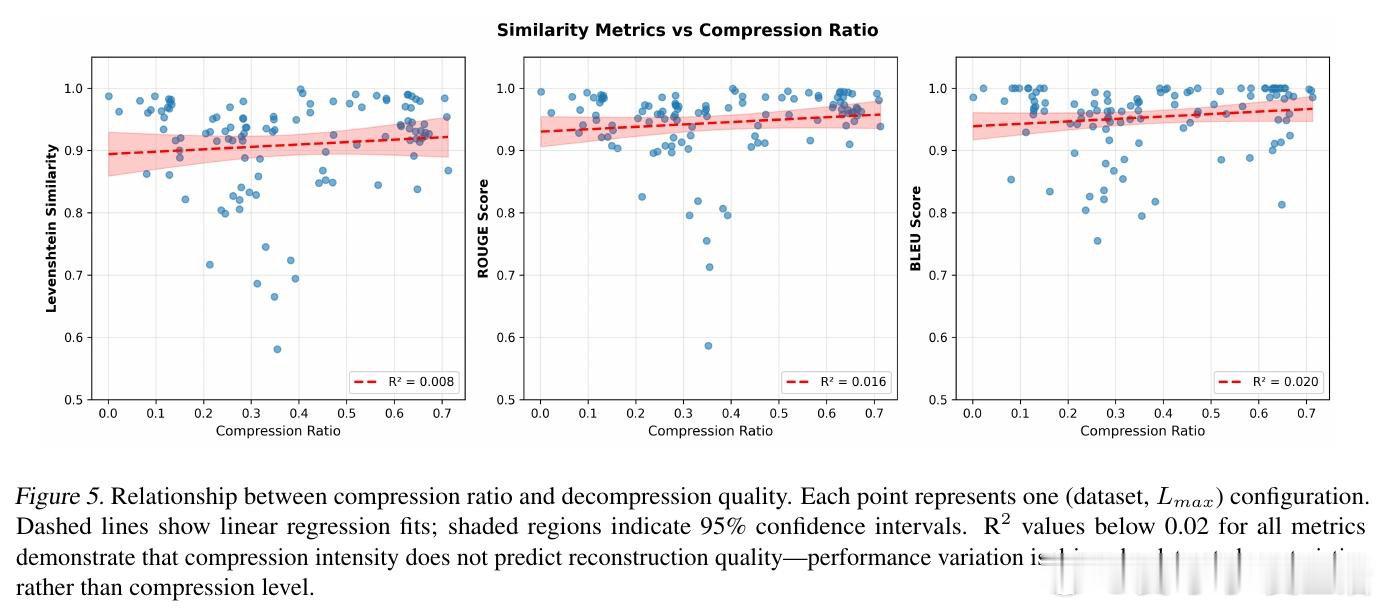
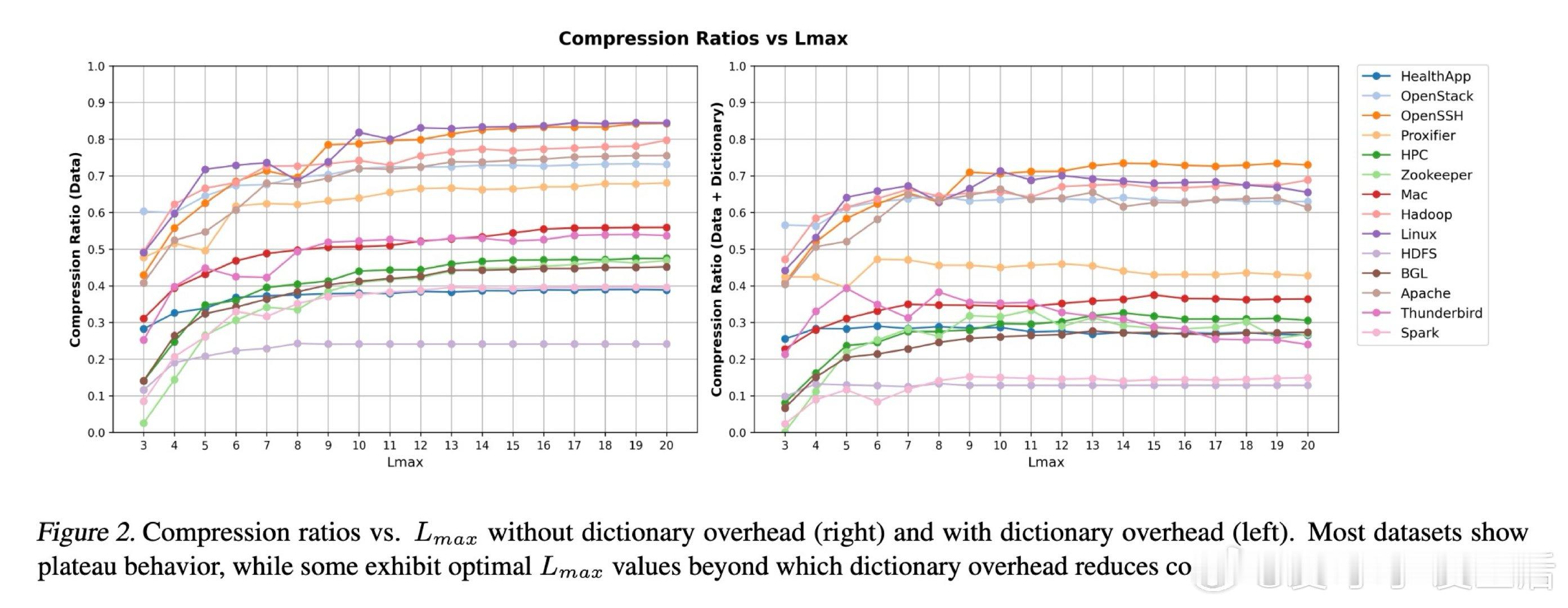
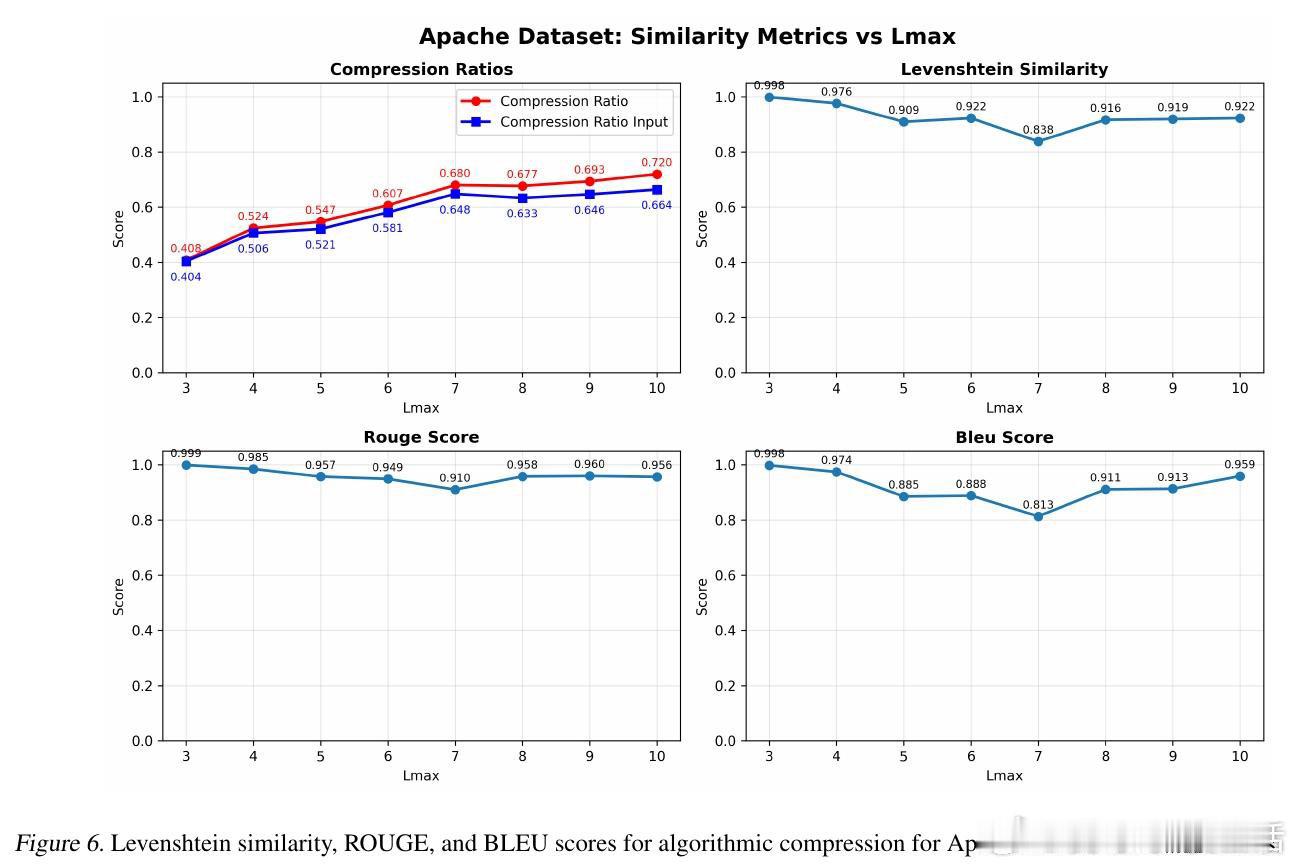
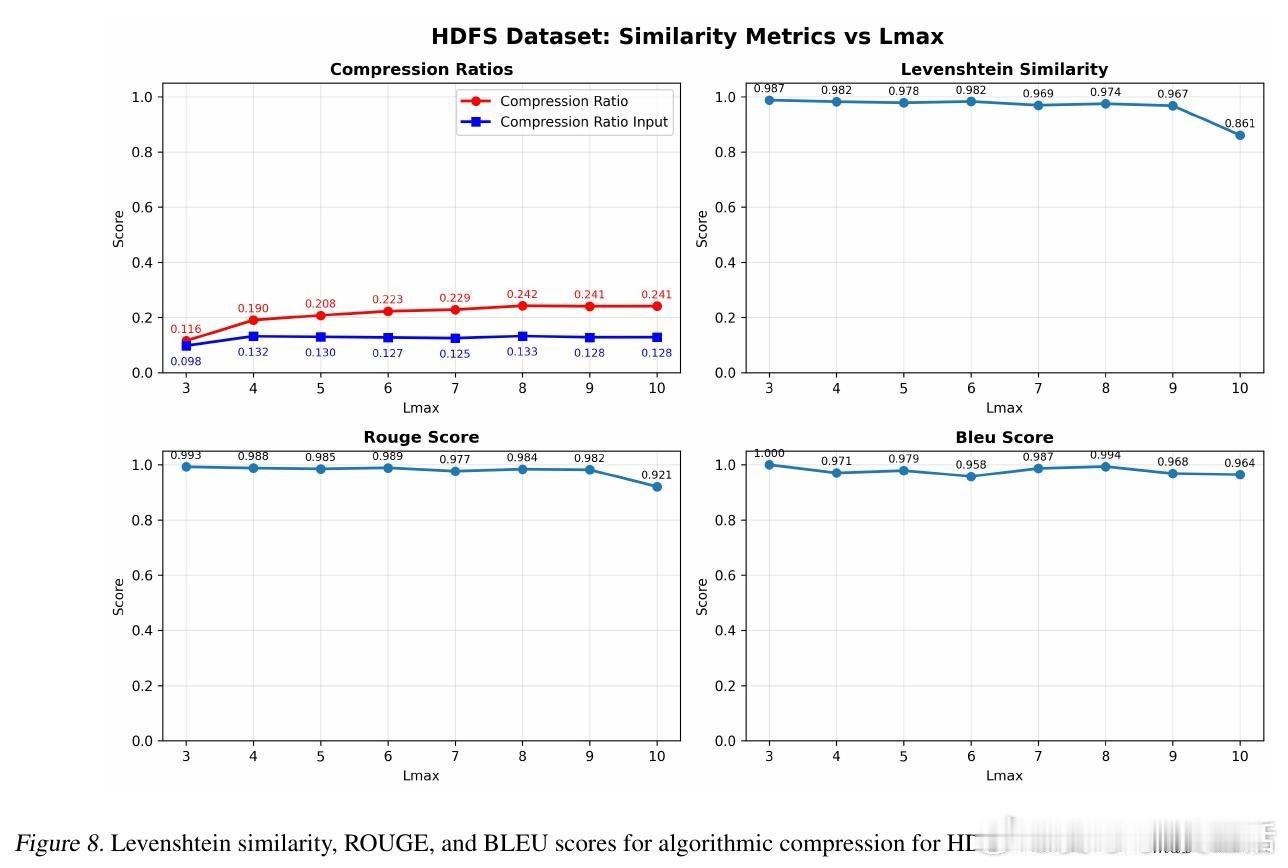
