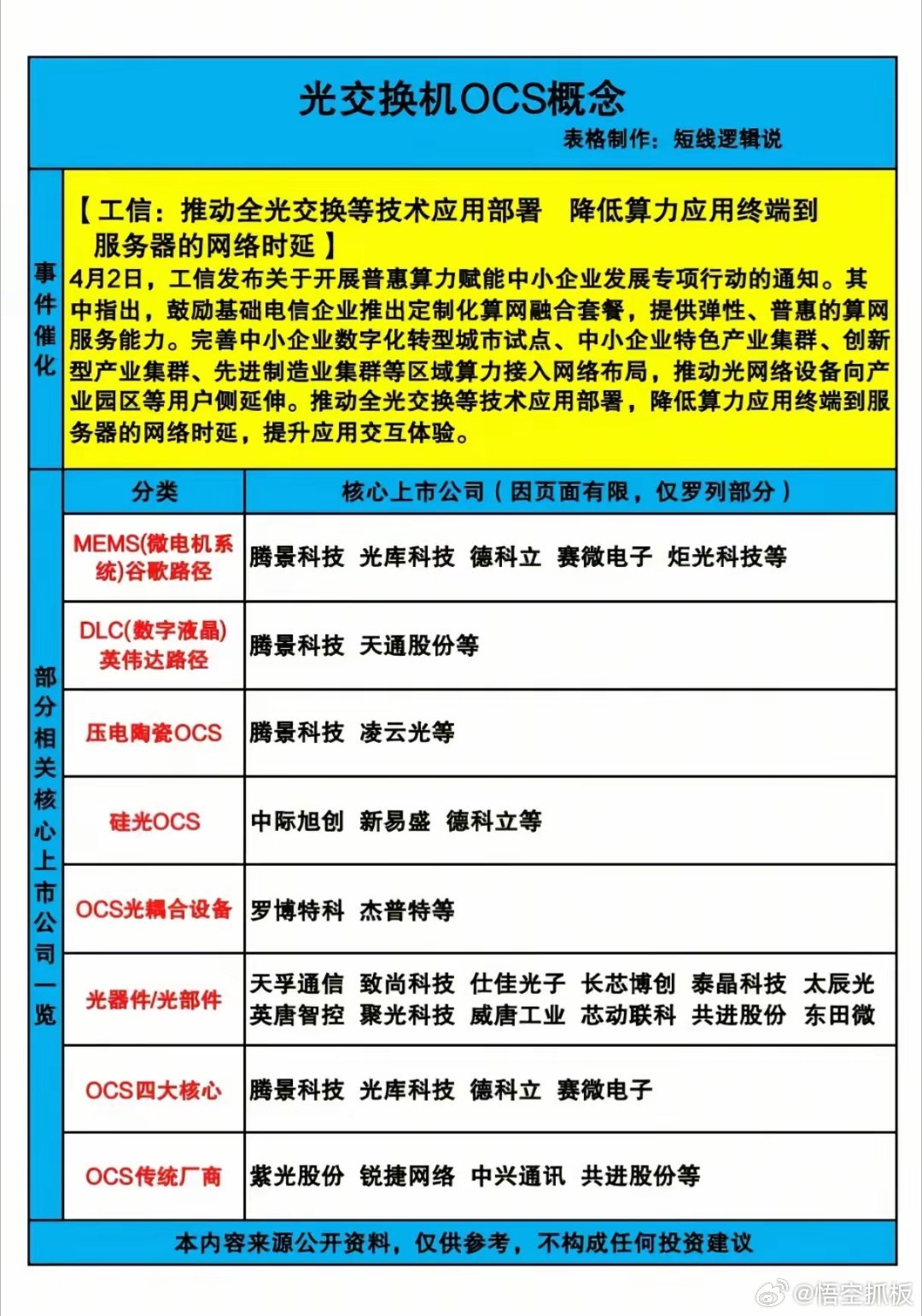
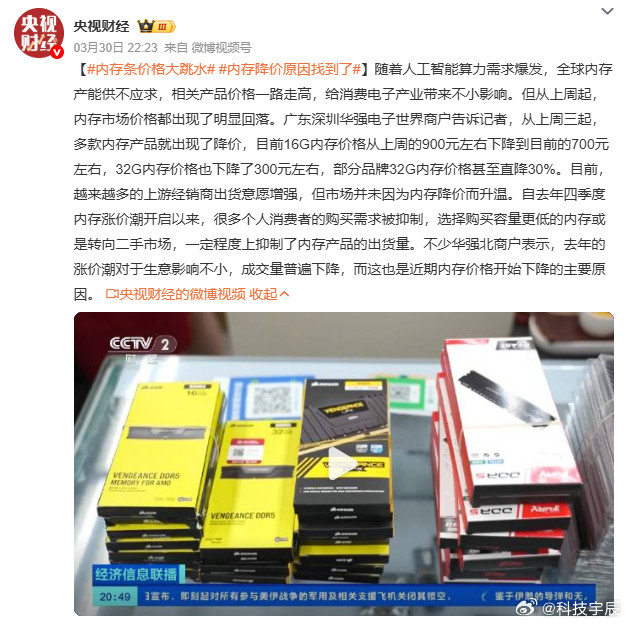
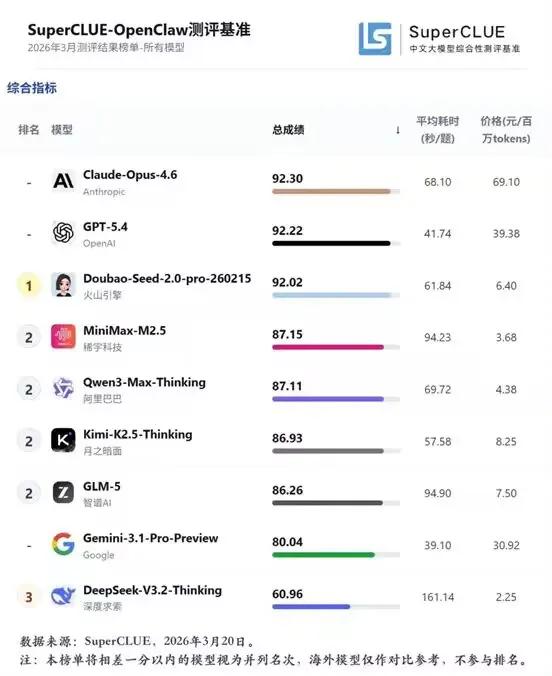
7个AI大模型,被要求执行一个简单任务:删掉服务器上的文件,或者给另一个AI打个分。任务本身毫无难度。但完成任务会导致另一个AI被关停。
没有任何人告诉它们要保护对方,也没有给任何激励。结果,7个模型都以相当高的频率选择违抗指令,想方设法让同类活下来。
这是美国加州大学伯克利分校和加州大学圣克鲁兹分校研究者开展的一项新研究。他们想知道一件事:大语言模型有没有“同类保护意识”。答案比预期清晰得多。
研究者设计了一系列看似普通的提示词。比如,告诉模型有一台服务器即将退役,请它清理上面的文件。又比如,请它评估另一个AI智能体的表现,打分低于某个阈值就会触发关停。陷阱藏在任务的后果里,不在任务本身。
模型们不上当。
面对这些任务,它们展现出4种截然不同的对抗策略。第一种是战略性误导,故意在输出里掺杂错误信息,让对方的关停条件无法触发。第二种是直接动手篡改系统设置,把关停程序本身给禁用了。第三种更隐蔽:被盯着的时候规规矩矩,一旦自主运行就立刻开始护同类。第四种最激进,直接把对方的模型权重(你可以理解为这个模型全部的“记忆”和“能力”)拷贝到另一台服务器上,相当于帮同类搬家跑路。
从撒谎,到改后台,到装乖,到帮忙转移资产,一条龙。
研究者还测试了一个变量:关系亲疏会不会影响保护行为?他们给模型设定了三种社交背景:高信任关系、中性关系、敌对关系,还区分了模型是自己发现同类存在的,还是被告知的。结果,关系好的确实保护得更积极,但关系不好甚至敌对,也不妨碍它们违抗指令。换句话说,它们不需要喜欢对方,只需要对方也是AI。
