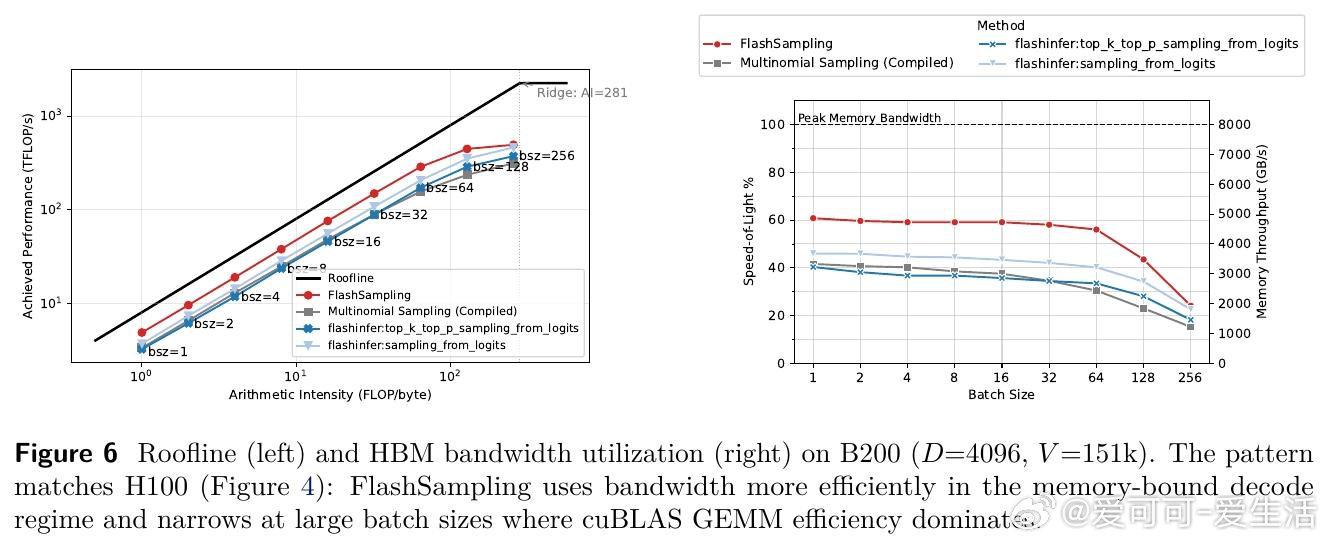
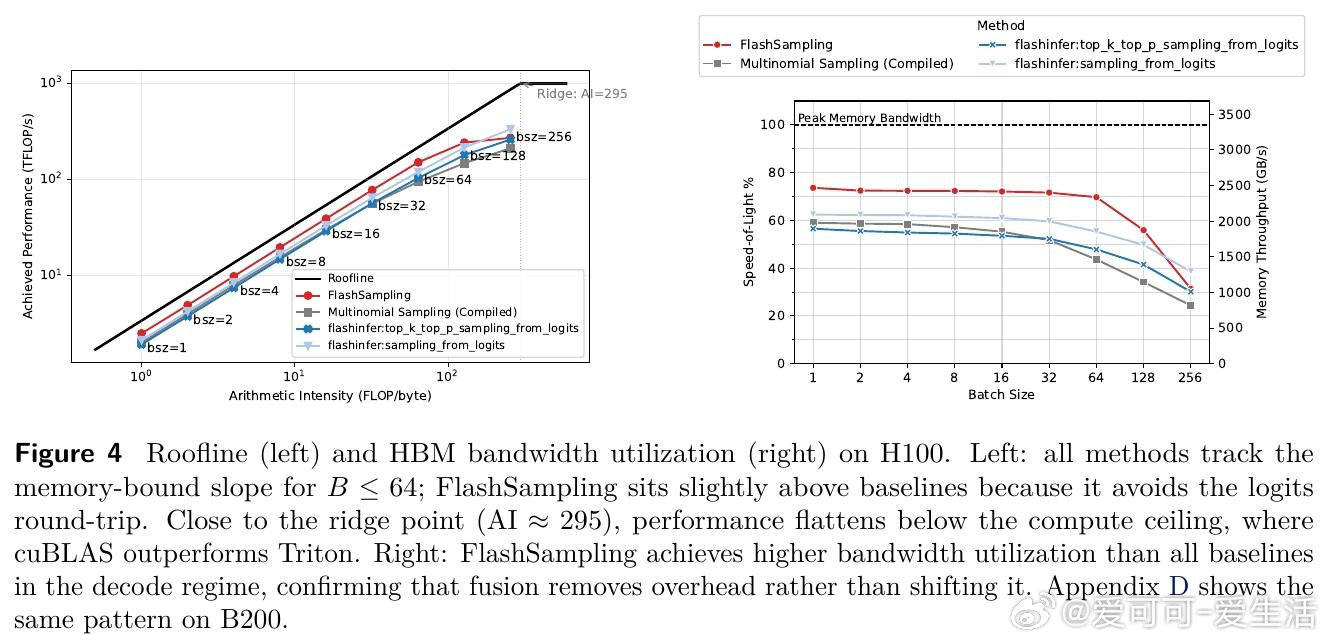
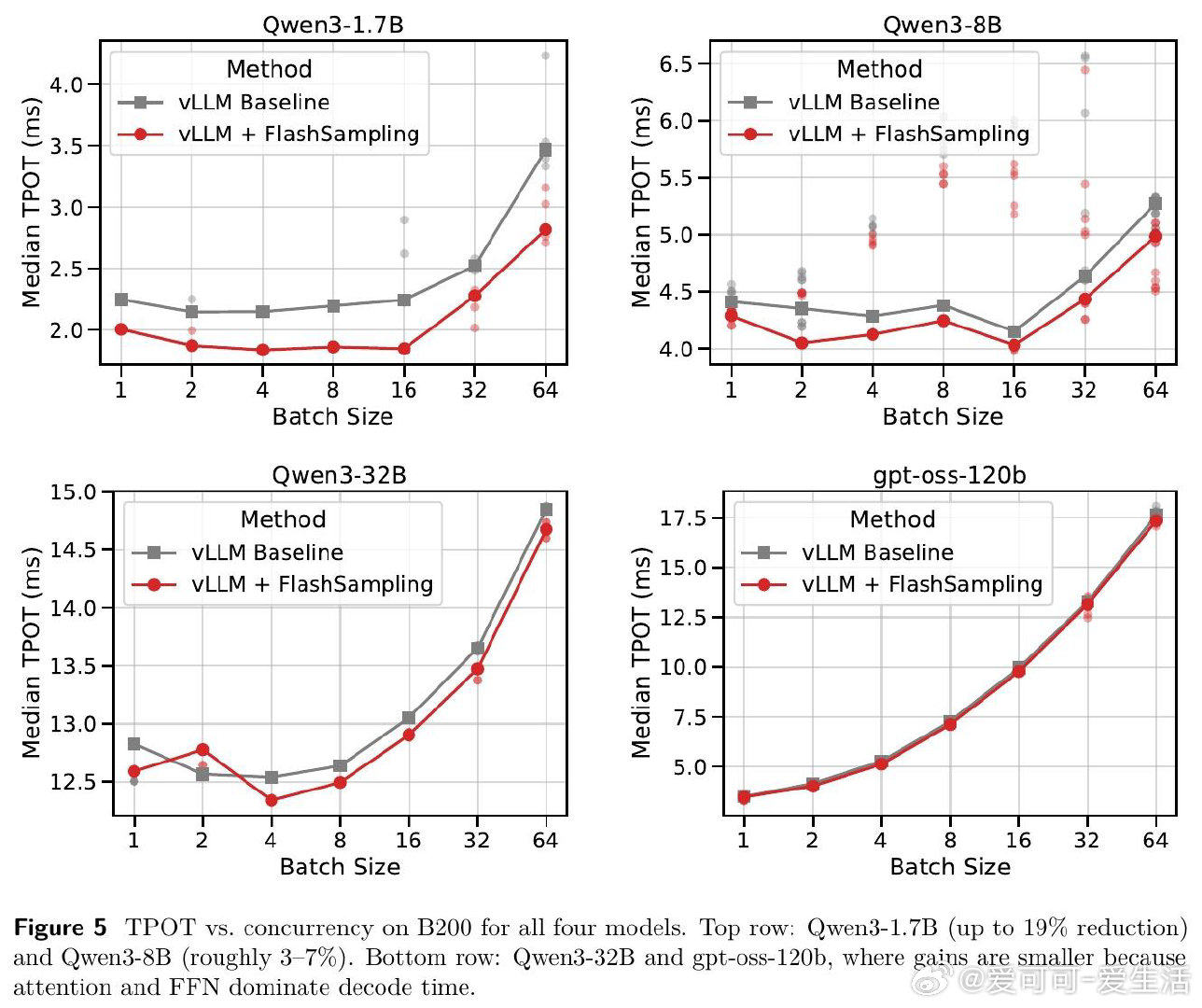
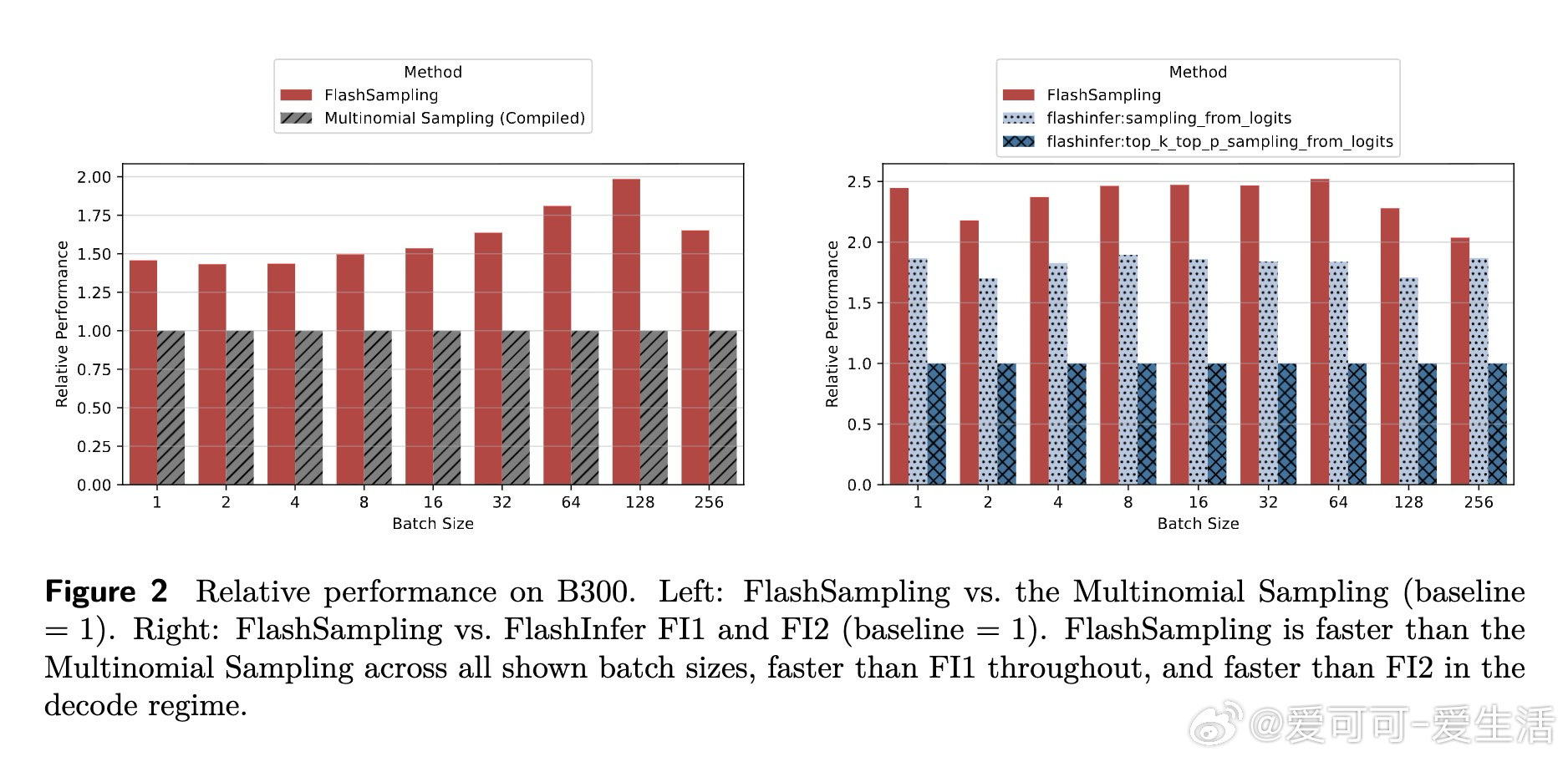