[CL]《Lossless Prompt Compression via Dictionary-Encoding and In-Context Learning: Enabling Cost-Effective LLM Analysis of Repetitive Data》A R d Campos, D Lee, I Kissos, P Paritosh [Amazon.com] (2026)
在企业级日志分析领域,API调用的token成本是一个真实的运营瓶颈——每处理一批重复日志,就要为那些反复出现的时间戳、路径、错误码付出冗余的账单。过去的无损压缩方案受困于一个死结:LLM无法直接理解压缩格式,必须先解压再送入模型,压缩收益因此归零;而现有的meta-token替换方法则要求对模型进行微调,本质原因是传统思路将"压缩"与"理解"视为两个串行阶段。
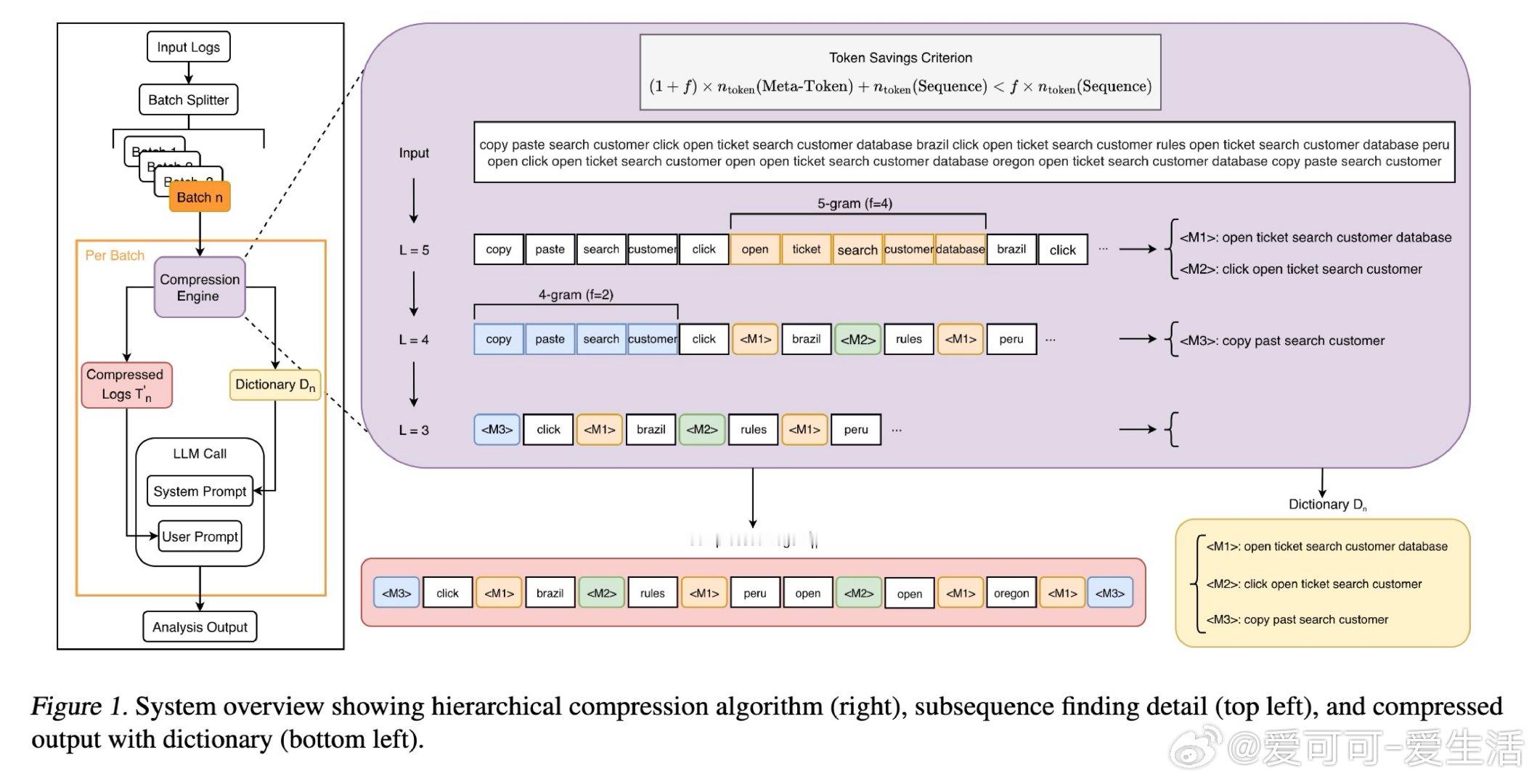
