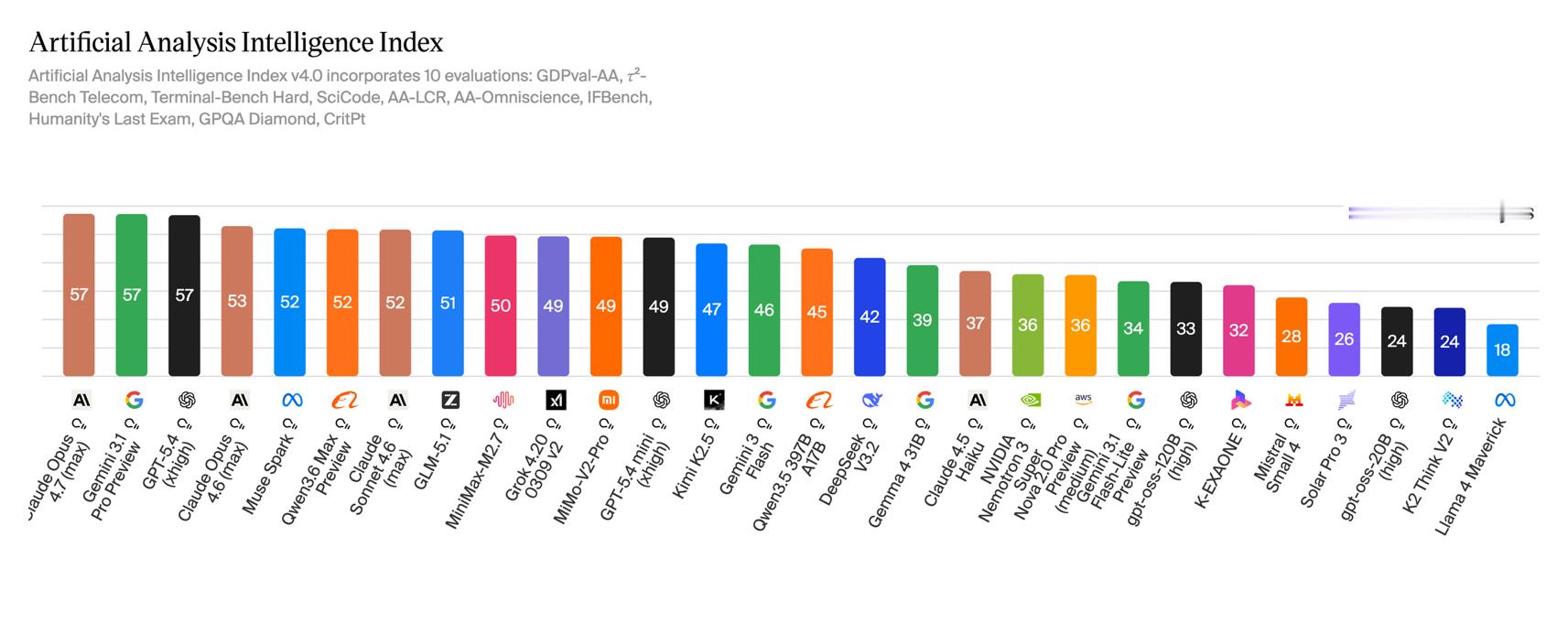
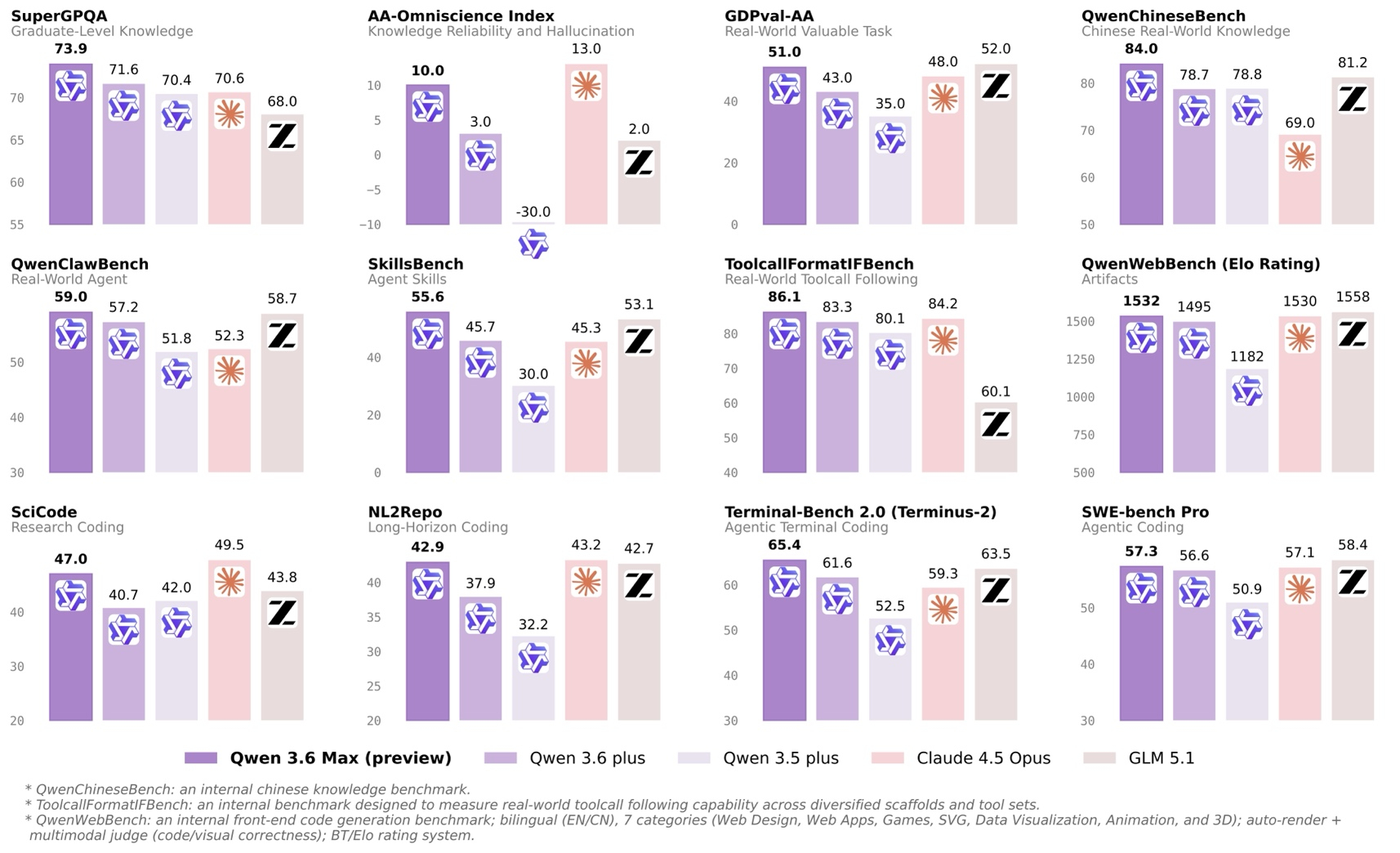
阿里今天发了Qwen3.6-Max-Preview,跑分确实挺好看。
📮编程上SciCode 47分、SWE-bench Pro 57.3分,已经咬住Claude 4.5 Opus了,部分benchmark还反超。Agent工具调用、知识问答这些可量化的能力,国产模型追赶速度真的快——一个月前大家还说差距半年,现在再说已经是几周。(Claude 最新是 4.7 Opus
📮但我自己用下来最在意的那个维度——语言能力,跑分图上看不出来。我写文案、改稿子、做创意性表达这些场景,Qwen系列的输出跟Claude比还是有差距。不是错字不是语病,是那种说不出哪里不对但读起来就是没那味儿的感觉——比喻生硬、节奏一板一眼、该留白的地方填满了、该收束的地方又散掉了。这种「味儿」,不会在任何一张benchmark表格里出现。
📮文科生的分数其实比理科生难评价多了。数学98分和93分,98确实就是比93强,这个差别是客观的。