[LG]《FlashSampling: Fast and Memory-Efficient Exact Sampling》T Ruiz, Z Qin, Y Zhang, X Shen… [LMU Munich & FlashSampling & Princeton University] (2026)
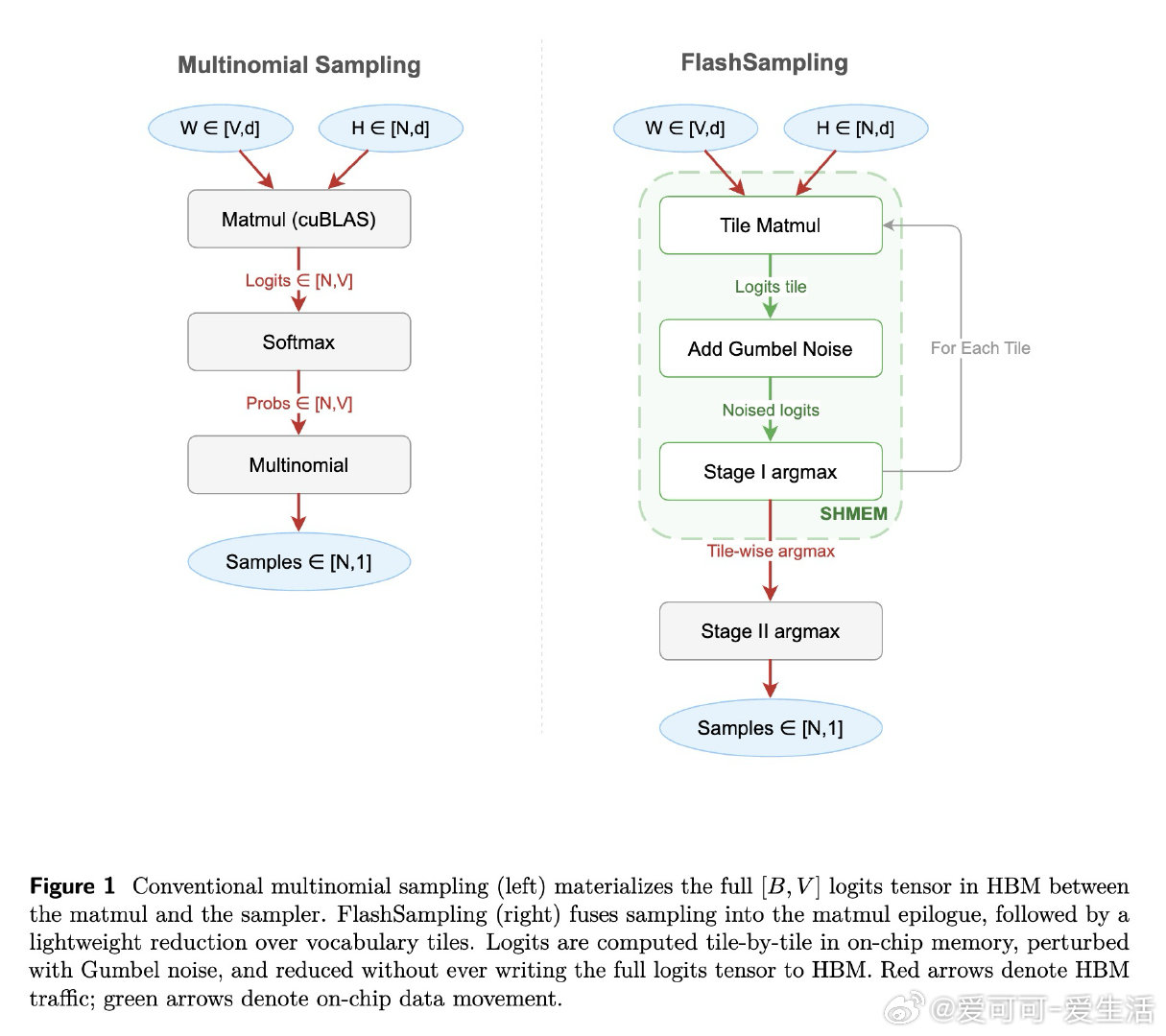
