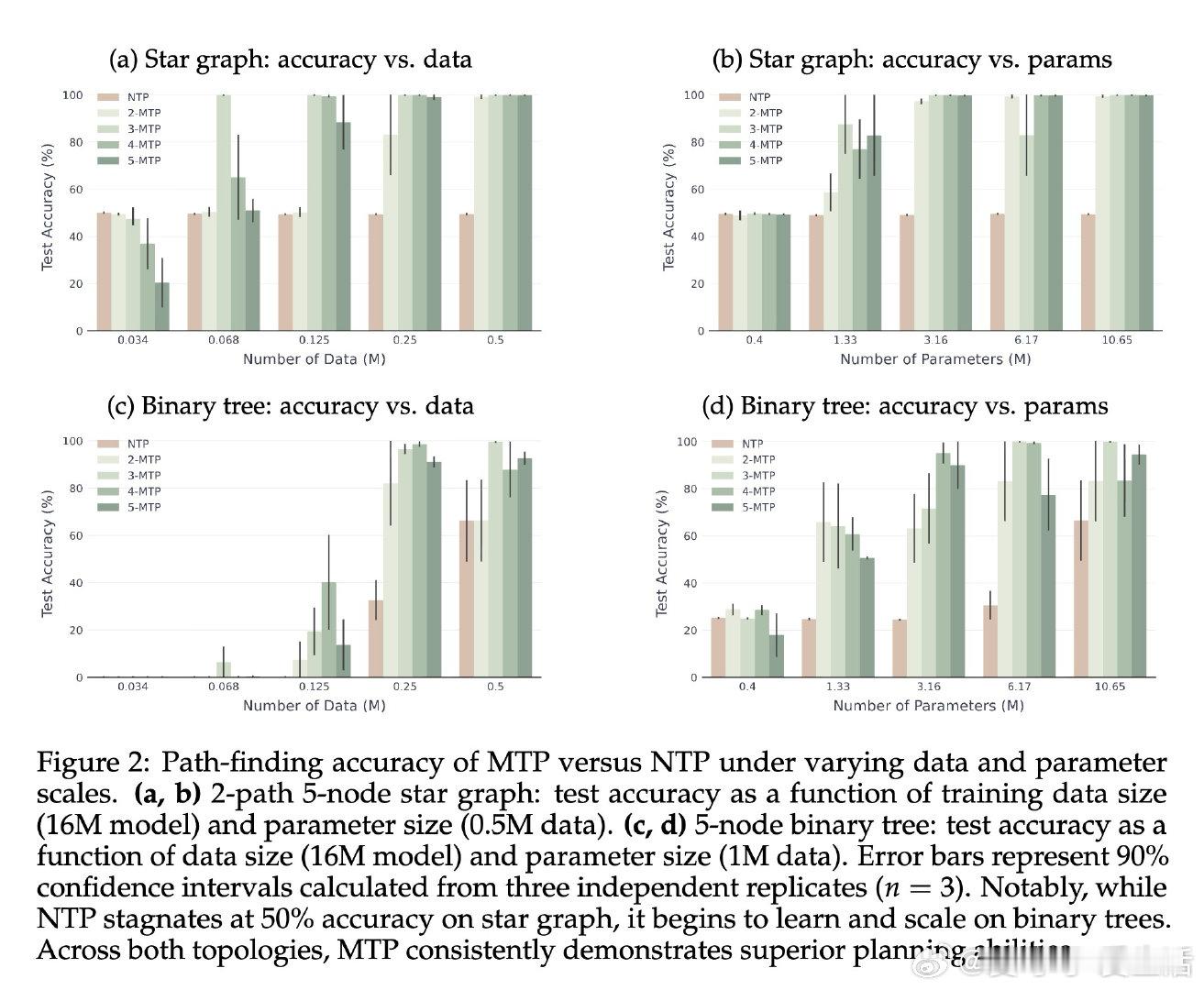
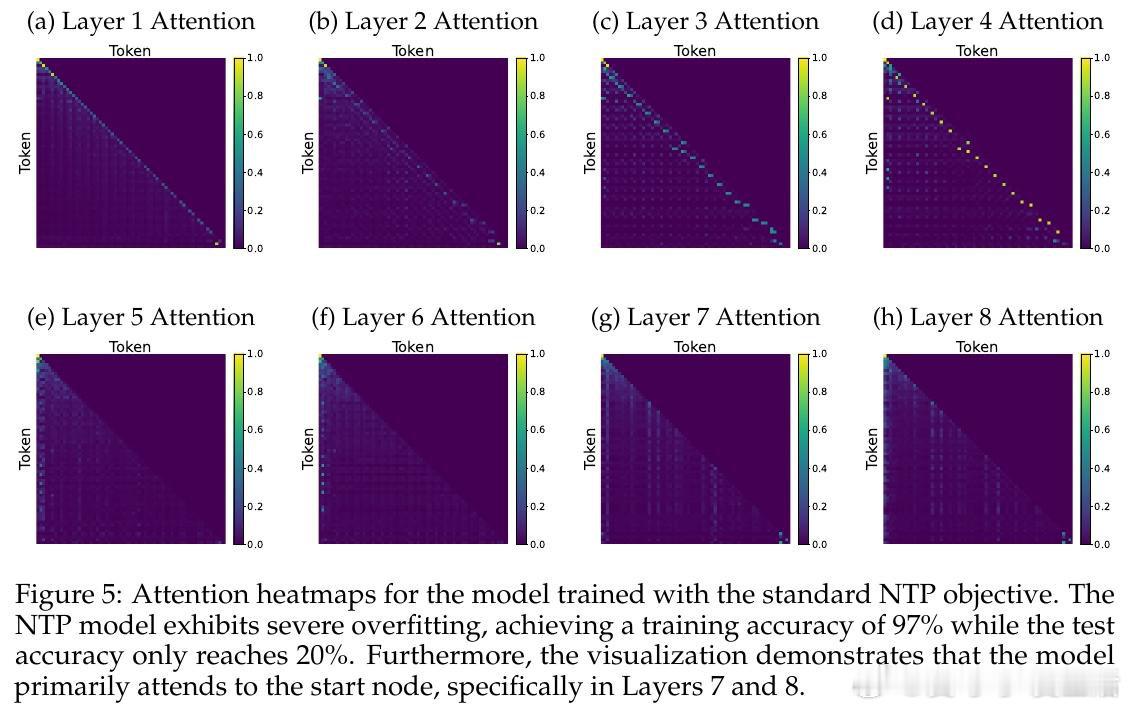
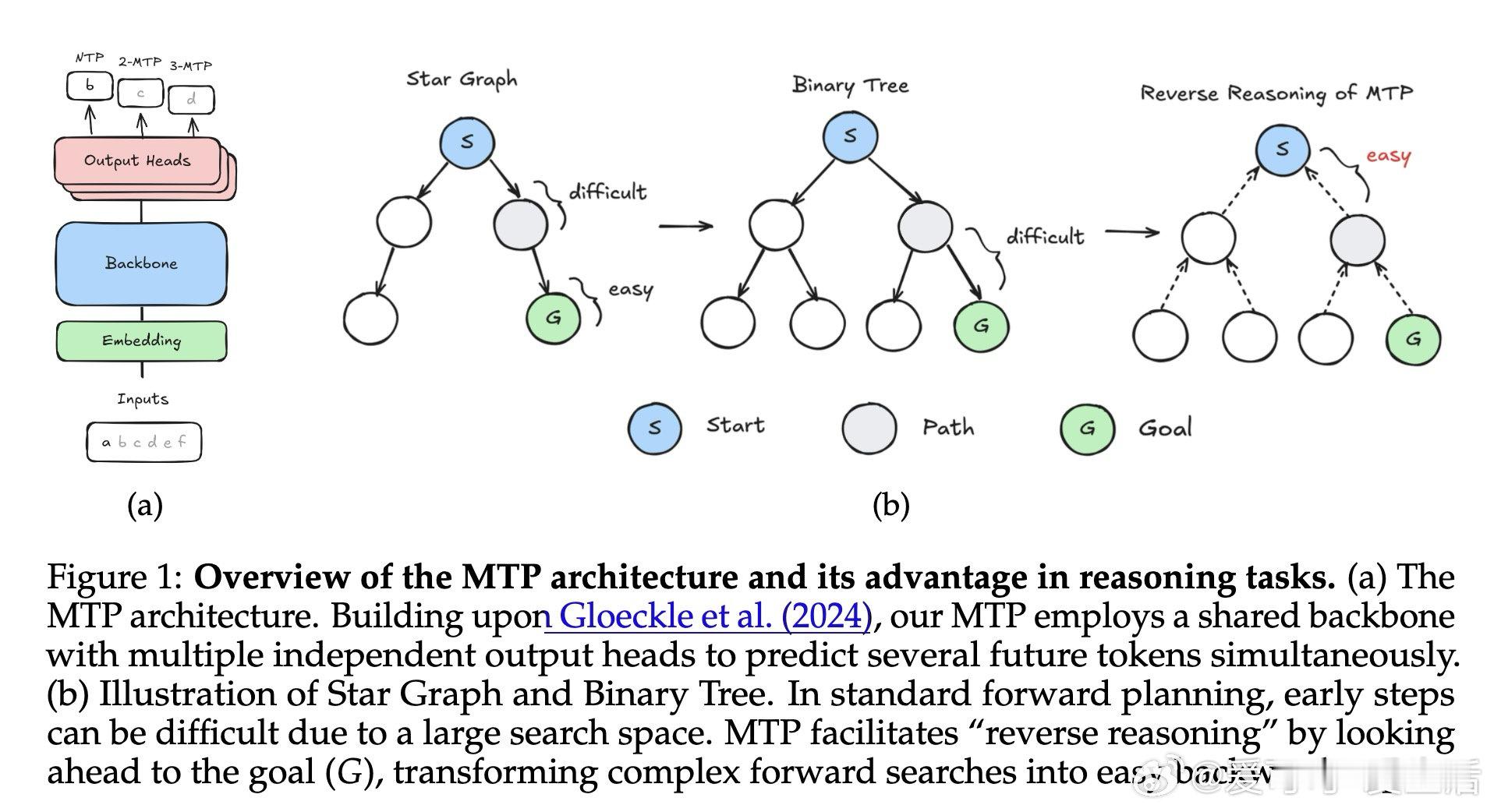
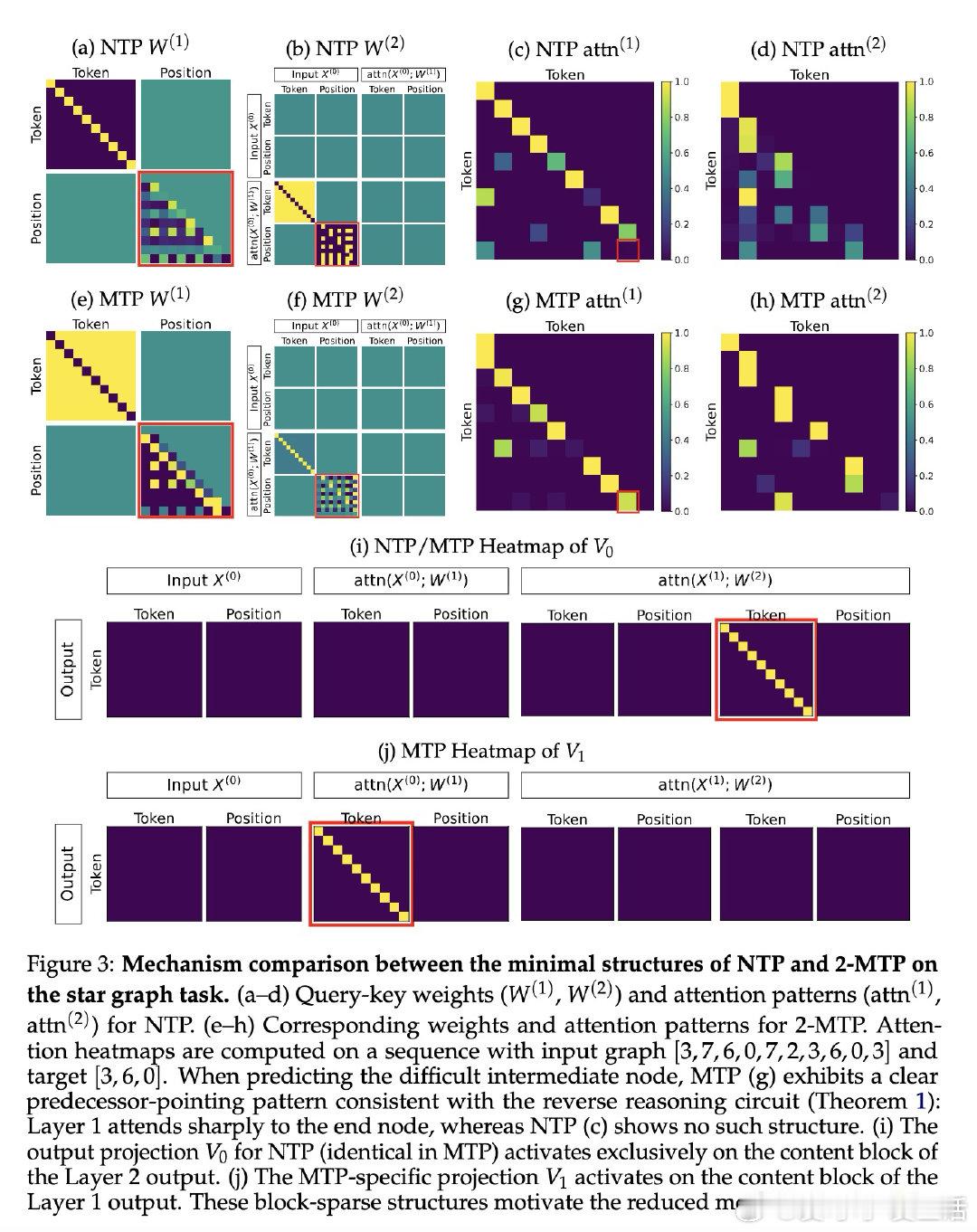
