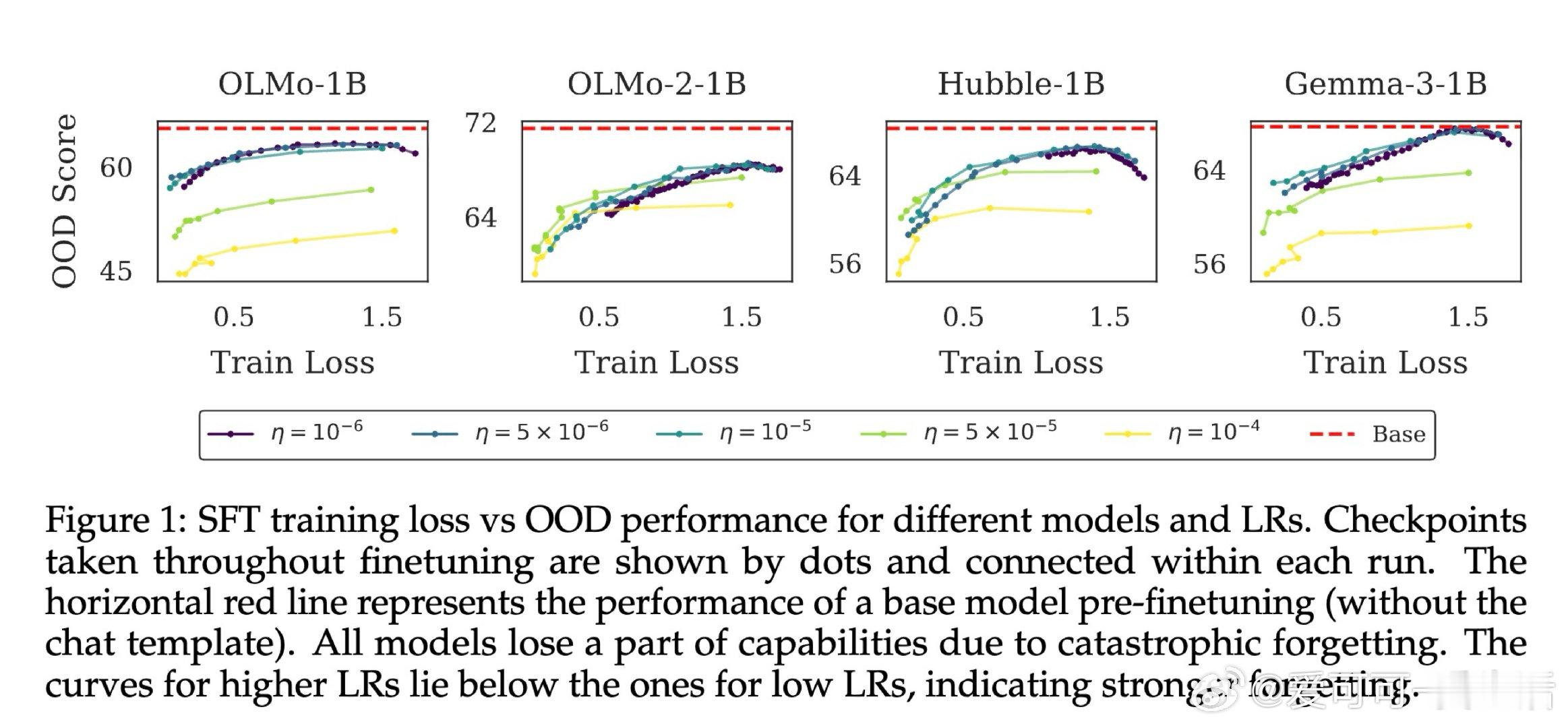
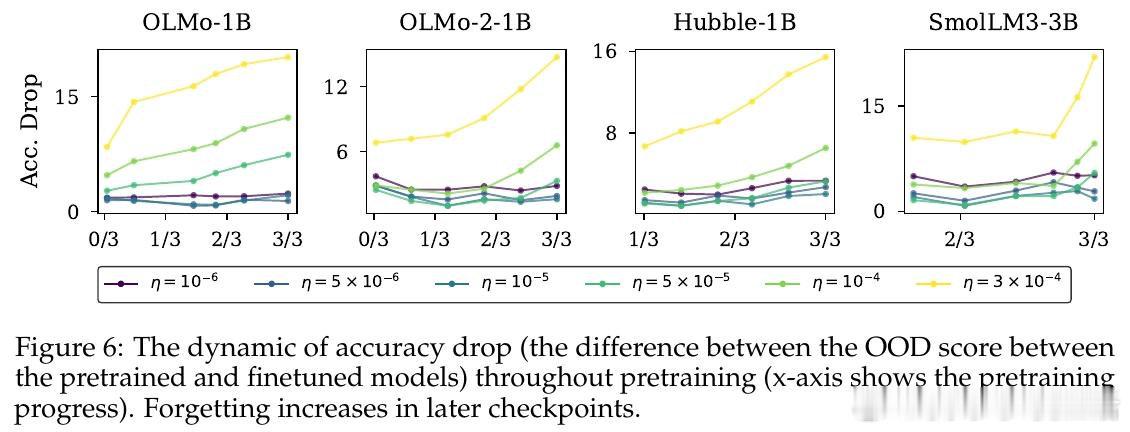
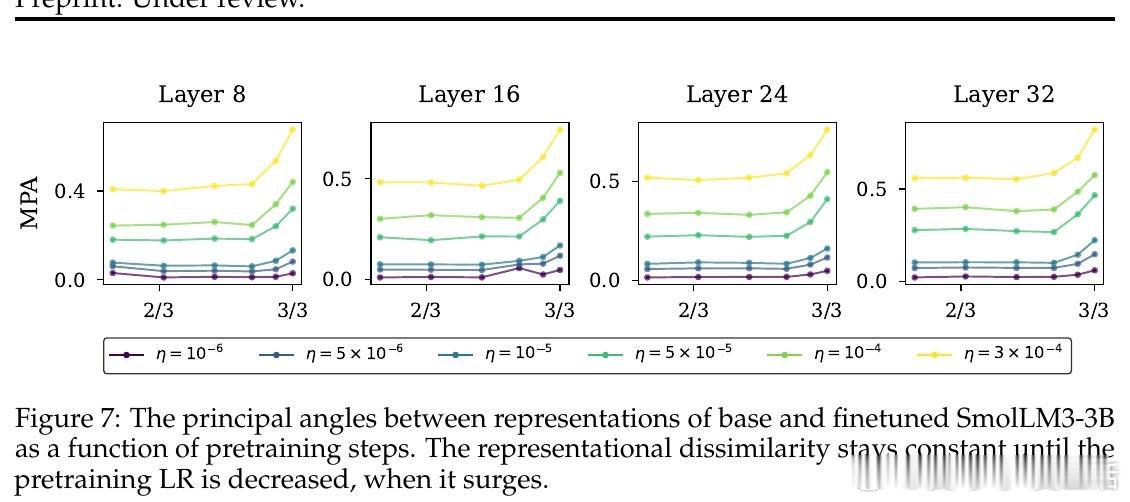
[LG]《(How) Learning Rates Regulate