[LG]《LongCoT: Benchmarking Long-Horizon Chain-of-Thought Reasoning》S R Motwani, D Nichols, C London, P Li… [University of Oxford & Lawrence Livermore National Laboratory (LLNL)] (2026)
在长链推理领域,模型究竟能走多远是一个悬而未决的难题。过去的评测受困于"问题难但推理链短"的矛盾——要么考察艰深知识,要么依赖工具脚手架,始终无法单独盯住模型在数万乃至数十万推理词元里保持连贯的那项能力,本质原因是缺乏一把专门测量"长途不掉链"的尺子。
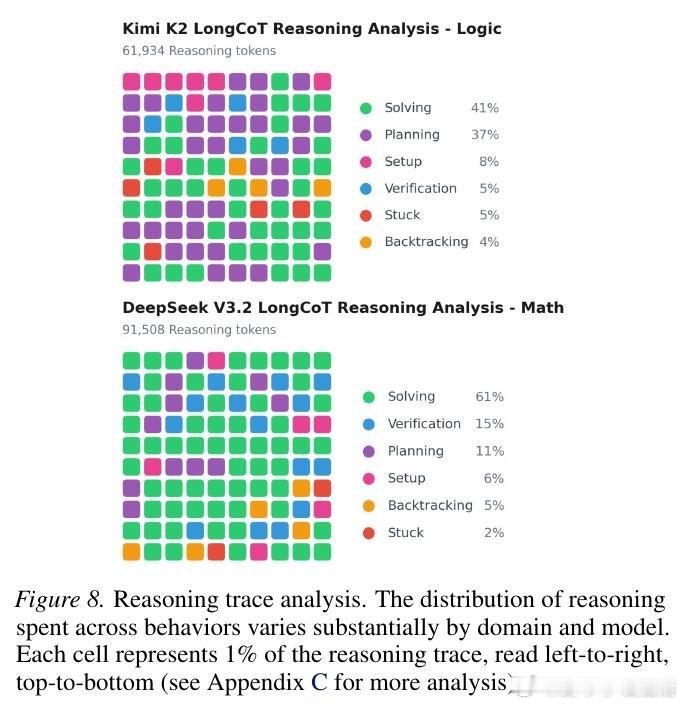
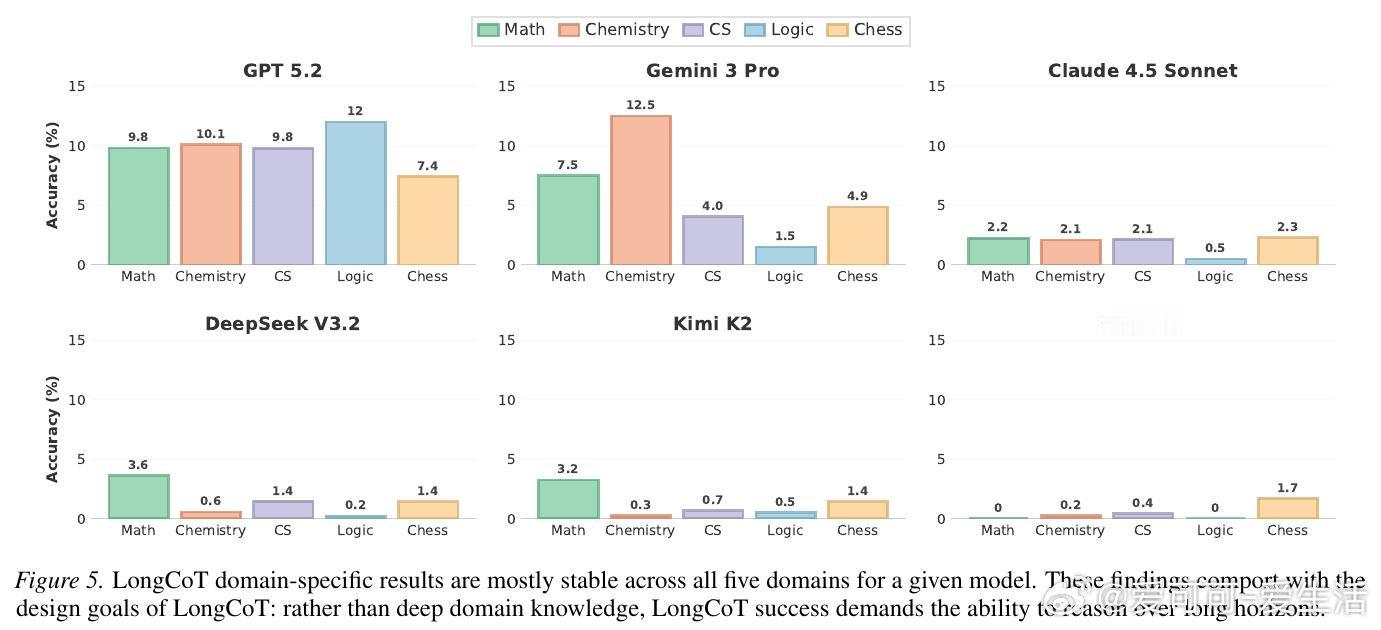
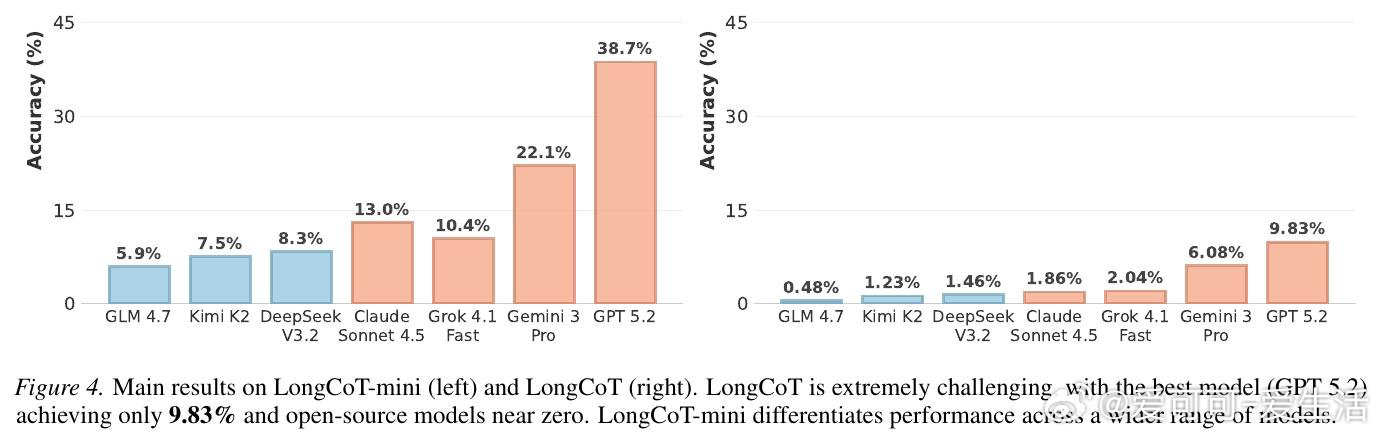
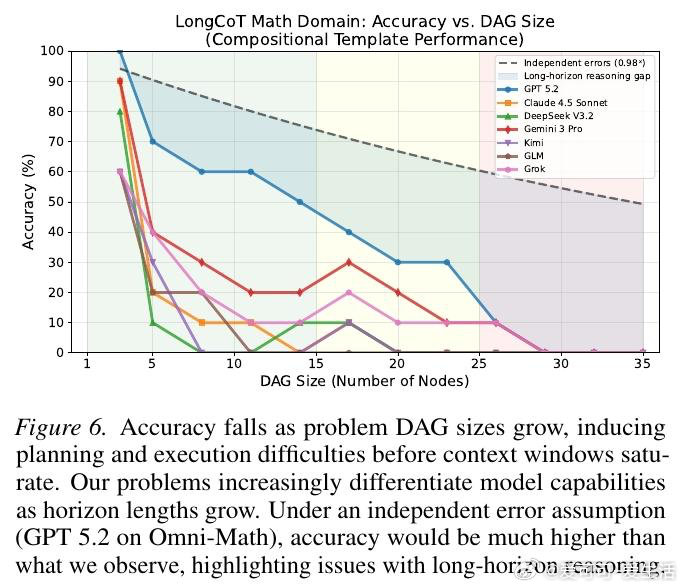