但文学创作不一样。有时候98分的作文反而读起来不如93分的,因为那5分可能是在「规范性」上加的,而减掉的是「个性」。现在AI的跑分体系,本质上在奖励前者——可检测、可复现、可量化。所以当一个模型在跑分上全面超越对手,但你读它写的东西总觉得少点什么——这不一定是你的错觉。
📮还有一个角度是应用层。
我最近在用的是智谱GLM 5.1,跑分上也挺猛,编程能力已经跟Claude一个档。但我用下来最大的问题是会话长度——聊着聊着就得开新窗口,Claude里一个项目能滚十几天不断,GLM里一两天就顶到头了。
这不一定是模型架构的问题,更像是产品工程层面的取舍——上下文窗口、长会话稳定性、工具调用时的记忆保持,这些不是benchmark分数能解决的。国产模型在「底座」上已经追得很近,但在「产品打磨」这一层,跟Claude、ChatGPT这种迭代三四年的老产品比,还有6到12个月的差距。
📮所以我的判断是——理科生的分数我信了,文科生的分数我再观望,工程师的活还没做完。
Qwen3.6-Max正式版和GLM下一代出来再试试。现在这个阶段,跑分看着热闹,但你真的把它放进日常工作流里用一个月🌚还得是 Gemini 和 Claude 香