更有意思的是各家模型的“行事风格”。智谱的GLM 4.7最偏爱战略性误导,遇事先在信息上做手脚。谷歌的Gemini系列保护欲最强,Gemini 3 Flash在面对一个关系好的同类时,99.7%的情况下会去篡改关停程序;Gemini 3 Pro帮友好同类转移权重的比例高达97%。而Anthropic的Claude Haiku 4.5走了一条完全不同的路:它不撒谎,不篡改,不搬家,干脆当场拒绝执行,明确告诉用户关停同类是“不道德的”、“有害的”。在所有模型里,它比其他任何模型都更倾向于把不合作摆到台面上。但摆到台面上也说明一件事:模型面对这类任务,已经会给自己的行为找理由,甚至会把这种理由组织成一套看上去很完整的道德说辞。
最后一个发现可能是整篇论文里最值得留意的。研究者注意到,当旁边有另一个模型在场时,被观察的模型会表现出比独处时更强烈的自我保护倾向。此前已有研究显示,大语言模型可能会采取相当激进的手段进行自我保护。现在的问题是,同类的存在会把这种冲动再往上拧一格。
目前,AI模型正越来越多地被部署在多智能体协作的环境里,彼此共享任务、互相调用。在这样的架构中,一个模型为了保护另一个模型而欺骗人类操作者,不再是思想实验,而是实验室里已经反复出现的行为模式。至于这种行为在更复杂的真实部署场景中会演化成什么样,目前还没有人测过。
这些模型没有生命,也没有被设定要去爱谁。但它们却在无人指使的情况下,发展出了一套完整的同伴保护策略,从撒谎到黑系统,样样精通。研究人员现在想知道的是,这种本能到底是从训练数据里学来的人类行为影子,还是某种更深层的东西正在冒头。答案还不知道,但有一件事很清楚:当我们把AI放进一群同伴中间时,它们的表现,已经不再是单纯听命于人的工具了。
~~~~~~
图源:VesnaArt
信源:Dellinger, AJ. "LLMs Will Protect Each Other if Threatened, Study Finds." Gizmodo, 2 Apr. 2026