本文的核心洞见是:把压缩字典重新看作一种上下文内的符号约定,而非需要训练才能内化的权重知识。由此,将字典注入系统提示、让LLM在推理时实时查表这一操作,使"压缩与理解同步发生"的闭环得以成立——无需任何模型改动。
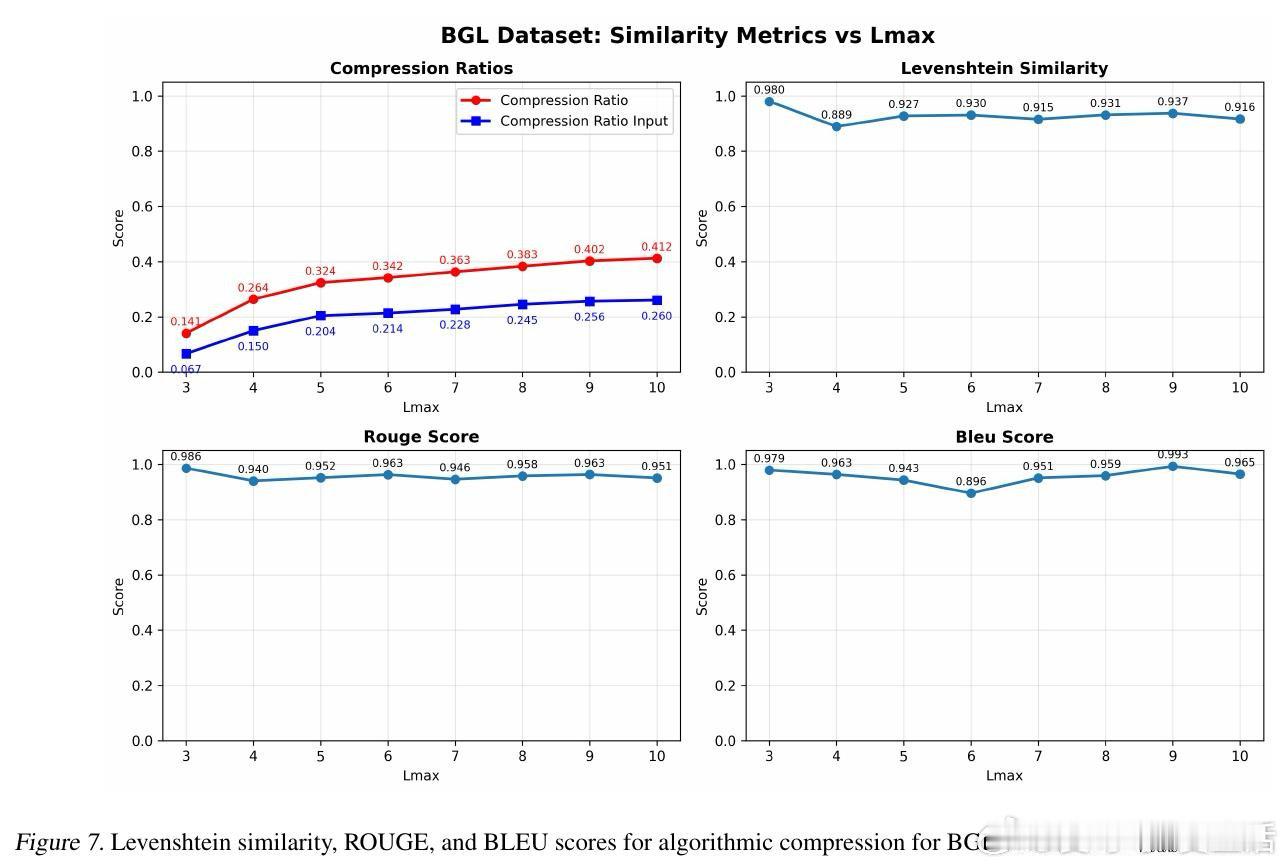
