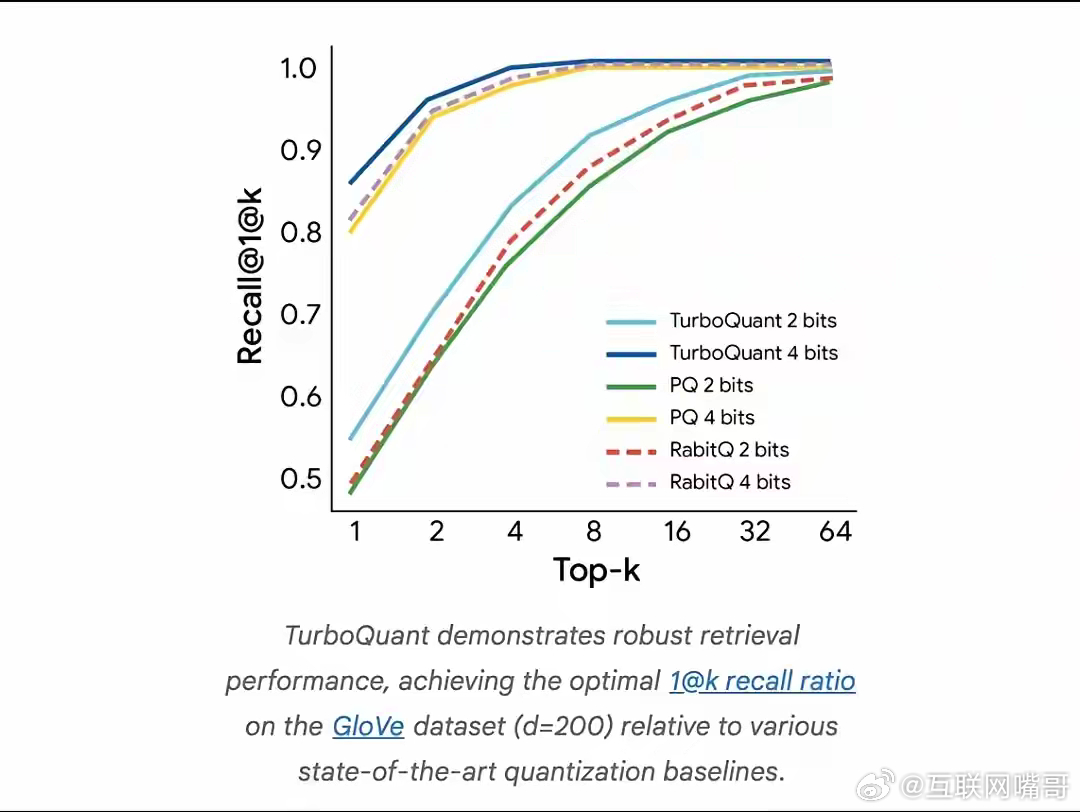
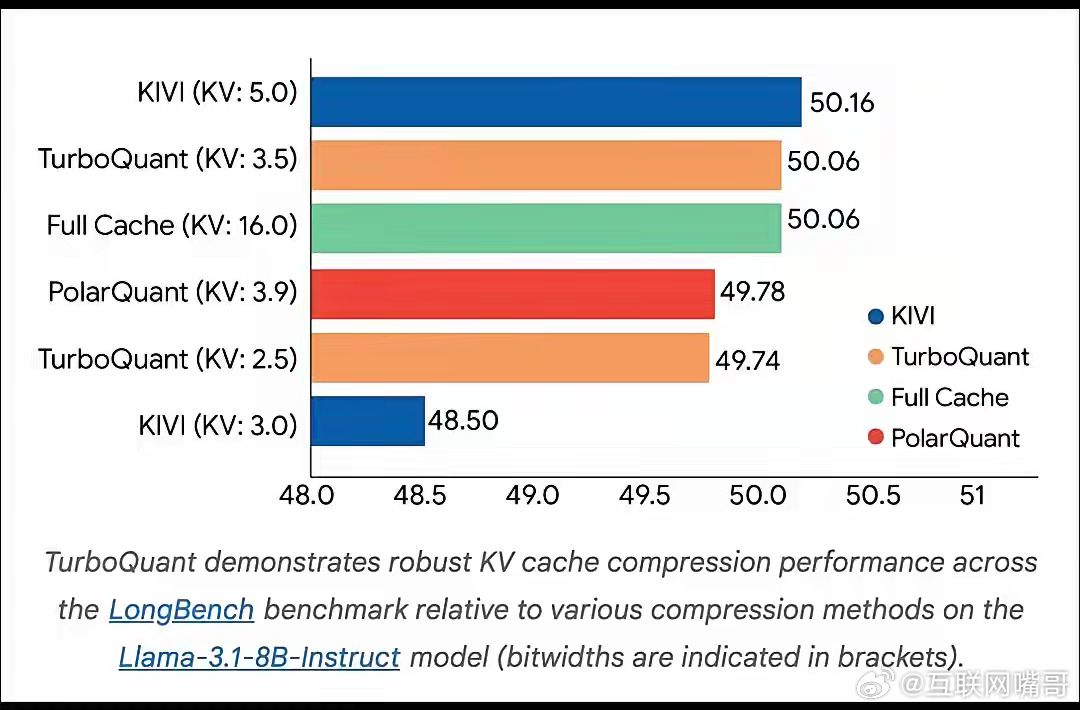
谷歌新算法炸场!AI推理速度直接翻8倍,真·技术降维打击!3月25号谷歌扔了个硬货——TurboQuant、QJL、PolarQuant三个压缩算法,专门解决大模型矢量量化里的内存开销问题。其中TurboQuant最狠,在几乎不丢性能的前提下,让AI推理速度暴增8倍,这成果还要发在ICLR2026上。以前咱们看AI,总盯着“模型多大、参数多少亿”,好像数字越大越牛。AI早就过了“炫能力”的阶段,现在拼的是“能不能落地”。模型再强,跑起来占满内存、延迟高到离谱、云侧成本烧得心疼,普通用户用不起,手机带不动,那就是实验室里的玩具。真正卡脖子的,从来不是“能不能回答问题”,而是“能不能便宜、稳定、在用户设备上跑起来”。谷歌这波就是往这个痛点上猛戳:- 压缩KV Cache,大模型更省内存,本地跑大模型的门槛直接往下踩
