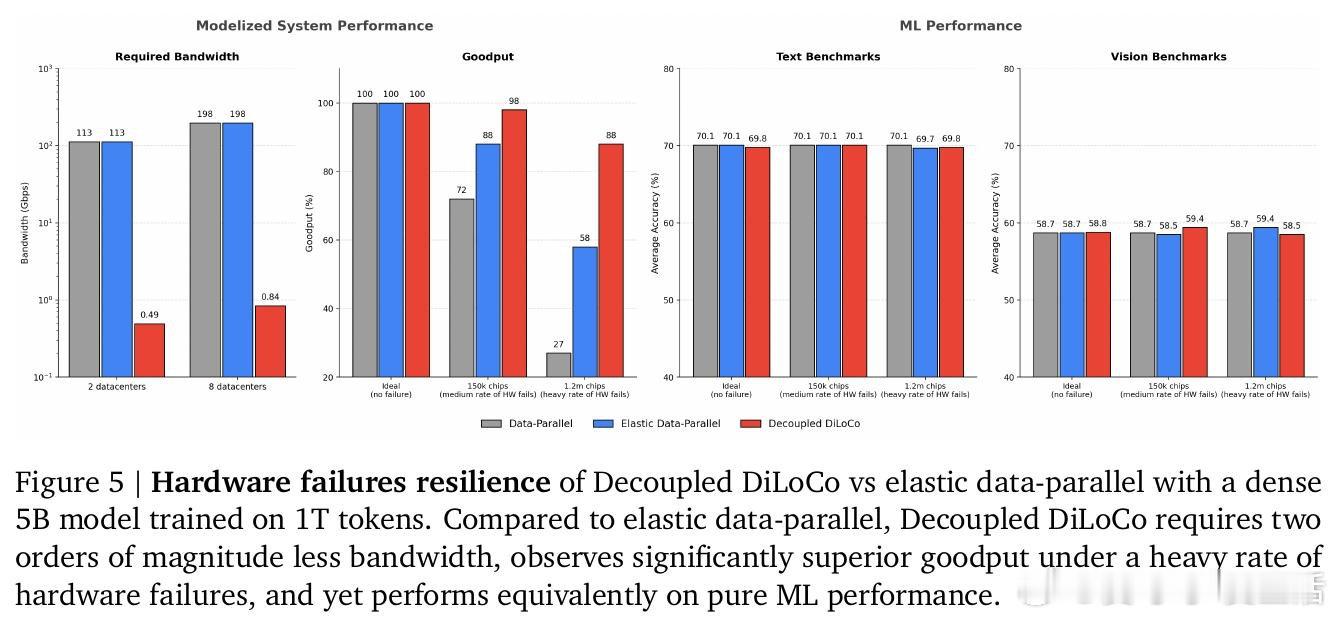
这项工作证明了在混沌环境中(模拟百万芯片零全局停机)可实现88%的有效算力利用率,同时在文本和视觉任务上保持与数据并行相当的模型性能。它为后来者打开的新门是:在带宽受限和硬件不可靠的地理分布式集群中进行预训练成为可能。但尚未跨过的门槛是:在更大规模和更复杂的专家混合架构下,异步训练的稳定性和收敛性保证仍需验证。
arxiv.org/abs/2604.21428
机器学习 人工智能 论文 AI创造营