Catastrophic Overtraining》M Rofin, A Varre, N Flammarion [EPFL] (2026)
在LLM微调领域,"灾难性遗忘"随着预训练时长增加而加剧是一个悬而未决的难题。过去的研究将其归因于模型容量限制,本质原因是无法同时拟合预训练与微调两套数据分布。
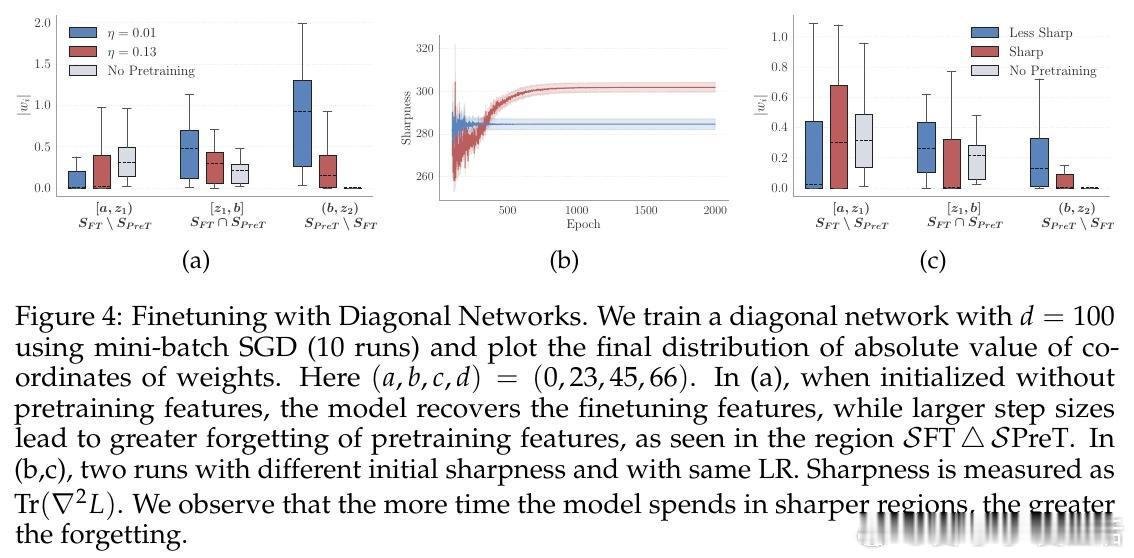
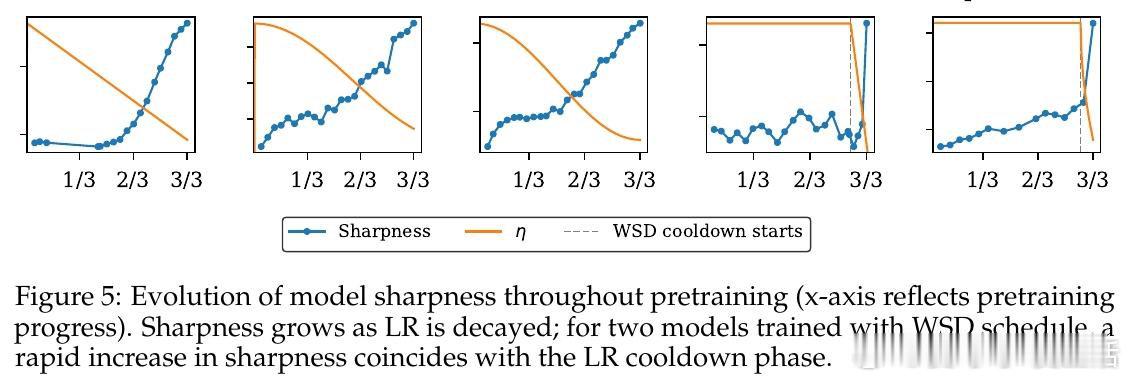
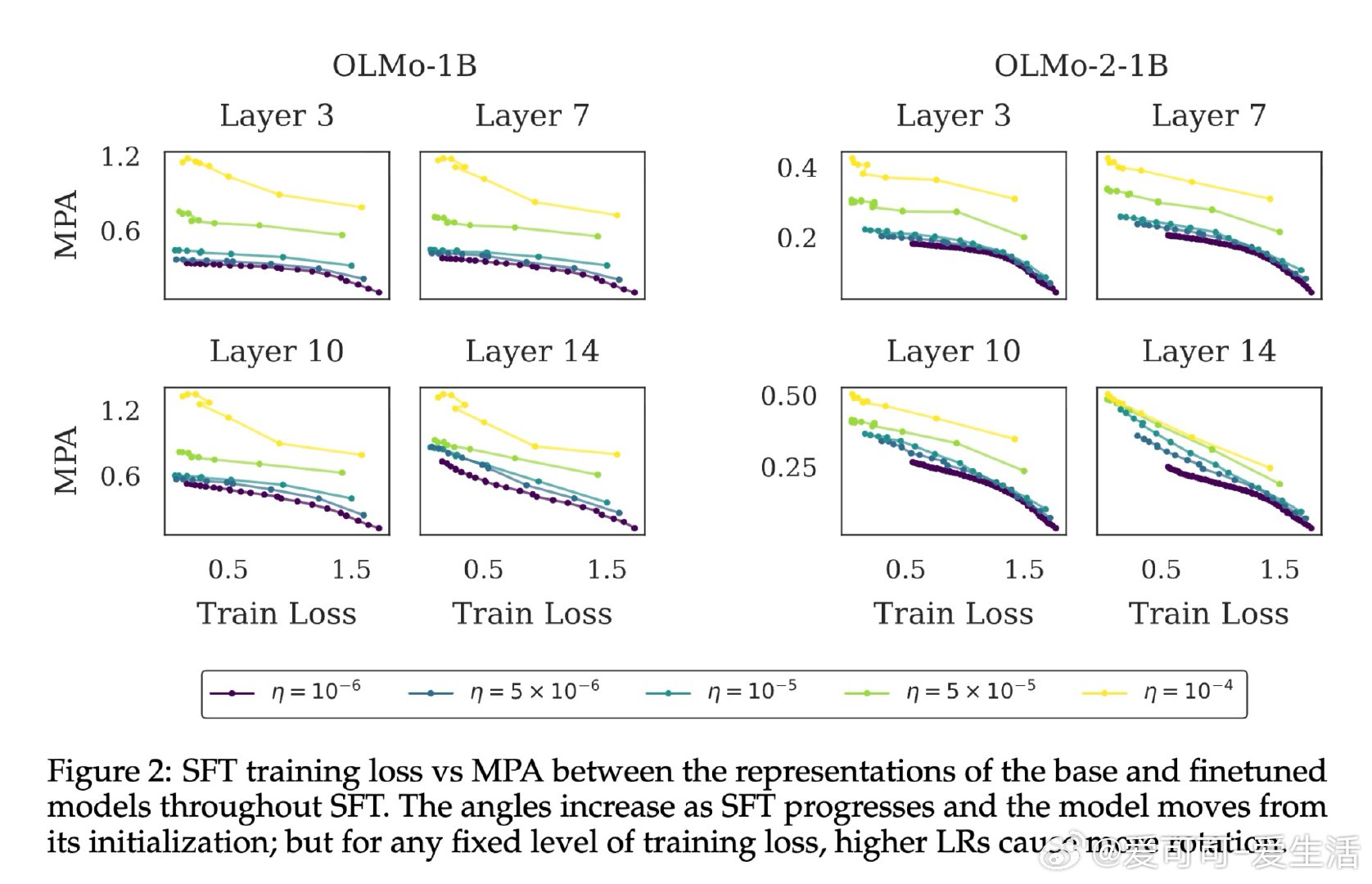
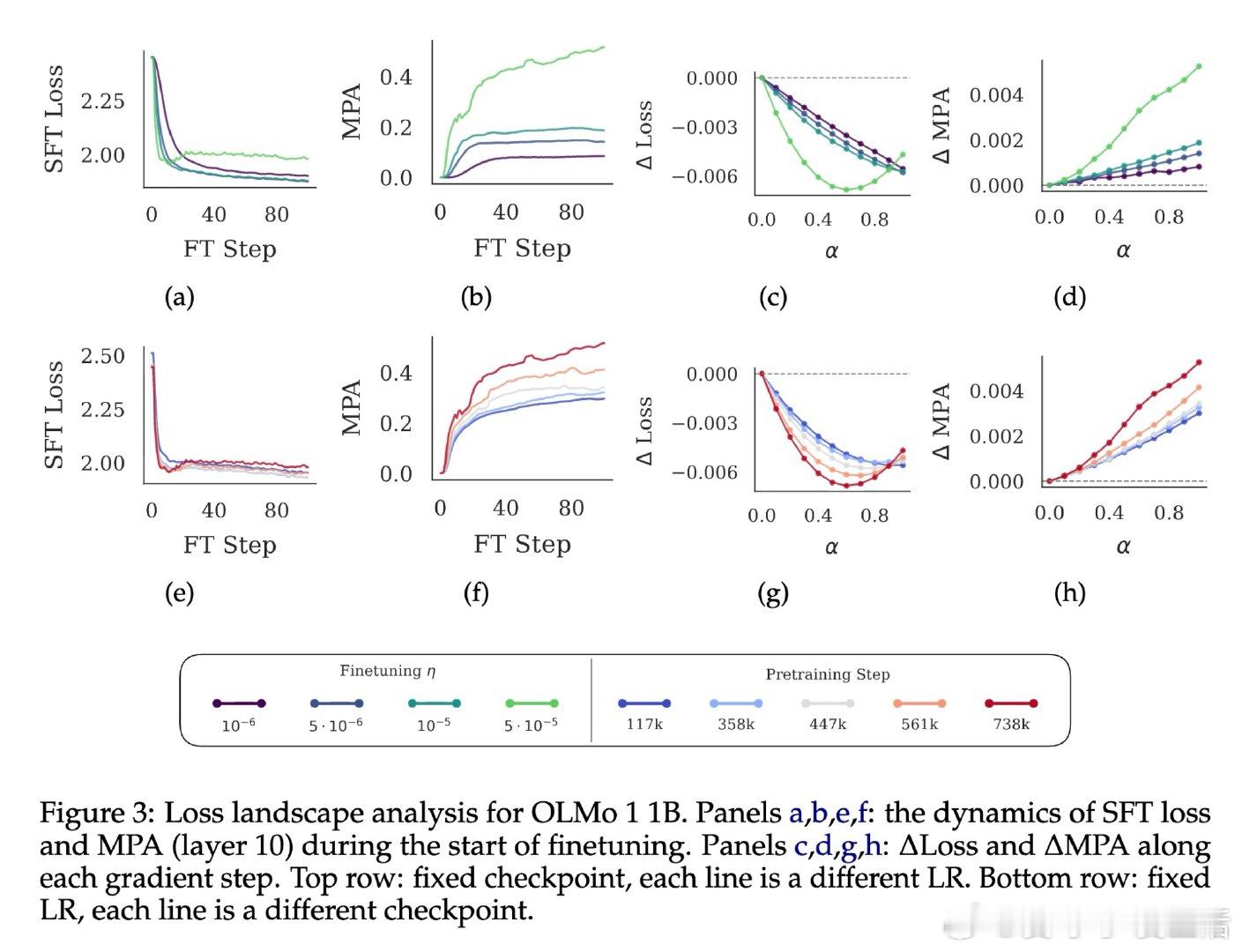
本文的核心洞见是:把学习率看作模型在参数空间中行进路径的隐式调节器,而非单纯的收敛速度旋钮。由此,"预训练学习率衰减→模型锐度上升→微调时特征漂移加剧"这一因果链,使长期悬而未解的过训练机制得以清晰展开。
这项工作真正留下的遗产是:将灾难性过训练的根源从"训了多少token"重新定位到"预训练如何收尾"。它为后来者打开的新门是:通过控制预训练末期的学习率衰减策略(或将衰减推迟至后训练阶段)来主动管理模型锐度,从而在不牺牲预训练能力的前提下完成微调。但尚未跨过的门槛是:实验主要在1-3B参数量模型上进行,LR衰减与锐度之间的因果关系尚缺乏受控重训练实验的直接验证。
arxiv.org/abs/2604.13627
机器学习 人工智能 论文 AI创造营