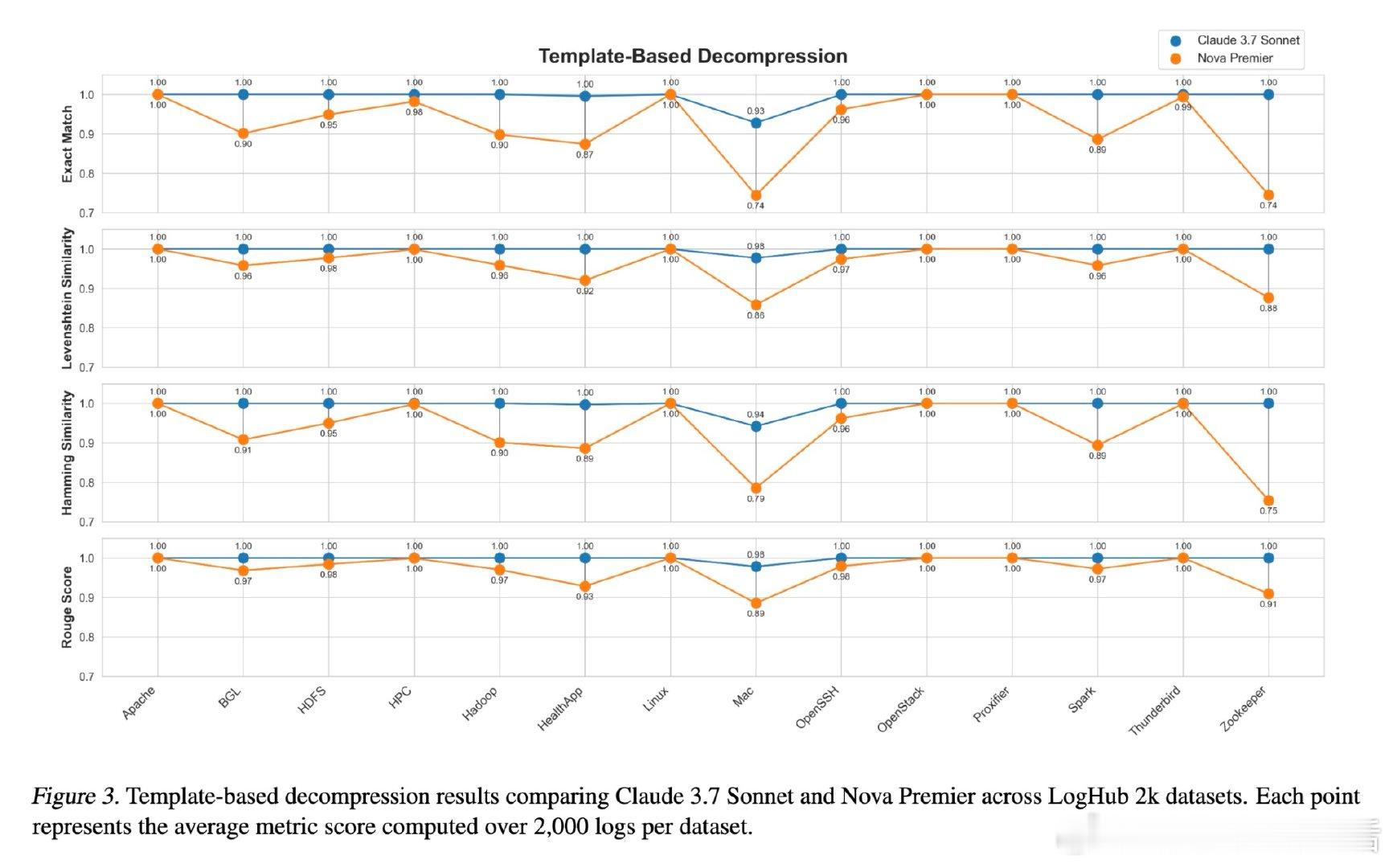
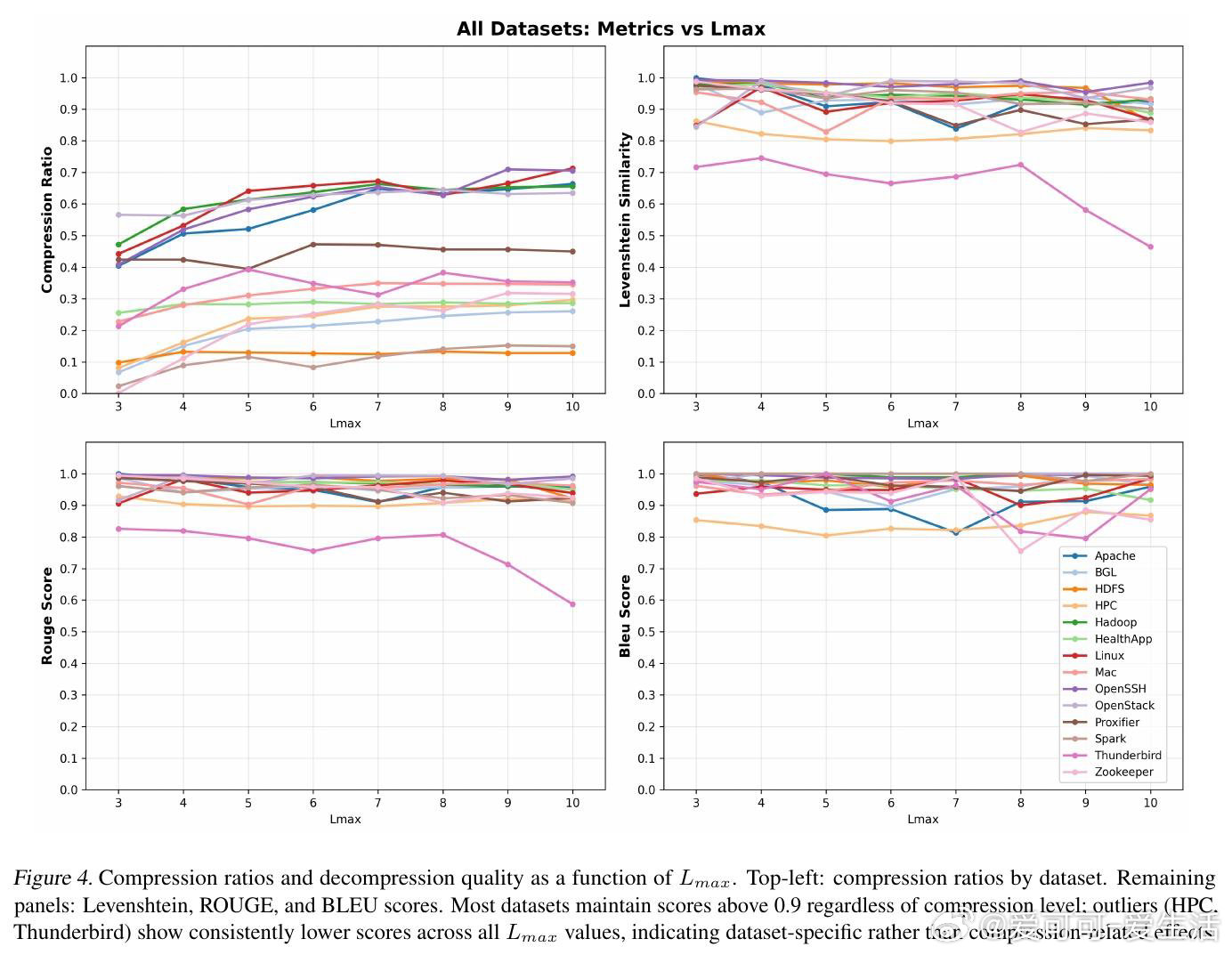
这项工作真正留下的遗产是:证明了LLM的上下文学习能力可以承载一套完整的符号映射系统,为无需微调的无损输入压缩开辟了工程路径。它为后来者打开的新门是:将同样的范式延伸至更广泛的重复性文本域——流程挖掘、模板化报告、结构化金融数据。但尚未跨过的门槛是:当日志内容缺乏自然语言语境(如纯数字序列)时,重建质量显著下滑,字典学习的边界条件仍有待系统性厘清。
arxiv.org/abs/2604.13066
机器学习 人工智能 论文 AI创造营