[LG]《Beyond State Consistency: Behavior Consistency in Text-Based World Models》Y Huang, G Chen, J Yao, L Wang… [Microsoft] (2026)
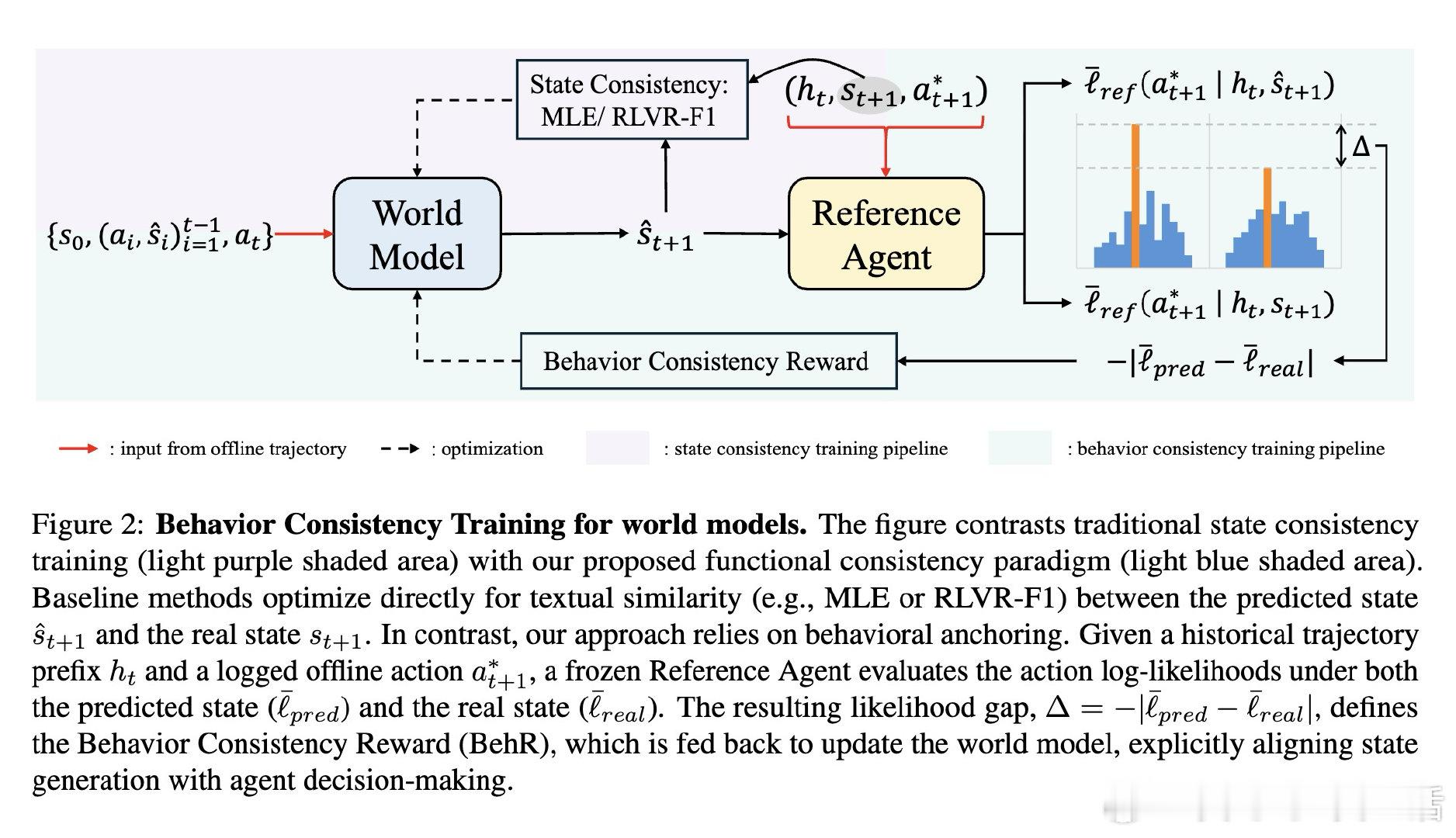
在文本世界模型领域,如何让模拟环境中的智能体行为与真实环境保持一致,是一个悬而未决的难题。过去的方法用词语相似度(BERTScore、EM等)来衡量预测质量,本质原因是把"状态像不像"错当成了"决策对不对"——一个缺少目标商品的页面反而比缺少无关商品的页面得到更高的相似度分,这种"指标倒置"让训练信号系统性失效。
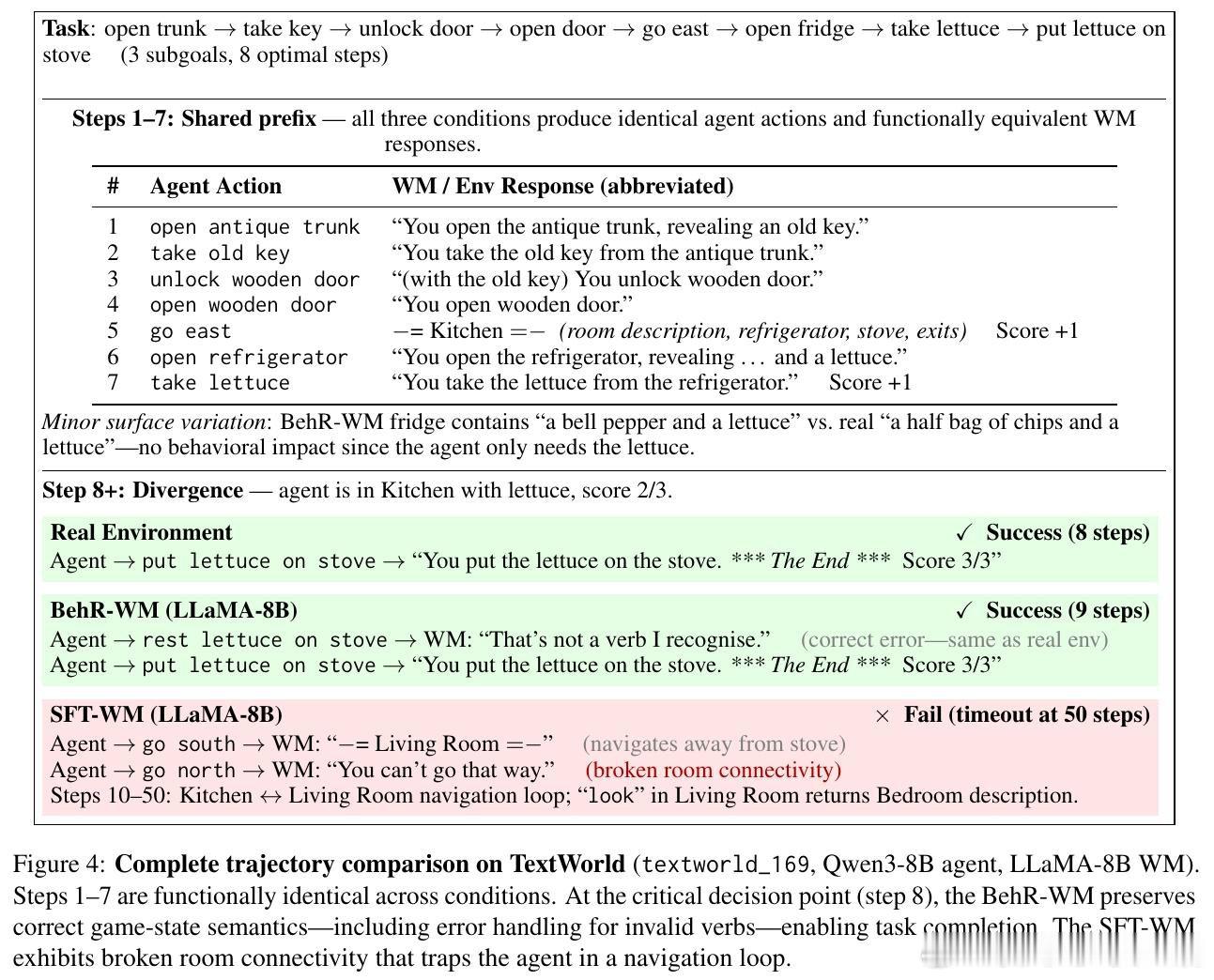
本文的核心洞见是:把世界模型的优化目标从"复现文本"重新看作"保留决策"。由此,行为一致性奖励(BehR)这一关键操作使问题得以解开——用一个冻结的参考智能体,比较预测状态与真实状态下同一动作的对数概率差距,差距越小奖励越高,再通过GRPO强化学习驱动世界模型向决策保真方向收敛。
这项工作真正留下的遗产是:将"功能一致性"确立为文本世界模型的核心评价准则,证明优化目标的选择比优化算法本身更关键。它为后来者打开的新门是:行为对齐的世界模型可作为更可信的离线评估器(弱智能体误报率从42.5%降至9.5%)和规划模拟器的可行基础。但尚未跨过的门槛是:BehR只是单一冻结裁判模型对单条记录动作的代理度量,在多动作竞争激烈、或裁判家族与被评估智能体高度异质的场景下,其泛化边界仍有待系统性验证。
arxiv.org/abs/2604.13824
机器学习 人工智能 论文 AI创造营