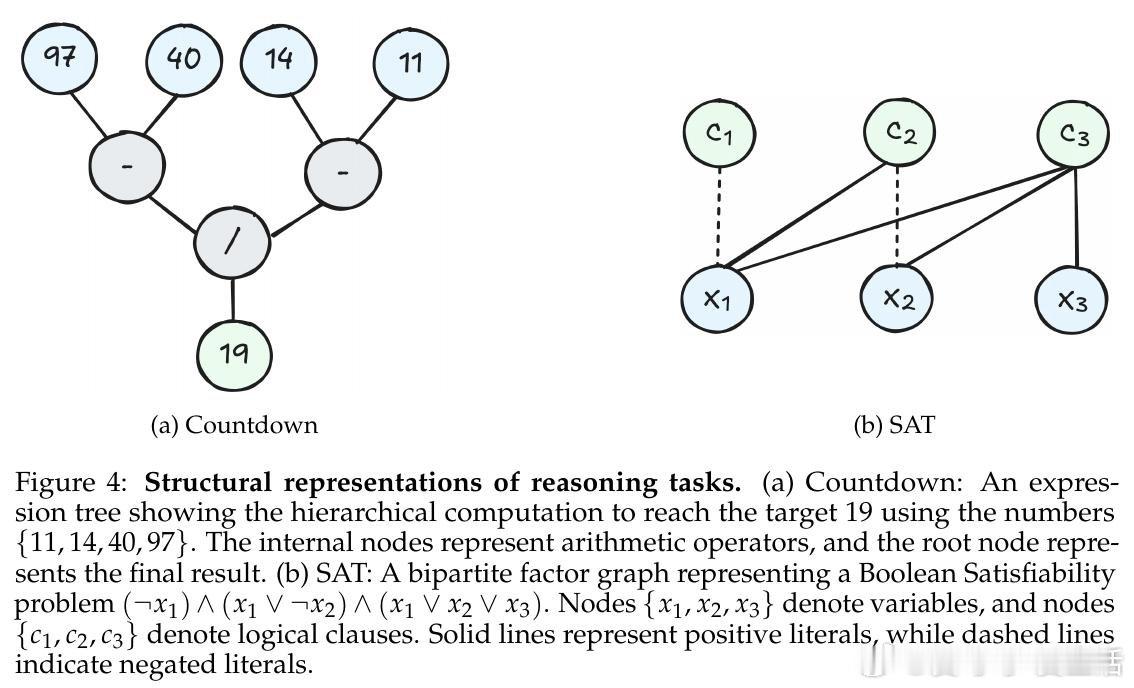
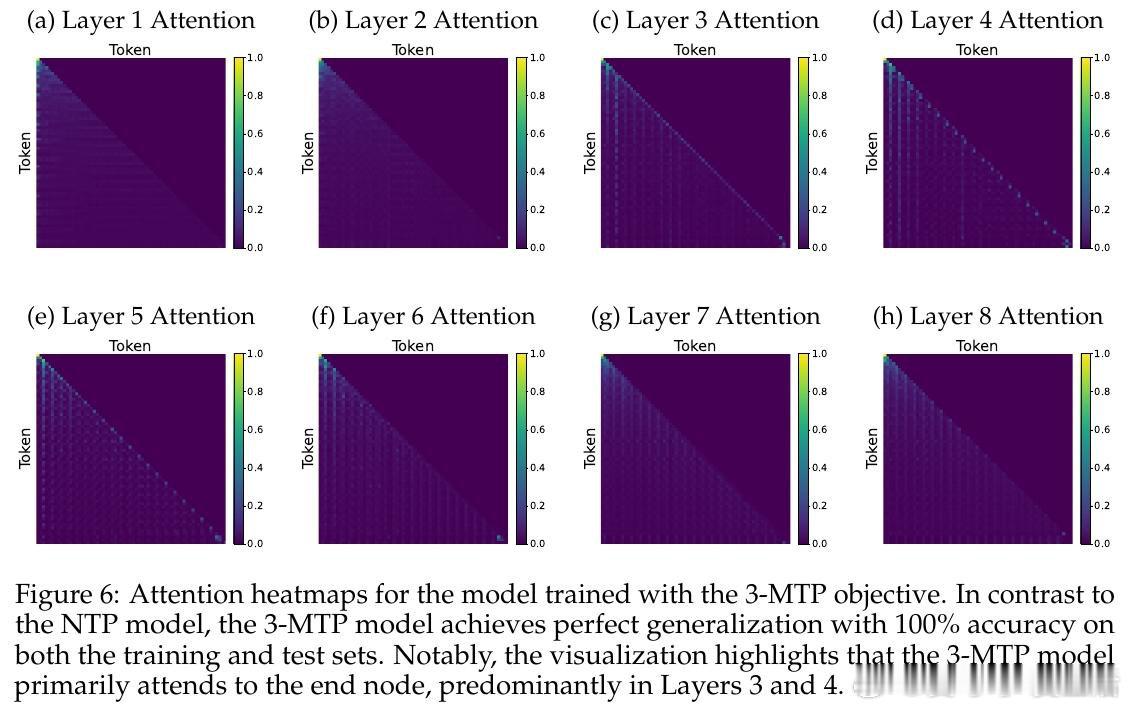
[LG]《How Transformers Learn to Plan via Multi-Token Prediction》J Huang, Z Zhou, R Xia, B Mirzasoleiman… [University of California, Los Angeles & Shanghai Jiao Tong University] (2026)
在规划推理领域,语言模型如何在生成当前词时"预见"未来步骤,是一个悬而未决的难题。过去的标准训练方式——逐词预测下一个词——让模型天然地盯着脚下,而非抬头看路,导致它在需要全局谋划的任务上屡屡失手。
本文的核心洞见是:把"预测多个未来词"重新看作一种梯度解耦装置。由此,浅层预测头将训练信号直接注入第一层注意力,绕开未初始化的深层,使模型得以先锁定终点、再反向追溯路径——这一"倒推推理"机制使规划难题得以解开。
这项工作真正留下的遗产是:首次从优化动力学角度严格证明,训练目标本身可以塑造模型涌现出何种推理回路。它为后来者打开的新门是——通过设计损失函数而非架构,定向诱导可解释的算法行为。但尚未跨过的门槛是:理论仍限于两层简化模型与固定拓扑的星形图,如何推广至更深网络、连续任务与有限时间收敛分析,仍是开放问题。
arxiv.org/abs/2604.11912
机器学习 人工智能 论文 AI创造营