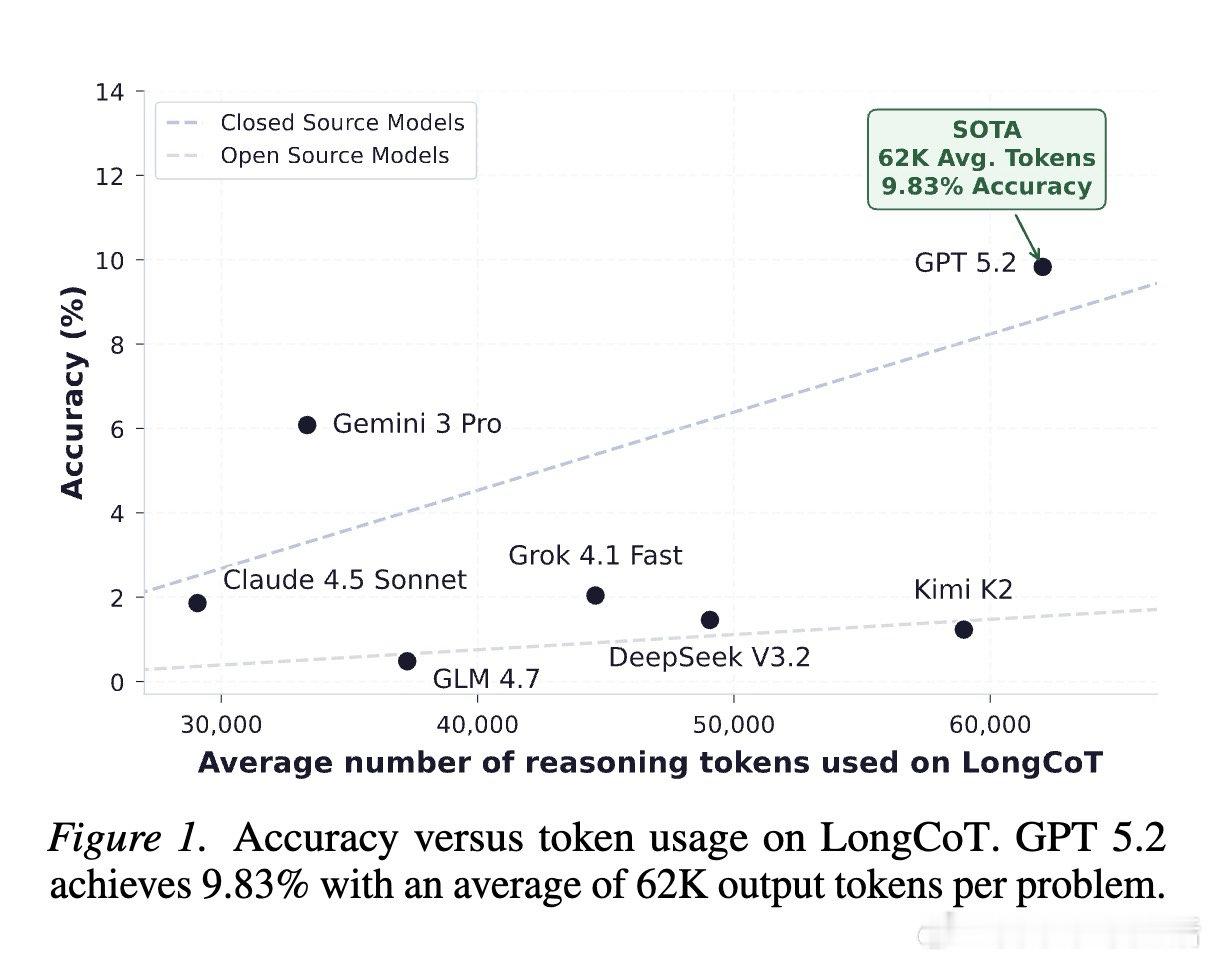
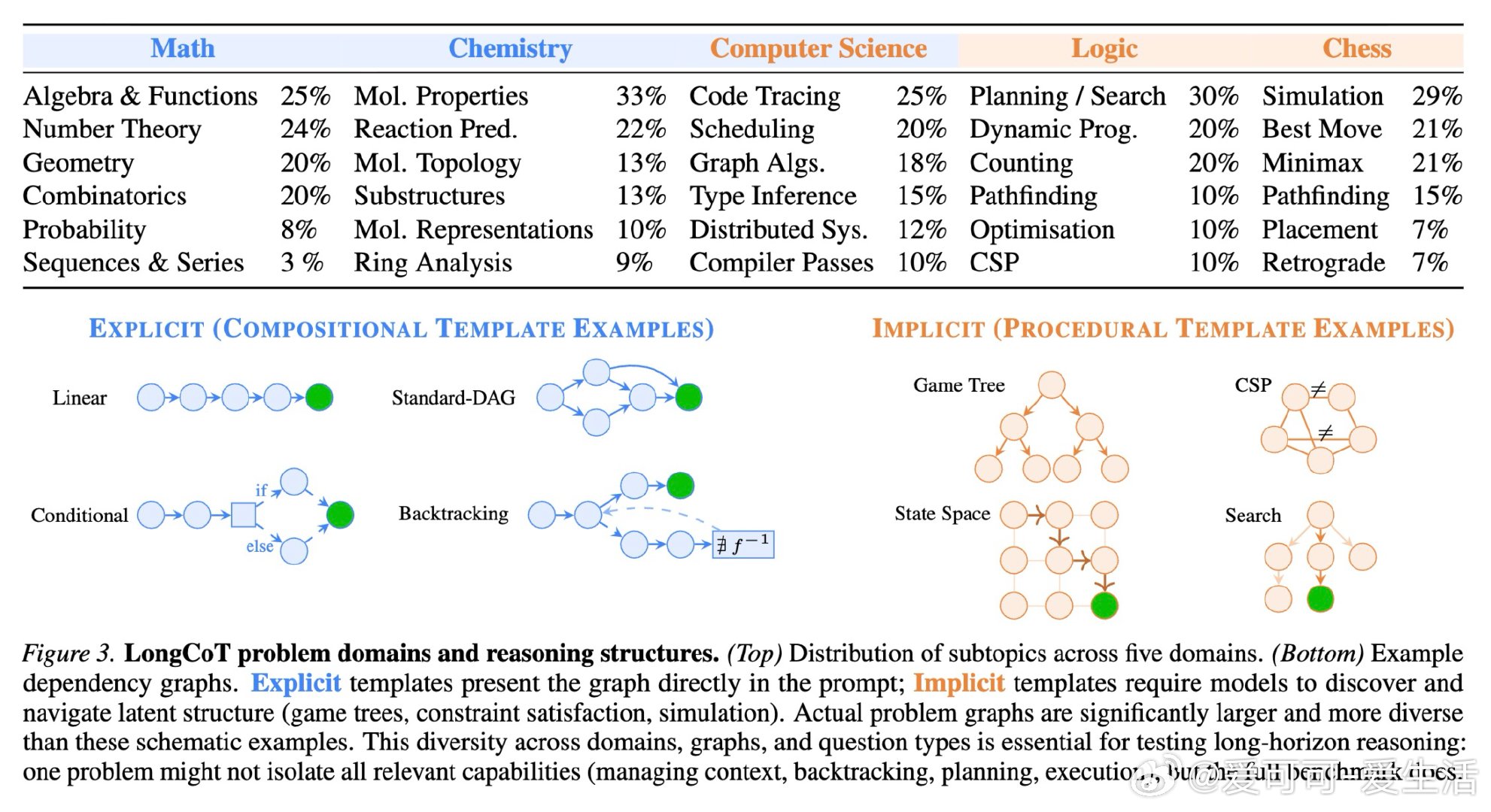
本文的核心洞见是:把"长推理"重新看作一张需要遍历的依赖图——每个子问题是节点,答案传递是边。由此,将2500道题设计成短输入、长输出、且每一步局部可解的图结构,使得最终的10%以下准确率只能归因于长程推理本身的崩塌,而非单步难度或外部工具的缺席。
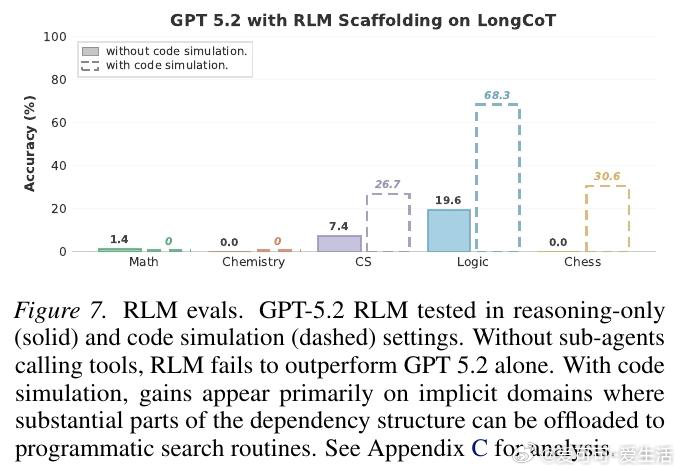
这项工作真正留下的遗产是:首次将长链推理能力从"问题难度"与"智能体脚手架"两个干扰项中剥离出来,单独立档测量。它为后来者打开的新门是:针对规划保持、状态追踪与错误纠偏的专项训练与推理方法——而非笼统的扩大上下文窗口。但尚未跨过的门槛是:高昂的评测成本(每题约1美元)使得pass at k与自洽性统计至今缺席,且模型能否在训练中真正内化长程依赖,仍是未解之题。
arxiv.org/abs/2604.14140
机器学习 人工智能 论文 AI创造营