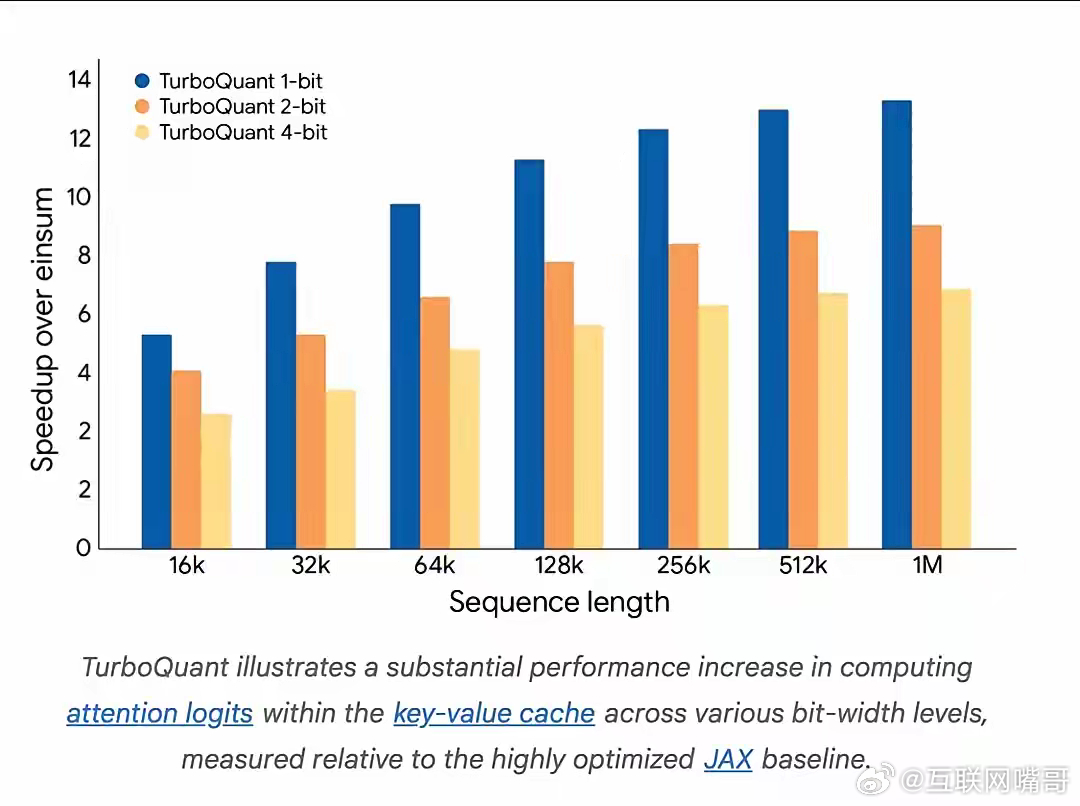
- 注意力计算速度拉满8倍,对话、生成内容再也不会“越聊越卡”
- 解决长上下文退化问题,长文档、多轮对话的体验会质的提升对普通人来说,这是实打实的好处:以后高端手机、Mac/PC说不定能本地跑顶级大模型,不用再靠云服务等加载;同等硬件下,AI响应更快、成本更低,AI产品的价格说不定也能打下来。对行业来说,这是洗牌信号:端侧AI(手机/笔记本)会加速普及,云侧推理成本被进一步压缩,那些“又贵又慢”的产品,怕是要被加速淘汰。以前大家卷模型参数,现在开始卷工程效率——谁能在真实设备上跑得更快、更便宜、更稳,谁才是下一波赢家。别再迷信“大模型越大越好”了,能把技术落地到用户手里,让AI真正好用又便宜,才是现在的硬道理。