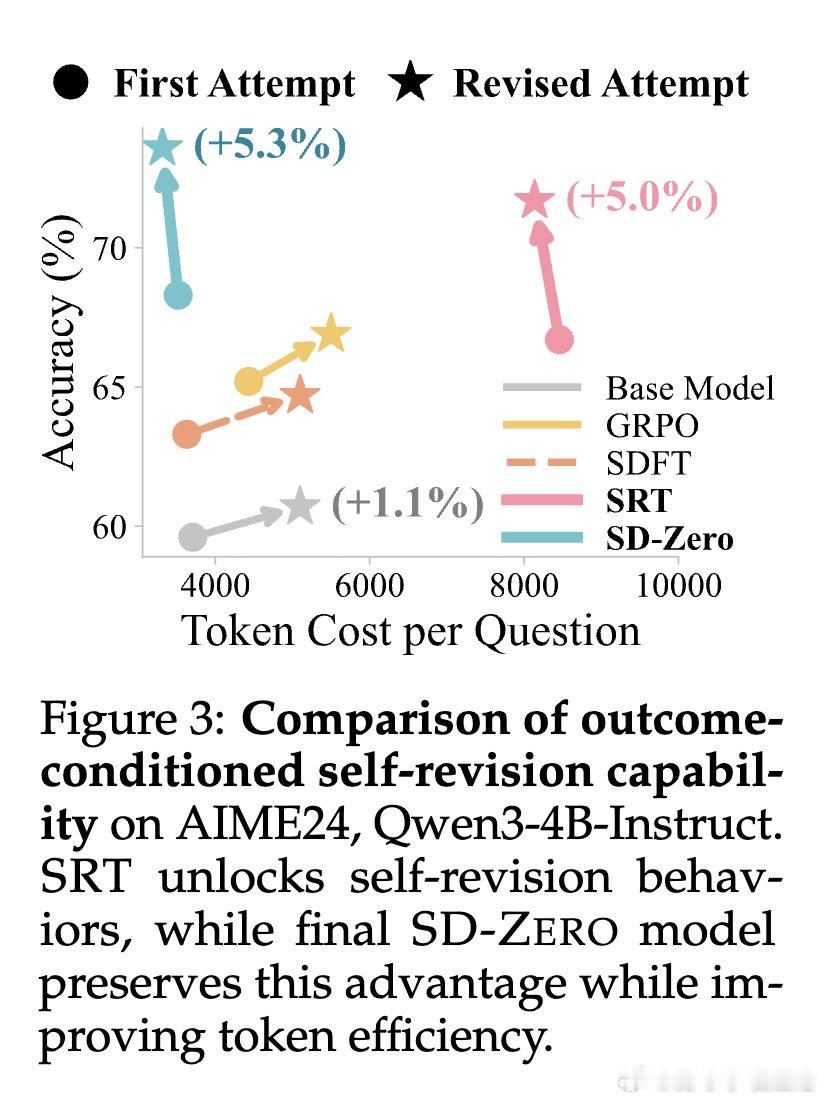
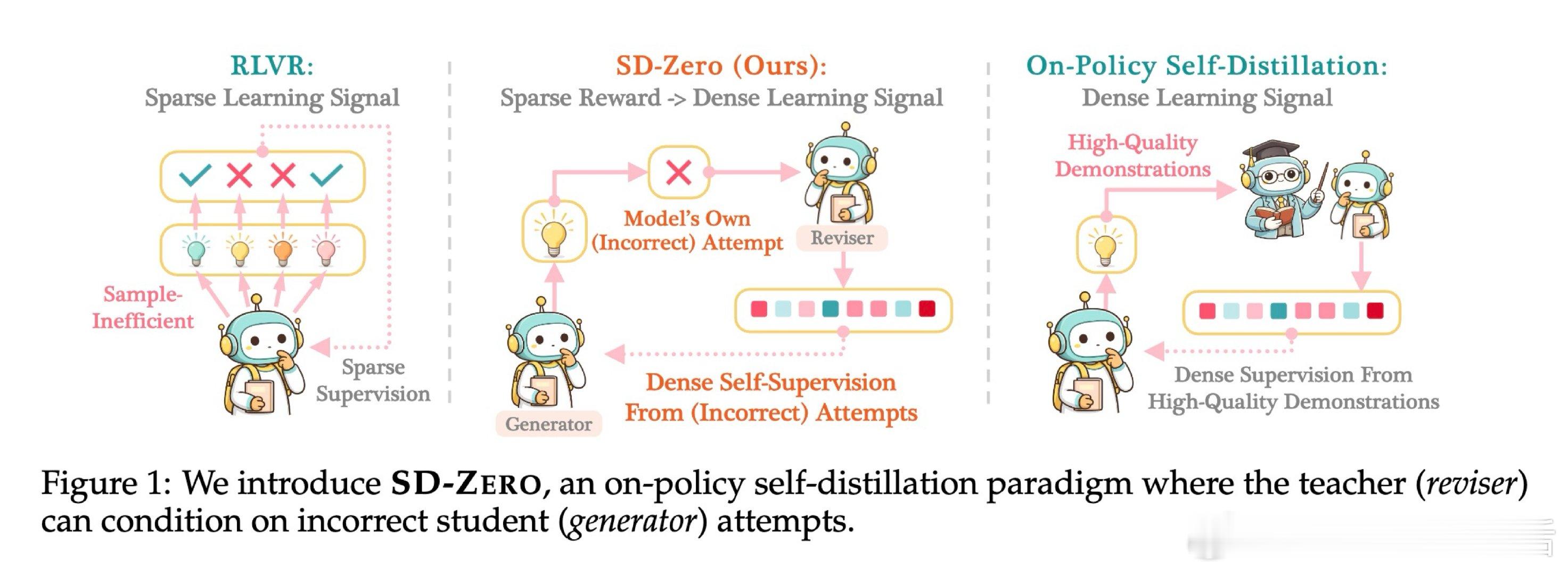
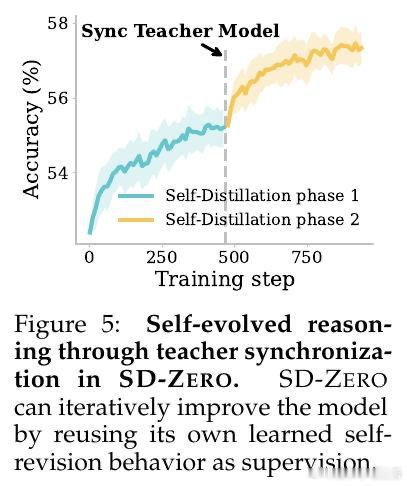
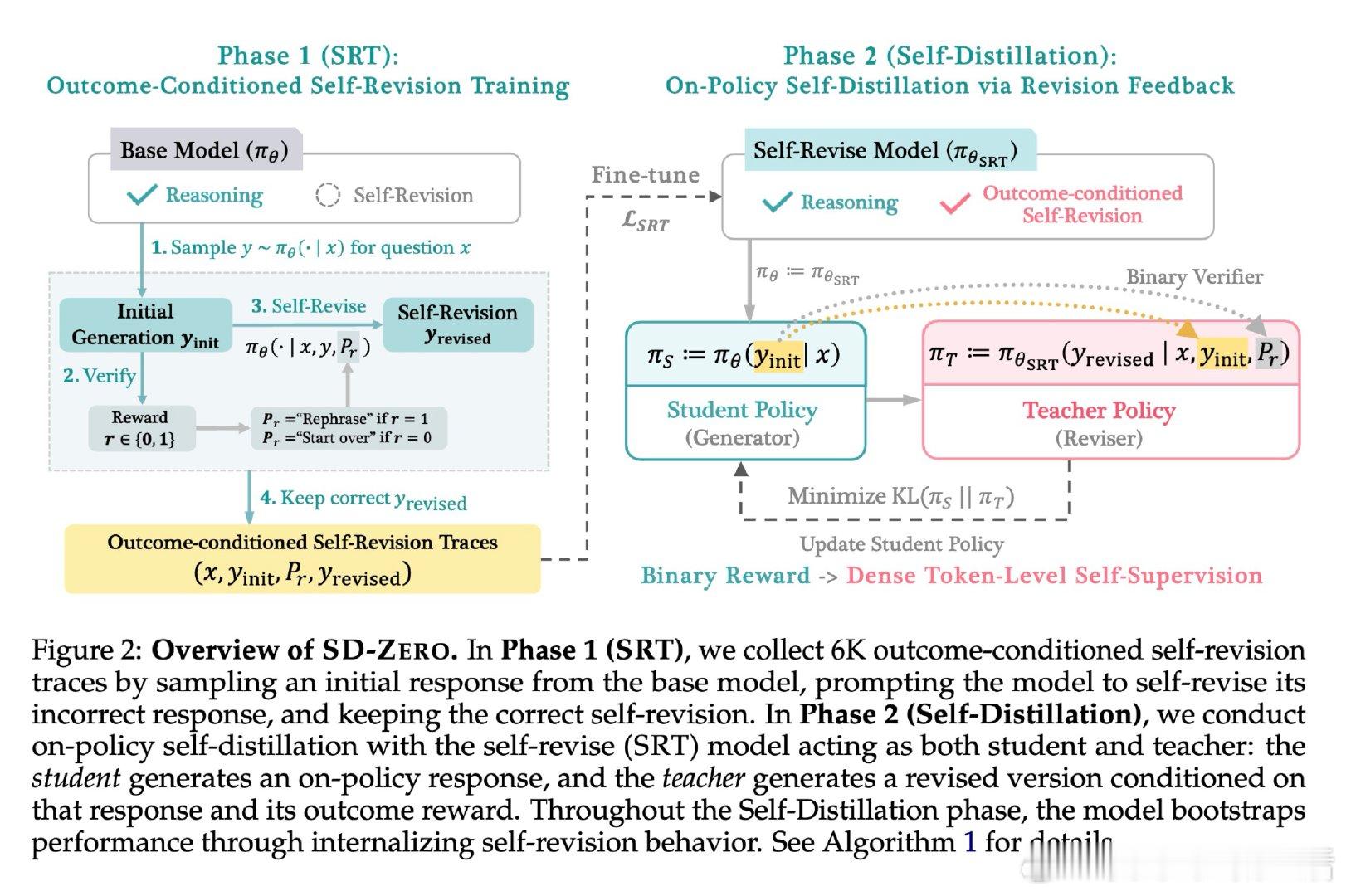
[CL]《Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision》Y He, S Kaur, A Bhaskar, Y Yang… [Princeton University] (2026)
在语言模型后训练领域,如何从有限的监督信号中榨取更多学习效率,是一个悬而未决的难题。强化学习方法受困于稀疏的二元奖励——模型只知道答案对错,却不知道推理链条哪里出了问题;蒸馏方法虽然信号密集,却需要外部教师或高质量示范数据,成本高昂甚至无从获取。
本文的核心洞见是:把"修改者"重新看作"教师"。同一个模型,既扮演生成初始答案的学生,又扮演看到答案对错后进行修订的修改者——修改者的逐词概率分布,就是天然的密集监督信号。由此,将修改者的行为蒸馏回生成者这一关键操作,使稀疏二元奖励转化为可直接反向传播的词级监督成为可能。
这项工作真正留下的遗产,是证明了模型可以通过自我修订能力完成自举——无需外部教师,无需高质量示范,仅凭对错信号就能持续迭代提升。它为后来者打开的新门是:迭代自我进化的可行性——训练改善了修订能力,改善的修订能力又能成为更强的教师,循环自我增强。但尚未跨过的门槛是:如何将这一范式延伸至无法验证对错的开放领域,以及如何在具有长链思维的推理模型中区分"有效探索"与"真正错误"。
arxiv.org/abs/2604.12002
机器学习 人工智能 论文 AI创造营