在大词表自回归解码场景中,从语言模型头部采样是一个反复触发的内循环操作。传统流程将完整的logits张量写入显存再读回,这一来回本不必要——根本症结在于:人们误以为"采样"必须先算softmax,而实际上只需找到噪声扰动后的最大值下标。
本文的核心洞见是:把"从分类分布采样"重新看作"对加了Gumbel噪声的logits求argmax"。由此,将噪声扰动与argmax规约嵌入矩阵乘法的epilogue这一关键操作使问题得以解开:logits逐块在片上计算、就地扰动、仅保留每块的局部最大值,最终只做一次轻量归约,完整logits张量从不落盘,采样从后处理变成矩阵乘的尾声。
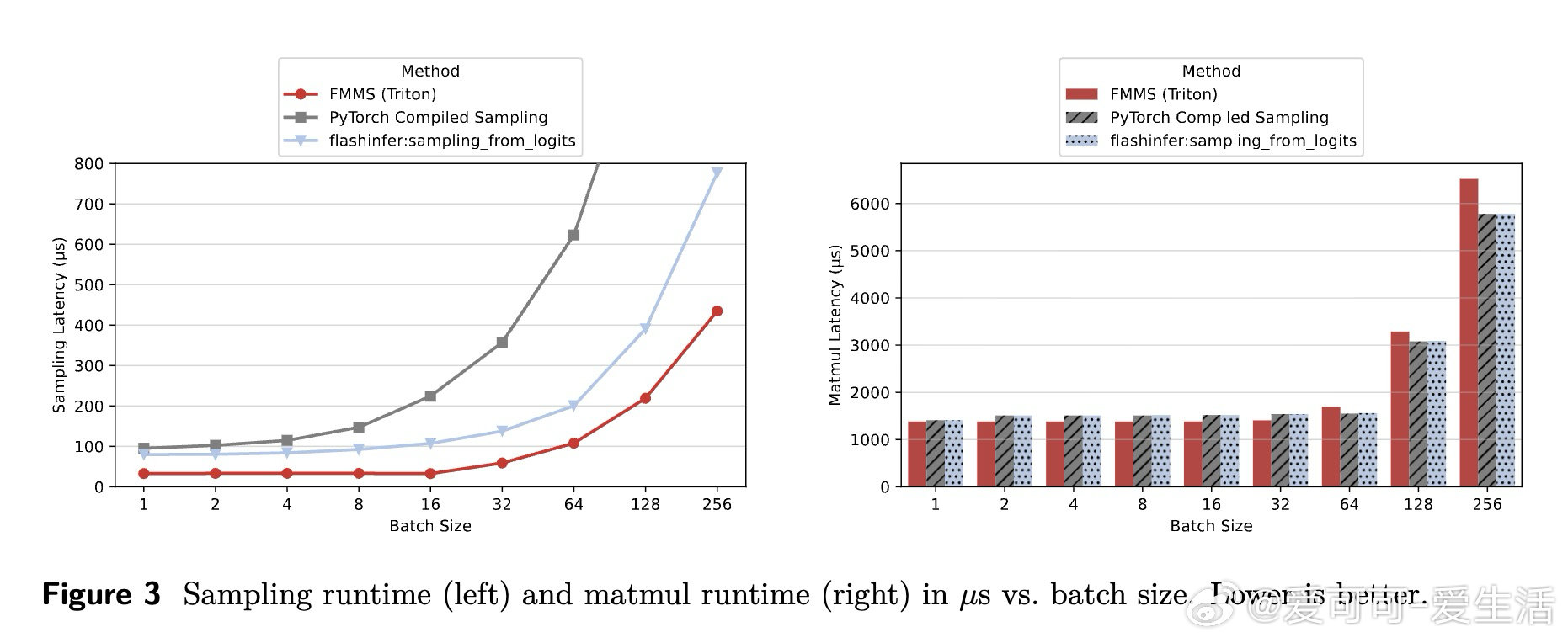
这项工作真正留下的遗产是:证明了算法正确性与IO效率可以同时保全——无近似、无近似分布,且在vLLM端到端实验中实现最高19%的每token延迟压缩。它为后来者打开的新门是将FlashAttention式"避免中间张量落盘"的范式扩展至推理时采样这一新领域。但尚未跨过的门槛是:nucleus sampling等依赖全局softmax排序的截断策略尚未深度融合,且Triton实现在大批量下的GEMM效率仍逊于cuBLAS,限制了其在计算密集场景中的适用性。
arxiv.org/abs/2603.15854
机器学习 人工智能 论文 AI创造营